Evaluation of GIST descriptors for web-scale image search
2016-10-11 15:40
381 查看
论文介绍:
论文主要比较了全局特征GIST和其他的局部特征,分别在图像相似检索和近乎拷贝检索的两个任务上不同效果。同时作者对于BOF优化的一些方法进行了实验,例如HE(Hamming Embedding) BOF 空间划分,并在召回率和准确率进行比较,同时在使用的内存和检索时间进行了比较。最后作者提出来了一种综合传统BOF的方法,并考虑内存使用和查询准确率的建立索引的方法。在实验中,作者提出来的方法再拷贝检索中能够以牺牲很少的准确率代价达到较高的效率。
Gabor滤波卷积feature map
32Gabor 滤波在4个尺度,8个方向上进行卷积,得到32个feature map 大小和输入图像一致。
进行区域划分,求每个区域的均值
把每个feature map 分成4*4=16的区域,计算每个区域内的均值。
计算16*32个均值的结果就获得了,512维的GIST特征。
可以改变卷积核的尺度核方向,可以获得不同的维度的GIST特征
聚类得到视觉中心
每幅图像表示:直方图
BoF系统构成
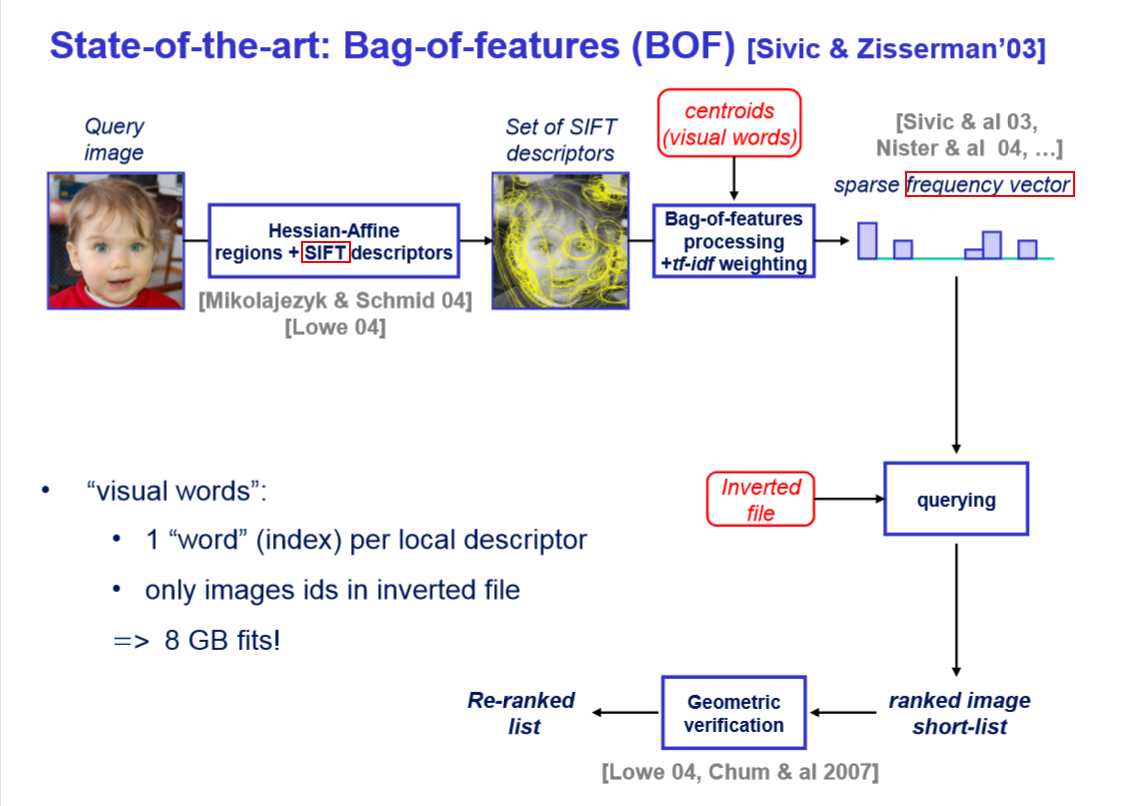
图片描述子x,(局部、全局)
表示成(q(x),b(x),…)
b(x) 长度为K的二进制
实际操作过程:
1. 随机生成矩阵An∗n,符合高斯分布
2. 对A进行QR分解[Q,R]=qr(A)
3. 投影矩阵的生成P=Q[:K,:],前K行
T=[T1,T2⋯Tn]
Ti=[t1,t2,⋯tk]T
ti为每个中心的所有特征i维度的中值。对于描述子x进行投影
z=Px=(z1,z2⋯zK)
bi={10如果zi>Tl,i,q(x)=l,l为x所在的中心否则
b=[b1,b2,⋯bK],bi∈{0,1}
这样就可以得到一个数据集上面的二进制hamming code的方法。
根据Hamming Embedding 以及其与BOF的结合,可以得到一下的索引结构:

