基于Caffe的人脸识别实现
2016-10-09 11:45
393 查看
http://blog.csdn.net/chenriwei2/article/details/46432727
导言
深度学习深似海、尤其是在图像人脸识别领域,最近几年的顶会和顶刊常常会出现没有太多的理论创新的文章,但是效果摆在那边。DeepID是深度学习方法进行人脸识别中的一个简单,却高效的一个网络模型,其结构的特点可以概括为两句话:1、训练一个多个人脸的分类器,当训练好之后,就可以把待测试图像放入网络中进行提取特征,2对于提取到的特征,然后就是利用其它的比较方法进行度量。具体的论文可以参照我的一篇论文笔记:【深度学习论文笔记】Deep
Learning Face Representation from Predicting 10,000 Classes
首先我们完全参考论文的方法用Caffe设计一个网络结构:
其拓扑图如图1所示:

图1:DeepID的网络结构,图像比较大,需要放大才能看的清楚
网络定义文件:
略1
2. 数据选择
训练一个好的深度模型,一个好的训练数据是必不可少的。针对人脸识别的数据,目前公开的数据也有很多:比如最近的MegaFace、港大的Celbra A、中科研的WebFace 等等。在这里,我选择WebFace人脸数据库作为训练(人脸库不是很干净,噪声较多),图像公共50万张左右,共10575个人,但是数据不平衡。要评测一个算法的性能,需要找一个公平的比对数据库来评测,在人脸验证中,LFW数据库无疑是最好的选择。在lfw评测中,给出6000千对人脸图像对进行人匹配。
3. 数据处理
训练数据和测试数据都选择好之后,就需要进行数据处理了,为了提供较好的识别准确度,我采用了训练数据和测试数据统一的预处理方法(虽然LFW上有提供已经预处理过的人脸图像,但是预处理的具体参数还是未知的),测试数据和训练数据都采样相同的人脸检测和对齐方法。主要分为3个步骤:
1,人脸检测
2,人脸特征点检测
3、人脸的对齐
这三个步骤可以用我做的一个小工具:FaceTools 来一键完成。
具体来说,需要选择一个标准的人脸图像作为对齐的基准,我挑选一位帅哥当标准图像:
如图:

训练数据通过对齐后是这样的:

LFW测试数据通过对齐后是这样的:

4.数据转换
图像处理好之后,需要将其转化为Caffe 可以接受的格式。虽然Caffe支持直接读图像文件的格式进行训练,但是这种方式磁盘IO会比较的大,所以我这里不采用图像列表的方式,而是将训练和验证图片都转化为LMDB的格式处理。4.1 划分训练集验证集
划分训练集和验证集(我采样的是9:1的比例)脚本如下:
略1
4.2 数据转换
再调用Caffe 提供的转化函数:脚本如下:
略1
这样之后,训练的数据就准备好了。
训练网络
上面的这些步骤之后,数据就已经处理好了,现在需要指定网络的超参数:具体超参数设置如下:
略1
训练的时候,可以查看学习曲线:
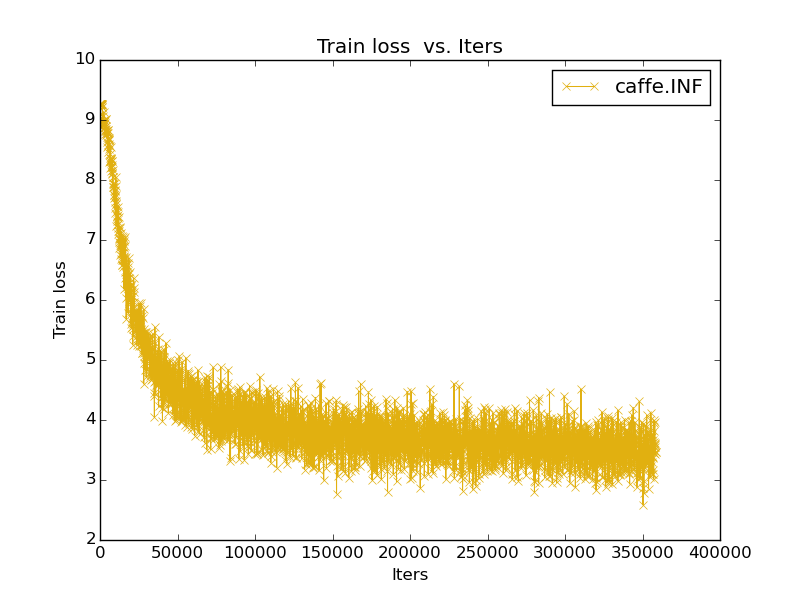
6.LFW上测试
LFW上,提供了6000对的人脸图像对来作为评测数据,由于我采用的是自己选的人脸检测和对齐方法,所以有些人脸在我的预处理里面丢失了(检测不到),为了简单的处理这种情况,在提特征的时候,没有检测到的图像就用原来的图像去替代。略1
然后进行人脸的比对
略1
结果ROC曲线:
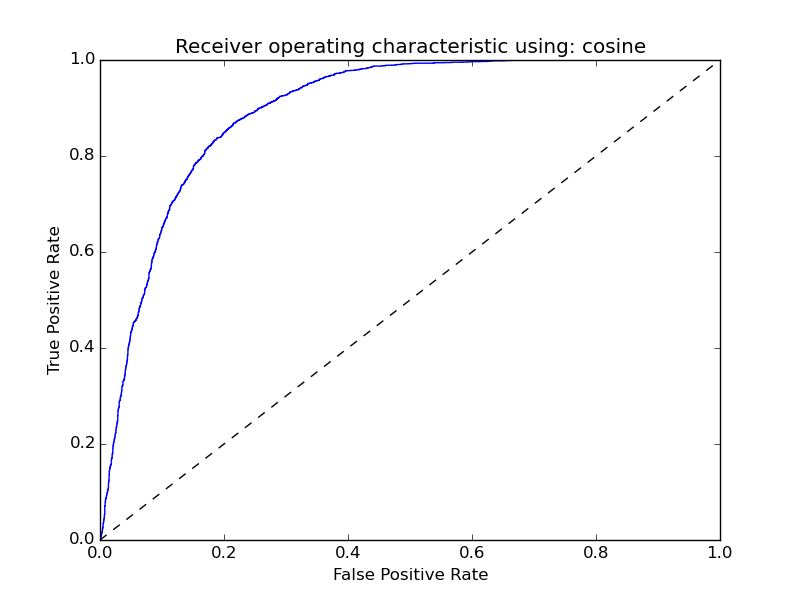
通过选择合适的脚本,得到的准确度为:0.826333333333, 有点低。
7.结果分析
实验的结果没有理想中的那么好,主要的原因分为几个:1、数据集不够好:有较多的噪声数据
2、数据集合不平衡:每个人的图片个数从几十张到几百张不等。
3,、网络结构没优化:原始的DeepID的大小为:48*48,而我选择的人脸图像大小为64*64,网络结构却没有相对应的调整。(主要影响在于全连接层的个数太多了)

相关文章推荐
- 【Caffe实践】基于Caffe的人脸识别实现
- 【Caffe实践】基于Caffe的人脸识别实现
- 【Caffe实践】基于Caffe的人脸识别实现
- 【Caffe实践】基于Caffe的人脸识别实现
- 基于Caffe的人脸识别实现
- 【Caffe实践】基于Caffe的人脸识别实现
- 基于MATLAB的PCA人脸识别实现
- 基于Caffe的人脸检测实现
- 模式识别hw2-------基于matconvnet,用CNN实现人脸图片性别识别
- 【Caffe实践】基于Caffe的人脸检测实现
- 基于卷积神经网络实现的人脸识别
- 【Caffe实践】基于Caffe的人脸检测实现
- 基于Caffe的人脸检测实现
- Android基于人脸识别的用户注册/登录实现思路
- 【Caffe实践】基于CNN的性别、年龄识别的代码实现
- 基于OpenCV的人脸识别算法之二---代码实现
- C#实现基于ffmpeg加虹软的人脸识别
- C#实现基于ffmpeg加虹软的人脸识别的示例
- 人脸识别---利用caffe实现多层特征学习人脸识别网络
- 【Caffe实践】基于Caffe的人脸检测实现