.NET备份博客园随笔分类文章
2016-10-13 14:58
246 查看
之前用.NET做网页采集实现采用正则表达式去匹配解析,比较繁琐,花费时间较多,若是Html复杂的话真是欲哭无泪。
很早就听过包HtmlAgilityPack,其是在.NET下用XPath来解析的HTML的一个类库(包)。但是一直没时间尝试,简单了解了下HtmlAgilityPack的API后,发现真是HTML解析利器,于是花些时间做一个例子记录下。
本次是以下载博客园随笔分类文章为例,采用两部分实现,第一部分是将采集到的文章放到集合变量中,第二部分是通过操作集合变量将文章下载到本地,
这样做效率较低,因为可以直接边采集文章边下载。暂时没有考虑效率问题,仅仅只是实现功能。下面简单阐述下。
获取随笔分类
根据输入的博客名取得对应的随笔分类。
View Code
演示效果
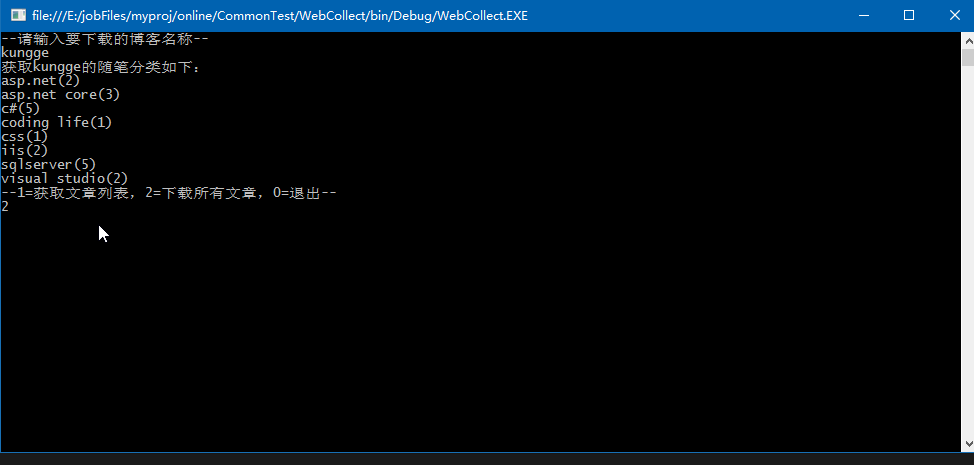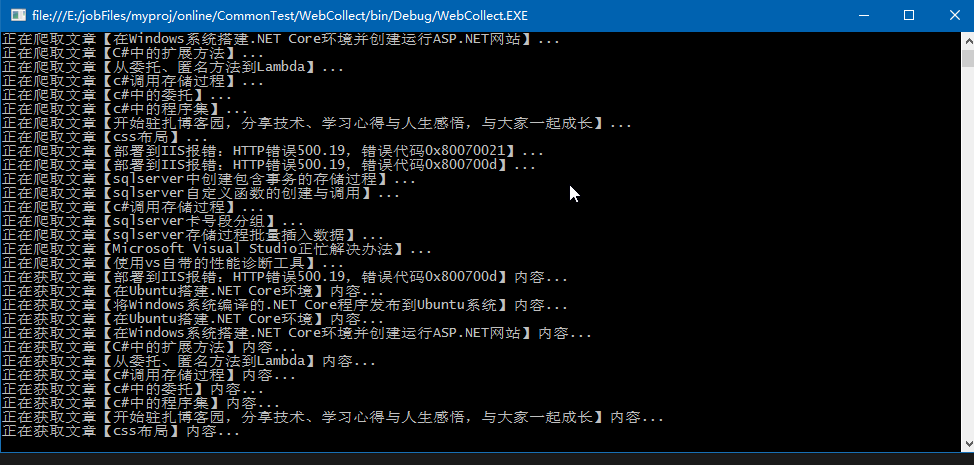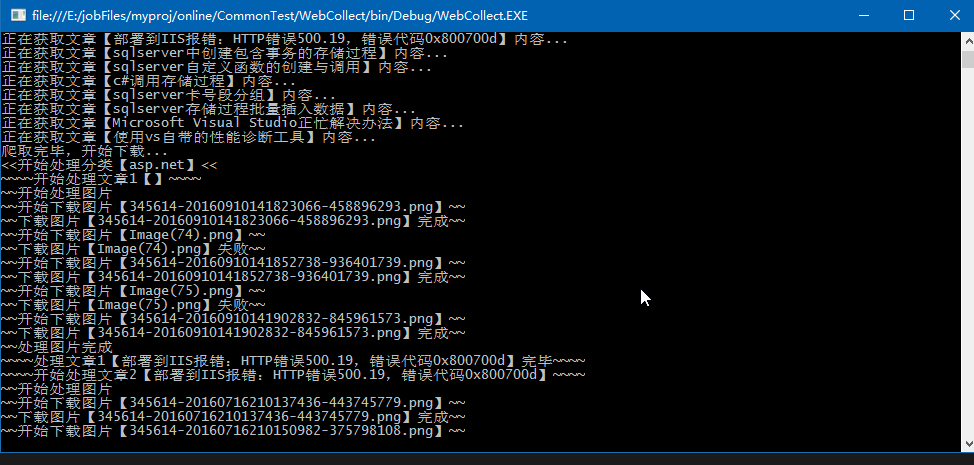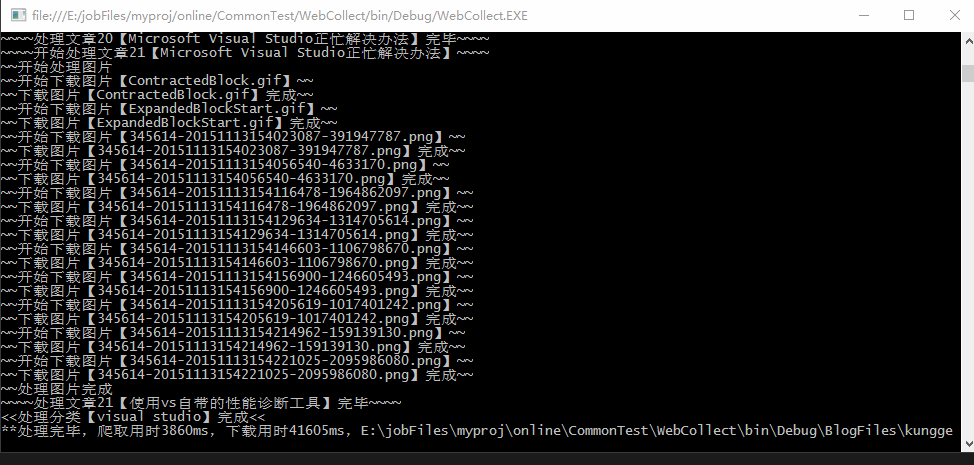
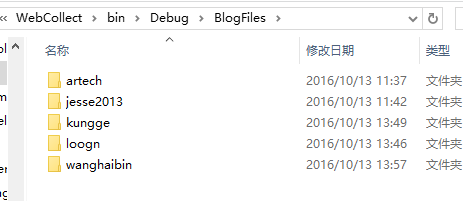
文件存储在项目bin目录下,一个用户一个文件夹
.png)
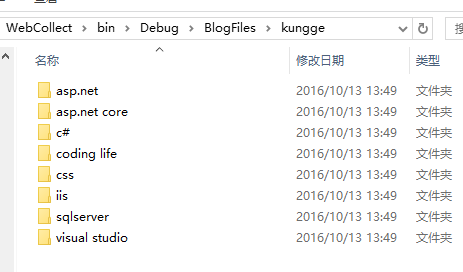
按随笔分类生成不同的文件夹
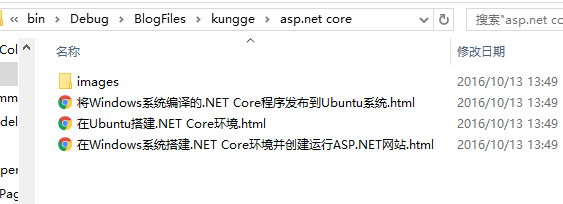
生成.html文件,一个分类的所有图片都存在该分类下的images下。
.png)
完整源码放在github下,https://github.com/kungge/CommonTest/tree/dev/WebCollect
欢迎指出程序bug,提出优化意见,(●'◡'●)
