python之获取页面标签的方法
2016-10-09 13:59
411 查看
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bs0bj = BeautifulSoup(html.read(), "html.parser")
title = bs0bj.head.title
except AttributeError as e:
return None
return title
title = getTitle("http://www.baidu.com")
if title == None:
print("Title could not be found !")
else:
print(title)结果如下图所示
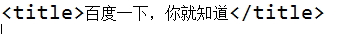
END!

相关文章推荐
- Python通过正则表达式获取,去除(过滤)或者替换HTML标签的几种方法(本文由169it.com搜集整理)
- JSP页面加载时同时访问action获取数据( struts标签s:action方法)
- 获取当前页面的所有链接的四种方法对比(python 爬虫)
- Python正则获取、过滤或者替换HTML标签的方法
- python selenium 获取标签的属性值、内容、状态方法
- 获取jsp页面标签value的三种方法
- 关于加快python爬虫获取页面的方法
- Python获取当前页面内所有链接的四种方法对比分析
- Python正则获取、过滤或者替换HTML标签的方法
- 学习笔记之php页面中js获取标签元素的ID值方法
- ascx页面获取标签的通用方法
- CAS如何在服务器端的登陆成功页面获取登陆用户帐号的方法
- 在cs页面获取input的值方法
- Javascript获取页面大小值的方法__XHTML1.0规范
- CAS如何在服务器端的登陆成功页面获取登陆用户帐号的方法
- 【用Python写爬虫】获取html的方法【二】:使用pycurl
- 自定义服务器组件获取其页面控件里所输入的值的方法
- 【用Python写爬虫】获取html的方法【一】:使用urllib
- 【用Python写爬虫】获取html的方法【四】:使用urllib下载文件
- Ajax获取页面被缓存的解决方法