Java 8 Lambda函数编程入门(三)
2016-10-01 15:40
399 查看
高级集合类和收集器
Java 8对集合类的改进不止第一讲的那些。还有一些高级主题,包括新引入的 Collector 类、方法引用等。方法引用
Lambda 表达式有一个常见的用法:Lambda 表达式经常调用参数。比如想得到艺术家的姓名,Lambda 的表达式如下:artist -> artist.getName()
这种用法如此普遍,因此Java 8为其提供了一个简写语法,叫作方法引用,帮助程序员重用已有方法。用方法引用重写上面的 Lambda 表达式,代码如下:
Artist::getName
标准语法为
Classname::methodName。需要注意的是,虽然这是一个方法,但不需要在后面加括号,因为这里并不调用该方法。我们只是提供了和 Lambda 表达式等价的一种结构, 在需要时才会调用。凡是使用 Lambda 表达式的地方,就可以使用方法引用。
构造函数也有同样的缩写形式,如果你想使用 Lambda 表达式创建一个 Artist 对象,可能 会写出如下代码:
(name, nationality) -> new Artist(name, nationality)
使用方法引用,上述代码可写为:
Artist::new
这段代码不仅比原来的代码短,而且更易阅读。
Artist::new立刻告诉程序员这是在创建 一个 Artist 对象,程序员无需看完整行代码就能弄明白代码的意图。另一个要注意的地方 是方法引用自动支持多个参数,前提是选对了正确的函数接口。
还可以用这种方式创建数组,下面的代码创建了一个字符串型的数组:
String[]::new
元素顺序
流中的元素以何种顺序排列。一些集合类型中的元素是按顺序排列的,比如 List;而另一些则是无序的,比如 HashSet。 增加了流操作后,顺序问题变得更加复杂。直观上看,流是有序的,因为流中的元素都是按顺序处理的。这种顺序称为出现顺序。出现顺序的定义依赖于数据源和对流的操作。
在一个有序集合中创建一个流时,流中的元素就按出现顺序排列,例如顺序测试永远通过:
List<Integer> numbers = asList(1, 2, 3, 4); List<Integer> sameOrder = numbers.stream() .collect(toList()); assertEquals(numbers, sameOrder);
如果集合本身就是无序的,由此生成的流也是无序的。例如顺序测试不能保证每次通过:
Set<Integer> numbers = new HashSet<>(asList(4, 3, 2, 1)); List<Integer> sameOrder = numbers.stream() .collect(toList()); // 该断言有时会失败 assertEquals(asList(4, 3, 2, 1), sameOrder);
流的目的不仅是在集合类之间做转换,而且同时提供了一组处理数据的通用操作。有些集合本身是无序的,但这些操作有时会产生顺序。例如生成出现顺序:
Set<Integer> numbers = new HashSet<>(asList(4, 3, 2, 1)); List<Integer> sameOrder = numbers.stream() .sorted() .collect(toList()); assertEquals(asList(1, 2, 3, 4), sameOrder);
一些中间操作会产生顺序,比如对值做映射时,映射后的值是有序的,这种顺序就会保留下来。如果进来的流是无序的,出去的流也是无序的。看一下例所示代码,我们只能断言 HashSet 中含有某元素,但对其顺序不能作出任何假设,因为 HashSet 是无序的,使用了映射操作后,得到的集合仍然是无序的。
List<Integer> numbers = asList(1, 2, 3, 4); List<Integer> stillOrdered = numbers.stream() .map(x->x+1) .collect(toList()); // 顺序得到了保留 assertEquals(asList(2, 3, 4, 5), stillOrdered); Set<Integer> unordered = new HashSet<>(numbers); List<Integer> stillUnordered = unordered.stream() .map(x->x+1) .collect(toList()); // 顺序得不到保证 assertThat(stillUnordered, hasItem(2)); assertThat(stillUnordered, hasItem(3)); assertThat(stillUnordered, hasItem(4)); assertThat(stillUnordered, hasItem(5));