很早就听过包HtmlAgilityPack,其是在.NET下用XPath来解析的HTML的一个类库(包)。但是一直没时间尝试,简单了解了下HtmlAgilityPack的API后,发现真是HTML解析利器,于是花些时间做一个例子记录下。
本次是以下载博客园随笔分类文章为例,采用两部分实现,第一部分是将采集到的文章放到集合变量中,第二部分是通过操作集合变量将文章下载到本地,
这样做效率较低,因为可以直接边采集文章边下载。暂时没有考虑效率问题,仅仅只是实现功能。下面简单阐述下。
获取随笔分类
根据输入的博客名取得对应的随笔分类。
var types = GettBlogTypeList(uname);
long time1 = 0;
long time2 = 0;
long timeDownload = 0;
Console.WriteLine("正在爬取,请耐心等待..." );
var blogList = GetBlogsByType(types,out time1);
var blogDetailList = GetBlogDetail(blogList,out time2);
Console.WriteLine("爬取完毕,开始下载..." );
string filePath=DowanloadBlog(blogDetailList, uname,out timeDownload);
Console.WriteLine("**处理完毕,爬取用时{0}ms,下载用时{1}ms,{2}" , time1+time2, timeDownload, filePath);
handlerRight = false;View Code
演示效果
文件存储在项目bin目录下,一个用户一个文件夹
按随笔分类生成不同的文件夹
生成.html文件,一个分类的所有图片都存在该分类下的images下。
完整源码放在github下,https://github.com/kungge/CommonTest/tree/dev/WebCollect
欢迎指出程序bug,提出优化意见,(●'◡'●)

相关文章推荐
- .NET备份博客园随笔分类文章
- 博客园随笔和文章的备份工具