其中b是上述方法生成的二进制hamming code,qaqb表示其他额外的信息。比如可以是出现的频率tf,hamming code 可以作为特征点匹配或者图像匹配,也可以用来过滤特征点。继而使用tf进行投票。
视觉中心: q(x)
区域信息:r(x)
图片: (q(x),r(x))
扩大视觉中心
降低准确性,提高效率

再匹配的阶段只有在同一个区域内的特征点,才认为是匹配的。所以在原来的视觉中心添加了区域信息,这样就扩大了原来的视觉中心的个数。
同时在检索的时候,只检索特定区域内的视觉中心,所以降低了准确性,但是在倒排索引当中取出来的图片少了,投票的过程少了很多,提高了效率。
RANSAC:仿射变换
Generalized Hough Transform
Hough变换的概念:
对于求直线y=mx+c的算法:
原始图像空间x-y到参数空间m-c的变换:

这样求得经过x-y空间变换到m-c空间中所有直线,所有交点中,相交直线最多的那个点,所确定的m-c对应图像中的一条直线。
对于多个可以匹配的点,一对点可以是由四个参数的仿射变换得到的。确定满足这个仿射变换的点的个数,找到满足四个参数的最多的点。就是这两个图像特征点集合的仿射变换。根据这一点来过滤不匹配的特征点。
对GIST特征进行聚类
按着Hamming Embedding生成二进制签名512bit
建立倒排索引,元素中存储二进制签名
这里不同于传统的一点就是在使用特征的时候,是使用全局特征,聚类中心是GIST进行的聚类,Hamming Embedding 用来进行过滤不相似的特征。
具体的索引构建如下:

经过索引系统,过滤不相似的图片,然后进行相似度的匹配系统。
GISTIS+L2:欧式距离的比较,距离近的相似
GISTIS+L2+SV:几何校验,使用上述的SV方法进行相似度的排序
多类相似检索
1491张图片
500类别
每一类的第一张作为检索图片
同类的图片认为是相似的
角度变换较大,对于全局特征效果差
Copydays:
近乎拷贝检索
157张图片原始图片
大小变换
裁剪5%~80%
尺度变换,裁剪,对比度产生229张图片
拷贝检测的的极端情况
具体的几种变换:尺度,分辨率,裁剪,大小

Distractors:其他数据
Flickr 32.7million
Tiny Set:79million 32*32

最后L2的两种检索方式分别在内存中和磁盘中。
1.BOF 20 SIFT/image
2.GIST-960
3.GISTIS (32+512bit)/8
4.fingerprint:描述子所属视觉中心过程
从上面的表可以看出来:
1.全局特征更快
2.作者提出GISTIS使用更少的内存,和更快的查询速度

从上面的表可以看出来:局部特征好于全局特征,局部特征可以更好的匹配相似的图片,而全局特征对于拷贝检测更好,下面的实验结果也能够说明这一点

从上面的结果可以看出来:
1.GISTIS相比于GIST准确率几乎没有下降
2.全局特征没有局部特征效果好
3.SV与全局特征互补

在拷贝数据集Copydays+Flickr1M上面的结果
检索的是Copydays的数据,近似于拷贝检索。
可以得出来:
1.拷贝检测
2.GIST比局部特征效果好
对于变化不是很大的图片,全局特征能够很好的匹配。