一些操作在有序的流上开销更大,调用 unordered 方法消除这种顺序就能解决该问题。大 多数操作都是在有序流上效率更高,比如 filter、map 和 reduce 等。
使用并行流时,forEach 方法不能保证元素是按顺序处理的。如果需要保证按顺序处理,应该使用 forEachOrdered 方法。
使用收集器
一种通用的、从流生成复杂值的结构就是收集器。转换成其他集合
有一些收集器可以生成其他集合。比如前面已经见过的 toList,生成了 java.util.List 类的实例。还有 toSet 和 toCollection,分别生成 Set 和 Collection 类的实例。通常情况下,创建集合时需要调用适当的构造函数指明集合的具体类型:
List<Artist> artists = new ArrayList<>();
但是调用 toList 或者 toSet 方法时,不需要指定具体的类型。Stream 类库在背后自动为你 挑选出了合适的类型。本书后面会讲述如何使用 Stream 类库并行处理数据,收集并行操作 的结果需要的 Set,和对线程安全没有要求的 Set 类是完全不同的。
可能还会有这样的情况,你希望使用一个特定的集合收集值,而且你可以稍后指定该集合 的类型。比如,你可能希望使用 TreeSet,而不是由框架在背后自动为你指定一种类型的 Set。此时就可以使用 toCollection,它接受一个函数作为参数,来创建集合。例如使用 toCollection,用定制的集合收集元素:
stream.collect(toCollection(TreeSet::new));
转换成值
还可以利用收集器让流生成一个值。maxBy 和 minBy 允许用户按某种特定的顺序生成一个 值。averagingInt 方法接受一个 Lambda 表达式作参数,将流中的元素转换成一个整数,然后再计算平均数。例如找出一组专辑上曲目的平均数:public double averageNumberOfTracks(List<Album> albums) {
return albums.stream()
.collect(averagingInt(album -> album.getTrackList().size()));
}数据分组
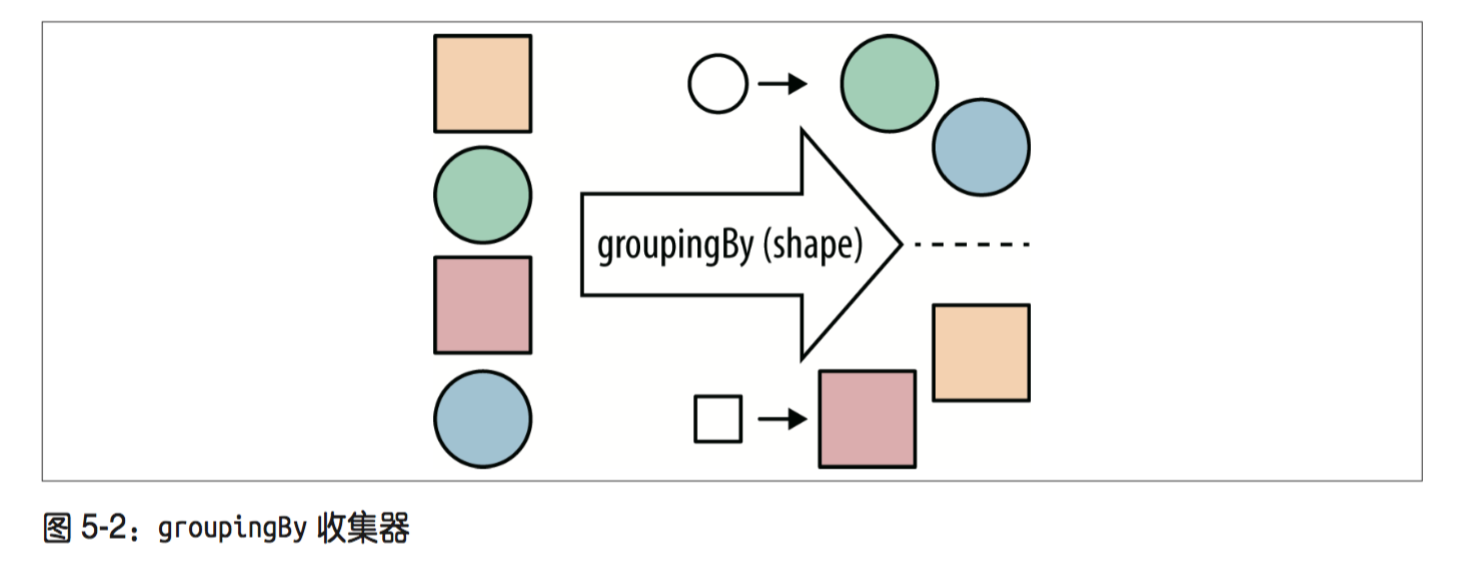
数据分组是一种更自然的分割数据操作,与将数据分成 ture 和 false 两部分不同,可以使 用任意值对数据分组。比如现在有一个由专辑组成的流,可以按专辑当中的主唱对专辑分组。例如使用主唱对专辑分组:public Map<Artist, List<Album>> albumsByArtist(Stream<Album> albums){
return albums.collect(groupingBy(album -> album.getMainMusician()));
}groupingBy 收集器(如下图所示)接受一个分类函数,用来对数据分组,就像 partitioningBy 一样,接受一个 Predicate 对象将数据分成 ture 和 false 两部分。
字符串
很多时候,收集流中的数据都是为了在最后生成一个字符串。旧的方法:使用 for 循环格式化艺术家姓名
StringBuilder builder = new StringBuilder("[");
for (Artist artist : artists) {
if (builder.length() > 1)
builder.append(", ");
String name = artist.getName();
builder.append(name);
}
builder.append("]");
String result = builder.toString();新的方法:使用流和收集器格式化艺术家姓名
String result =
artists.stream()
.map(Artist::getName)