- 博客园随笔和文章的备份工具
- 以读取博客园随笔备份为例 将xml 序列化成json,再序列化成对象
- 博客园首页新随笔联系管理订阅 随笔- 70 文章- 22 评论- 5 Spring 事务机制详解
- SAE 平台代码实现数据库定时备份以及同步到本地 2014/09/11 09:39:01 分类: 技术随笔 1人评论 次浏览 SAE 只允许用户通过phpMyAdmin管理远程数据库,
- 博客园首页新随笔联系管理订阅 随笔- 7 文章- 0 评论- 4 ElasticSearch 5.0.1 java API操作
- 如何在博客园的文章/随笔中添加可运行的js代码
- 博客园首页新随笔联系管理订阅 随笔- 216 文章- 1 评论- 2 Java ConcurrentModificationException异常原因和解决方法
- 博客园首页新随笔联系管理订阅 随笔- 524 文章- 0 评论- 20 hdu-5810 Balls and Boxes(概率期望)
- 博客园首页博问闪存新随笔联系订阅管理 随笔- 252 文章- 0 评论- 45 HashPasswordForStoringInConfigFile中的Md5算法并非常用的Md5算法
- 博客园的“随笔、文章、新闻、日记”有啥区别
- 随笔 文章 新闻 日记 有啥区别~ - 博问 - 博客园社区
- 博客园文章分类序号说明
- .net模拟登录博客园,使用httpWebRequest登录并发布随笔文章
- .net 登录博客园 并且发表文章一篇
- 博客园 首页 新随笔 联系 管理 随笔 - 98 文章 - 0 评论 - 157 Android总结篇系列:Android Service
- 对博客园随笔分类的一点建议
- 在Web微信应用中使用博客园RSS以及Quartz.NET实现博客文章内容的定期推送功能
- nutch学习、、孤剑之家 宝剑锋从磨砺出,梅花香自苦寒来。我欲仗剑走天涯。 博客园 首页 新随笔 联系 订阅订阅 管理 随笔 - 771 文章 - 8 评论 - 13