跟着鬼哥学爬虫-9-python微信-4-我要自动看美女!
2016-09-28 15:15
253 查看
跟着鬼哥学爬虫-9-python微信-4-我要自动看美女!
好多同学问,上次我们爬了那么多的美女图干嘛用的。
这里回答一下,是为了在微信中自动回复图片用的,想看美女了,直接发送'我要看美女',然后自动回复美女图片。
# -*- coding: utf-8 -*-
import itchat
import sys
import random
from bs4 import BeautifulSoup
import urllib2
import urllib
import re
from tuling import get_response
#个人聊天信息的回复
@itchat.msg_register('Text')
def text_reply(msg):
if u'来个段子' in msg['Text']:
return getContent(1)
#自动回复群消息
@itchat.msg_register('Text', isGroupChat = True)
def group_reply(msg):
print msg['ActualNickName'] + '--' + msg['Text']
if u'来个段子' in msg['Text']:
return getContent(1)
if u'我要看美女' in msg['Text']:
print '''有人要开车!'''
#print '进来了,准备发送图片-'+msg['ActualNickName']
filme=random.randint(1,5566)
fileName='/home/suz/midgirls/'+str(filme)+'.jpg'
itchat.send('@img@%s' % fileName,msg['FromUserName'])
return '@'+msg['ActualNickName']
#随机获取一条糗事百科
def getContent(n):
n=random.randint(1,200)
url = 'http://www.qiushibaike.com/text/page/' + str(n) + '/'
#url = 'http://www.qiushibaike.com/8hr/page/'+str(n)+'/'
print url
heads = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.75 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Referer': 'http://www.qiushibaike.com/',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cookie': '_xsrf=2|db27040e|6b4ed8d9536590d4ec5d2064cc2bef4f|1474364551; _qqq_uuid_="2|1:0|10:1474364551|10:_qqq_uuid_|56:MzBlNWFkOGE3MWEyMzc1MWIxMTE3MDBlZjM2M2RkZWQxYzU5YTg1Yw==|1dd2a4f4ceacad26b5da9cc295d2965226ea25ee73289855cf032629c4992698"; Hm_lvt_2670efbdd59c7e3ed3749b458cafaa37=1474364592; Hm_lpvt_2670efbdd59c7e3ed3749b458cafaa37=1474364595; _ga=GA1.2.1125329542.1474364596'
}
res = urllib2.Request(url, headers=heads)
response = urllib2.urlopen(res)
fuckDuanzi=[]
html = response.read()
soup = BeautifulSoup(html, "lxml")
someData = soup.select("div.content span")
num = 0
for some in someData:
num = num + 1
fuckDuanzi.append(some.text)
mess=fuckDuanzi[random.randint(1,19)]
return mess
if __name__ == "__main__":
reload(sys)
sys.setdefaultencoding('utf-8')
itchat.auto_login(True, enableCmdQR = True)
itchat.run()
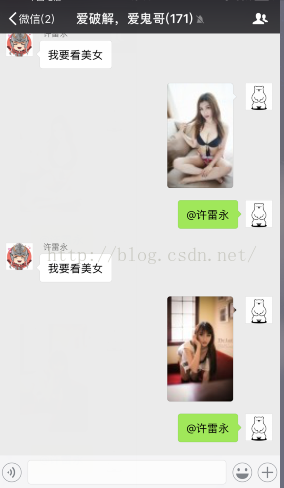
效果图:
好多同学问,上次我们爬了那么多的美女图干嘛用的。
这里回答一下,是为了在微信中自动回复图片用的,想看美女了,直接发送'我要看美女',然后自动回复美女图片。
# -*- coding: utf-8 -*-
import itchat
import sys
import random
from bs4 import BeautifulSoup
import urllib2
import urllib
import re
from tuling import get_response
#个人聊天信息的回复
@itchat.msg_register('Text')
def text_reply(msg):
if u'来个段子' in msg['Text']:
return getContent(1)
#自动回复群消息
@itchat.msg_register('Text', isGroupChat = True)
def group_reply(msg):
print msg['ActualNickName'] + '--' + msg['Text']
if u'来个段子' in msg['Text']:
return getContent(1)
if u'我要看美女' in msg['Text']:
print '''有人要开车!'''
#print '进来了,准备发送图片-'+msg['ActualNickName']
filme=random.randint(1,5566)
fileName='/home/suz/midgirls/'+str(filme)+'.jpg'
itchat.send('@img@%s' % fileName,msg['FromUserName'])
return '@'+msg['ActualNickName']
#随机获取一条糗事百科
def getContent(n):
n=random.randint(1,200)
url = 'http://www.qiushibaike.com/text/page/' + str(n) + '/'
#url = 'http://www.qiushibaike.com/8hr/page/'+str(n)+'/'
print url
heads = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.75 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Referer': 'http://www.qiushibaike.com/',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cookie': '_xsrf=2|db27040e|6b4ed8d9536590d4ec5d2064cc2bef4f|1474364551; _qqq_uuid_="2|1:0|10:1474364551|10:_qqq_uuid_|56:MzBlNWFkOGE3MWEyMzc1MWIxMTE3MDBlZjM2M2RkZWQxYzU5YTg1Yw==|1dd2a4f4ceacad26b5da9cc295d2965226ea25ee73289855cf032629c4992698"; Hm_lvt_2670efbdd59c7e3ed3749b458cafaa37=1474364592; Hm_lpvt_2670efbdd59c7e3ed3749b458cafaa37=1474364595; _ga=GA1.2.1125329542.1474364596'
}
res = urllib2.Request(url, headers=heads)
response = urllib2.urlopen(res)
fuckDuanzi=[]
html = response.read()
soup = BeautifulSoup(html, "lxml")
someData = soup.select("div.content span")
num = 0
for some in someData:
num = num + 1
fuckDuanzi.append(some.text)
mess=fuckDuanzi[random.randint(1,19)]
return mess
if __name__ == "__main__":
reload(sys)
sys.setdefaultencoding('utf-8')
itchat.auto_login(True, enableCmdQR = True)
itchat.run()
效果图:

相关文章推荐
- 跟着鬼哥学爬虫-6-python微信-1-学习篇
- 跟着鬼哥学爬虫-8-python微信-3-集合进去糗事百科!
- 跟着鬼哥学爬虫-7-python微信-2-开始编写模版代码
- 跟着鬼哥学爬虫-10-python微信-5-加上了人工智能回复!
- 跟着鬼哥学爬虫-3-美女图片!!!
- [Python爬虫] Selenium自动访问Firefox和Chrome并实现搜索截图
- [Python爬虫] Selenium实现自动登录163邮箱和Locating Elements介绍
- python3简单实现微信爬虫
- python爬虫爬取美女图片
- python爬虫入门教程之点点美女图片爬虫代码分享
- python爬虫抓取新华网新闻并自动生成word文档
- python编写的自动获取代理IP列表的爬虫-chinaboywg-ChinaUnix博客
- python爬虫自动搜索下载游民今日搞笑图集
- Python包装网页微信API并实现简单自动回复
- [Python爬虫] Selenium自动访问Firefox和Chrome并实现搜索截图
- 自学Python十 爬虫实战三(美女福利续)
- python制作花瓣网美女图片爬虫
- 我的第一个python爬虫程序(从百度贴吧自动下载图片)
- Python小爬虫-自动下载三亿文库文档
- Python3.x爬虫教程:爬网页、爬图片、自动登录