在有限的裁剪范围内,检索的结果不会变差,但是在超过30%作者的方法就会急剧下降,可以说所有的全局特征都会下降。局部特征还是会缓慢降低结果。

可以看出来对于比较强的变换:局部描述子(特征)相比于全局特征得到的结果会更好。
近乎的拷贝检测:不同尺度,压缩率,有限裁剪(20%)
作者提出来的GISTIS效果更好,速度更快,内存更少
论文主要比较了全局特征GIST和其他的局部特征,分别在图像相似检索和近乎拷贝检索的两个任务上不同效果。同时作者对于BOF优化的一些方法进行了实验,例如HE(Hamming Embedding) BOF 空间划分,并在召回率和准确率进行比较,同时在使用的内存和检索时间进行了比较。最后作者提出来了一种综合传统BOF的方法,并考虑内存使用和查询准确率的建立索引的方法。在实验中,作者提出来的方法再拷贝检索中能够以牺牲很少的准确率代价达到较高的效率。
2.图像的表示
2.1 GIST全局特征
GIST特征的生成Gabor滤波卷积feature map
32Gabor 滤波在4个尺度,8个方向上进行卷积,得到32个feature map 大小和输入图像一致。
进行区域划分,求每个区域的均值
把每个feature map 分成4*4=16的区域,计算每个区域内的均值。
计算16*32个均值的结果就获得了,512维的GIST特征。
可以改变卷积核的尺度核方向,可以获得不同的维度的GIST特征
2.3.Bag-of-Feature
提取特征:例如SIFT聚类得到视觉中心
每幅图像表示:直方图
BoF系统构成
2.4.Hamming embedding
Hamming Embedding 生成过程图片描述子x,(局部、全局)
表示成(q(x),b(x),…)
b(x) 长度为K的二进制
实际操作过程:
1. 随机生成矩阵An∗n,符合高斯分布
2. 对A进行QR分解[Q,R]=qr(A)
3. 投影矩阵的生成P=Q[:K,:],前K行
T=[T1,T2⋯Tn]
Ti=[t1,t2,⋯tk]T
ti为每个中心的所有特征i维度的中值。对于描述子x进行投影
z=Px=(z1,z2⋯zK)
bi={10如果zi>Tl,i,q(x)=l,l为x所在的中心否则
b=[b1,b2,⋯bK],bi∈{0,1}
这样就可以得到一个数据集上面的二进制hamming code的方法。
根据Hamming Embedding 以及其与BOF的结合,可以得到一下的索引结构:
其中b是上述方法生成的二进制hamming code,qaqb表示其他额外的信息。比如可以是出现的频率tf,hamming code 可以作为特征点匹配或者图像匹配,也可以用来过滤特征点。继而使用tf进行投票。
2.5.BoF with spatial grid
在BOF的基础之上添加了区域信息视觉中心: q(x)
区域信息:r(x)
图片: (q(x),r(x))
扩大视觉中心
降低准确性,提高效率
再匹配的阶段只有在同一个区域内的特征点,才认为是匹配的。所以在原来的视觉中心添加了区域信息,这样就扩大了原来的视觉中心的个数。
同时在检索的时候,只检索特定区域内的视觉中心,所以降低了准确性,但是在倒排索引当中取出来的图片少了,投票的过程少了很多,提高了效率。
2.6.Spatial Verification
空间校验算法:解决仿射变换,尺度变化RANSAC:仿射变换
Generalized Hough Transform
Hough变换的概念:
对于求直线y=mx+c的算法:
原始图像空间x-y到参数空间m-c的变换:
这样求得经过x-y空间变换到m-c空间中所有直线,所有交点中,相交直线最多的那个点,所确定的m-c对应图像中的一条直线。
对于多个可以匹配的点,一对点可以是由四个参数的仿射变换得到的。确定满足这个仿射变换的点的个数,找到满足四个参数的最多的点。就是这两个图像特征点集合的仿射变换。根据这一点来过滤不匹配的特征点。
2.7 GIST Indexing Structure
作者提出来的一个考虑到效率和准确率的索引结构对GIST特征进行聚类
按着Hamming Embedding生成二进制签名512bit
建立倒排索引,元素中存储二进制签名
这里不同于传统的一点就是在使用特征的时候,是使用全局特征,聚类中心是GIST进行的聚类,Hamming Embedding 用来进行过滤不相似的特征。
具体的索引构建如下:
经过索引系统,过滤不相似的图片,然后进行相似度的匹配系统。
2.8 2-stage re-ranking
相似度的计算加上空间位置的校验,从上述的检索系统图可以看出来,再过滤之后的排序的过程只需要知道相对顺序就可以。GISTIS+L2:欧式距离的比较,距离近的相似
GISTIS+L2+SV:几何校验,使用上述的SV方法进行相似度的排序
3 实验
3.1数据集
Holidays:多类相似检索
1491张图片
500类别
每一类的第一张作为检索图片
同类的图片认为是相似的
角度变换较大,对于全局特征效果差
Copydays:
近乎拷贝检索
157张图片原始图片
大小变换
裁剪5%~80%
尺度变换,裁剪,对比度产生229张图片
拷贝检测的的极端情况
具体的几种变换:尺度,分辨率,裁剪,大小
Distractors:其他数据
Flickr 32.7million
Tiny Set:79million 32*32
3.2 实验比较
3.2.1 Memory & Time
最后L2的两种检索方式分别在内存中和磁盘中。
1.BOF 20 SIFT/image
2.GIST-960
3.GISTIS (32+512bit)/8
4.fingerprint:描述子所属视觉中心过程
从上面的表可以看出来:
1.全局特征更快
2.作者提出GISTIS使用更少的内存,和更快的查询速度
3.2.2召回率比较
从上面的表可以看出来:局部特征好于全局特征,局部特征可以更好的匹配相似的图片,而全局特征对于拷贝检测更好,下面的实验结果也能够说明这一点
3.2.3 Distractors 影响
从上面的结果可以看出来:
1.GISTIS相比于GIST准确率几乎没有下降
2.全局特征没有局部特征效果好
3.SV与全局特征互补
3.2.4 图片尺寸影响
在拷贝数据集Copydays+Flickr1M上面的结果
检索的是Copydays的数据,近似于拷贝检索。
可以得出来:
1.拷贝检测
2.GIST比局部特征效果好
对于变化不是很大的图片,全局特征能够很好的匹配。
3.2.4 裁剪的影响
在有限的裁剪范围内,检索的结果不会变差,但是在超过30%作者的方法就会急剧下降,可以说所有的全局特征都会下降。局部特征还是会缓慢降低结果。
3.2.5 几种变换的影响
可以看出来对于比较强的变换:局部描述子(特征)相比于全局特征得到的结果会更好。
4.结论
近似检索:局部特征效果好于GIST近乎的拷贝检测:不同尺度,压缩率,有限裁剪(20%)
作者提出来的GISTIS效果更好,速度更快,内存更少

