MySQL中计算索引长度
2016-10-12 22:08
330 查看
首先,我们来看一道题目,针对表t,包含了三个字段a、b、c,假设其默认值都非空,现创建组合索引index(a,b,c) 分析select * from t where a=1 and c=1 和select * from t where a=1 and b=1区别?
首先创建表

分别执行这两条语句
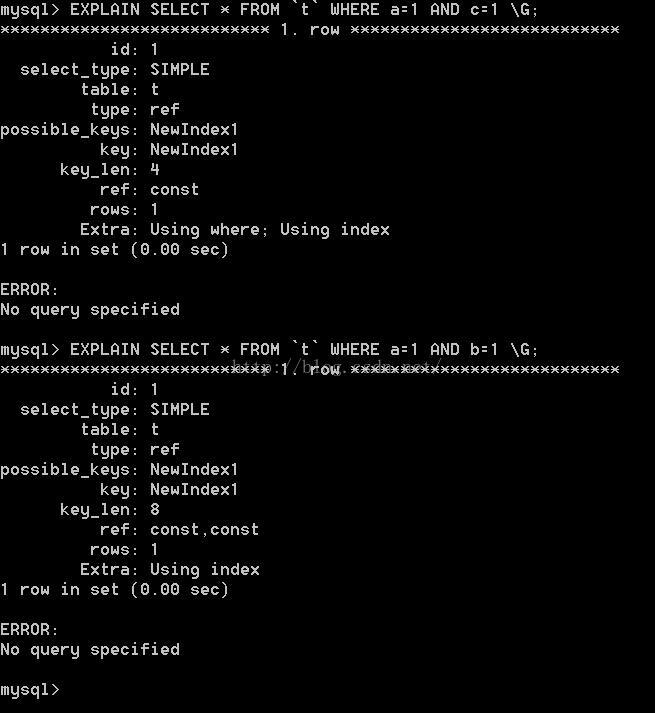
发现,两则区别主要是在于key_len上,为什么二则区别不一样呢?
我的理解是:
我们可以讲组合索引想成书的一级目录、二级目录、三级目录,如index(a,b,c),相当于a是一级目录,b是一级目录下的二级目录,c是二级目录下的三级目录。要使用某一目录,必须先使用其上级目录,除了一级目录除外。
所以
where a=1 and c=1只使用了一级目录,c在三级目录,没有使用二级目录,那么三级目录就没法使用
where a=1 and b=1只使用了一级目录、二级目录。
于是第二条查询的key_len更大。
但是,具体key_len怎么计算的,上面怎样计算出是4和8的呢?之前没怎么关注过。在通过explain分析SQL查询语句的性能的时候,之前,我更多关注的是select_type、type、possible_key、key、ref、rows、extra,这次,我觉得有必要弄清楚key_len的计算.
1.所有的索引字段,如果没有设置not null,则需要加一个字节。
2.定长字段,int占四个字节、date占三个字节、char(n)占n个字符。
3.对于变成字段varchar(n),则有n个字符+两个字节。
4.不同的字符集,一个字符占用的字节数不同。latin1编码的,一个字符占用一个字节,gbk编码的,一个字符占用两个字节,utf8编码的,一个字符占用三个字节。
因此可以得出
where a=1 and c=1而言,key_len=4
where a=1 and c=1而言,key_len=4+4=8
现在再来做一道题,创建一个t2表,数据结构如下
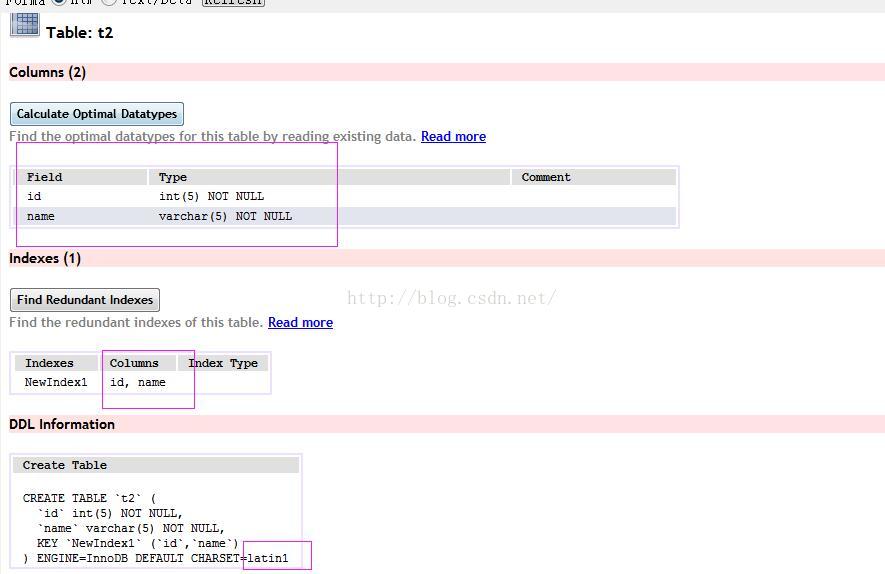
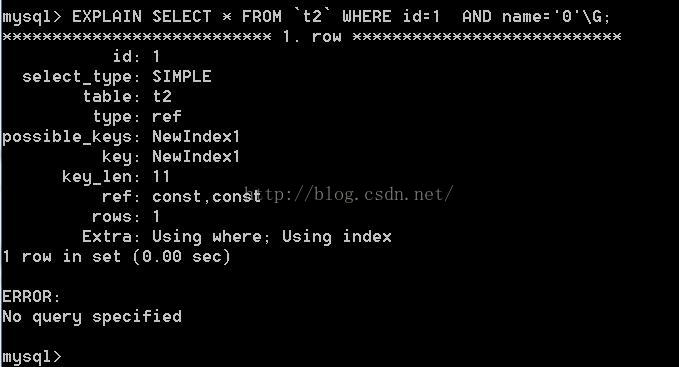
求执行explain select * from t2 where name="001" and id=1 \G;的key_len是多少呢?