.collect(Collectors.joining(", ", "[", "]"));上面的输出都为:
"[George Harrison, John Lennon, Paul McCartney, Ringo Starr, The Beatles]"。
组合收集器
虽然现在看到的各种收集器已经很强大了,但如果将它们组合起来,会变得更强大。例如使用收集器计算每个艺术家的专辑数:public Map<Artist, Long> numberOfAlbums(Stream<Album> albums) {
return albums.collect(groupingBy(album -> album.getMainMusician(), counting()));
}上面用到的
counting是第二个收集器,用以收集最终结果的一个子集。这些收集器叫作下游收集器。收集器是生成最终结果的一剂配方,下游收集器则是生成部分结果的配 方,主收集器中会用到下游收集器。这种组合使用收集器的方式,使得它们在 Stream 类库 中的作用更加强大。
重构和定制收集器 and 对收集器的归一化处理
例如reducing 是一种定制收集器的简便方式:String result =
artists.stream()
.map(Artist::getName)
.collect(Collectors.reducing(
new StringCombiner(", ", "[", "]"),
name -> new StringCombiner(", ", "[", "]").add(name), StringCombiner::merge))
.toString();一些细节
Lambda 表达式的引入也推动了一些新方法被加入集合类。假设使用Map<String, Artist> artistCache定义缓存。
Java 8引入了一个新方法computeIfAbsent,该方法接受一个Lambda表达式,值不存在时 使用该 Lambda 表达式计算新值。例如使用 computeIfAbsent 缓存:
public Artist getArtist(String name) {
return artistCache.computeIfAbsent(name, this::readArtistFromDB);
}你可能还希望在值不存在时不计算,为 Map 接口新增的 compute 和 computeIfAbsent 就能处理这些情况。
在 Map 上迭代。例如使用内部迭代遍历 Map 里的值:
Map<Artist, Integer> countOfAlbums = new HashMap<>();
albumsByArtist.forEach((artist, albums) -> {
countOfAlbums.put(artist, albums.size());
});参考资料:
Java 8函数式编程 作者:(英)沃伯顿著
备注:
转载请注明出处:http://blog.csdn.net/wsyw126/article/details/52717639
作者:WSYW126

相关文章推荐
- Java 8 Lambda函数编程入门(二)
- Java 8 Lambda函数编程入门(一)
- Java 8 Lambda函数编程入门(四)
- Java 8 Lambda函数编程入门(五)
- java8入门必备——函数式编程思维——过滤函数的同义异名问题
- Java 8函数编程轻松入门(三)默认方法详解(default function)
- Java 8函数编程轻松入门(五)并行化(parallel)
- Python入门 第四天(函数式编程、map、reduce、filter、排序函数、函数返回函数、闭包、匿名函数lambda)
- Java 8函数编程轻松入门(四)方法引用
- java socket编程入门与示例
- Java加密和数字签名编程快速入门
- Java加密和数字签名编程快速入门(1/3)
- 新手入门:Java XML编程实例解析
- 新手入门:Java XML编程实例解析
- Java泛型编程快速入门
- JAVA游戏编程之二----j2me MIDlet 手机游戏入门开发--扫雷(3)-带线程--仿windows扫雷
- Java基础:Java泛型编程快速入门
- AOP编程入门--Java篇
- JAVA游戏编程之二----j2me MIDlet 手机游戏入门开发--扫雷(2)-不含线程
- Java泛型编程快速入门