相关文章推荐
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- 微软的一篇ctr预估的论文:Web-Scale Bayesian Click-Through Rate Prediction for Sponsored Search Advertising in Microsoft’s Bing Search Engine。
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- Bag-of-colors for Improved Image Search
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- 搜索引擎的工作原理 --《The Anatomy of a Large-Scale Hypertextual Web Search Engine》
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- Hamming embedding and weak geometric consistency for large scale image search
- 论文阅读《Hamming embedding and weak geometric consistency for large scale image search》
- 大规模超文本网络搜索引擎解析 [ The Anatomy of a Large-Scale Hypertextual Web Search Engine ]
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- 解剖Google搜索原理 The Anatomy of a Large-Scale Hypertextual Web Search Engine
- 论文翻译:Development and Evaluation of Emerging Design Patterns for Ubiquitous Computing
- Handbook of Research on User Interface Design and Evaluation for Mobile Technology
- The Design of Sites: Patterns, Principles, and Processes for Crafting a Customer-Centered Web Experi
- Search Engine Optimization for Flash: Best practices for using Flash on the web
- Unable to start debugging on the web server. The web server is not configured correctly. See help for common configuration errors. Running the web page outside of the debugger may provide further information.
- Image.FromFile gives "Out of Memory" Exception for icon
- [收藏] 35 of the Best Icon Sets for Web Designers