分析key_len=4+5*1+2=11,因为字段都是not null,int类型4个字节,varchar(5) 占用5个字符+2个字节,latin1编码的表一个字符占1个字节,故varchar(5) 占用7个字节。结构如下图
a=1 and c=1吧,便于理解以及查询缓冲。因为查询缓冲,hashkey值,是以sql语句来计算的,且区分大小写,所以在写SQL语句的时候,尽量保存一致,防止相同的查询被缓存多次。
首先创建表
分别执行这两条语句
发现,两则区别主要是在于key_len上,为什么二则区别不一样呢?
我的理解是:
我们可以讲组合索引想成书的一级目录、二级目录、三级目录,如index(a,b,c),相当于a是一级目录,b是一级目录下的二级目录,c是二级目录下的三级目录。要使用某一目录,必须先使用其上级目录,除了一级目录除外。
所以
where a=1 and c=1只使用了一级目录,c在三级目录,没有使用二级目录,那么三级目录就没法使用
where a=1 and b=1只使用了一级目录、二级目录。
于是第二条查询的key_len更大。
但是,具体key_len怎么计算的,上面怎样计算出是4和8的呢?之前没怎么关注过。在通过explain分析SQL查询语句的性能的时候,之前,我更多关注的是select_type、type、possible_key、key、ref、rows、extra,这次,我觉得有必要弄清楚key_len的计算.
1.所有的索引字段,如果没有设置not null,则需要加一个字节。
2.定长字段,int占四个字节、date占三个字节、char(n)占n个字符。
3.对于变成字段varchar(n),则有n个字符+两个字节。
4.不同的字符集,一个字符占用的字节数不同。latin1编码的,一个字符占用一个字节,gbk编码的,一个字符占用两个字节,utf8编码的,一个字符占用三个字节。
因此可以得出
where a=1 and c=1而言,key_len=4
where a=1 and c=1而言,key_len=4+4=8
现在再来做一道题,创建一个t2表,数据结构如下
求执行explain select * from t2 where name="001" and id=1 \G;的key_len是多少呢?
分析key_len=4+5*1+2=11,因为字段都是not null,int类型4个字节,varchar(5) 占用5个字符+2个字节,latin1编码的表一个字符占1个字节,故varchar(5) 占用7个字节。结构如下图
补充
因为MySQL具有查询优化器,所以对where a=1 and c=1类型的查询,字段顺序没有任何影响,查询优化器会自动优化。where c=1 and a=1会被优化成where a=1 and c=1,但是建议还是使用wherea=1 and c=1吧,便于理解以及查询缓冲。因为查询缓冲,hashkey值,是以sql语句来计算的,且区分大小写,所以在写SQL语句的时候,尽量保存一致,防止相同的查询被缓存多次。

相关文章推荐
- [Mysql]mysql索引长度和key_len计算
- MySQL一个索引列最大允许的有效长度,不是列的所有数据都被索引的
- MySQL中varchar最大长度计算
- mysql.ini最小查询索引长度
- 一种可衡量的确定MySQL前缀索引长度方法
- mysql设置合适的索引长度
- MySQL索引长度问题(转)
- MySQL的COUNT()函数利用索引进行计算
- mysql 确定前缀索引长度方法
- MySQL索引长度限制问题
- MySQL索引的索引长度问题
- 【MySQL运维】实例讲解MySQL中正确计算 Varchar 可存储的最大长度
- mysql 字符串长度计算实现代码(gb2312+utf8)
- perl中操作mysql,字符匹配与替换,字符串截取,计算字符长度
- MySql 计算字段长度函数
- mysql 索引长度限制
- MySQL索引的索引长度问题
- mysql索引长度限制
- mysql 索引长度tips innodb和myisam引擎
- mysql 索引长度和区分度