MapReduce实例之PageRank
2016-09-26 08:25
211 查看
PageRank原理
维基百科 https://en.wikipedia.org/wiki/PageRank
浅析PageRank算法 http://blog.codinglabs.org/articles/intro-to-pagerank.html
PageRank算法 http://blog.csdn.net/hguisu/article/details/7996185
PageRank算法简介及Map-Reduce实现 http://blog.sae.sina.com.cn/archives/4576
HDFS目录结构
input/PageLinks
PageLinks存储的是每一个页面链接到其它页面的数据
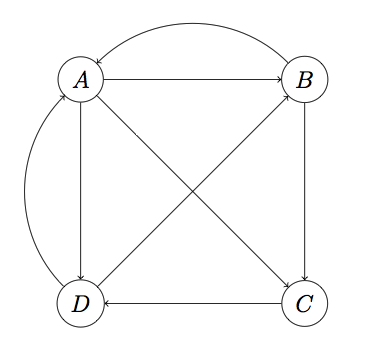
存储示例:
input/Pages
Pages存储的是所有的页面数据
存储示例:
output/PageCount
PageCount存储的是所有的页面总计数
output/PageMatrix
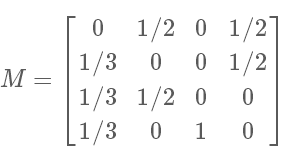
PageMatrix存储的是所有页面的转移稀疏矩阵数据
output/PageRank1
交替计算新的PageRank值输出结果
output/PageRank2
交替计算新的PageRank值输出结果
PageMatrix: 依据PageLinks资料计算M概率转移矩阵
Mapper input: LongWritable, Text; output: Text, Text
input: (0, (A,B,C,D)) =>output: (A, B)(A,C)(A,D)
PageMatrixMapper.java
Reducer input: Text, Text; output: Text, PageRankWritable
input: (A, (B,C,D)) => output: (B, (M,1/3)), (C,(M,1/3)),(D,(M,1/3))
PageMatrixReducer.java
PageRankWritable属性定义
tag: String;
value: Double;
PageRankWritable.java
PageMatrix.java
在Hadoop中运行
PageCount: 依据Pages资料计算总页数
Mapper input: LongWritable, Text; output: Text, LongWritable
input: (0, A) => output: (PC, 1)
input: (1, B) => output: (PC, 1)
PageCountMapper.java
此处需要设置Combiner以大大降低磁盘和网络IO
Combiner与Reducer是同一个类
Reducer input: Text, LongWritable; output: Text, LongWritable
input: (PC, 1) (PC, 1) => output: (PC, 2)
PageCountReducer.java
PageCount.java
在Hadoop中运行
依据Pages和PageCount计算V网页排名初始值PageRank值
Mapper input: LongWritable, Text; output: Text, LongWritable
PageCount值加载到内存
input: (0, A) => output: (A, 1/PageCount)
input: (1, B) => output: (B, 1/PageCount)
InitPageRankMapper.java
没有Reducer类
InitPageRank.java
在Hadoop中运行
依据PageMatrix和PageRank值计算新的PageRank值(循环调用)
Mapper input: LongWritable, Text; output: Text, PageRankWritable
input: (0, (A, M, 1/3)) => output: (A, (M, 1/3))
input: (1, (A, M, 1/3)) => output: (A, (M, 1/2))
input: (2, (A, V, 1/PageCount)) => output: (A, (V, 1/PageCount))
PageRankMapper.java
设置Combiner,合并Mapper输出资料
PageRankCombiner.java
Reducer input: Text, PageRankWritable; output: Text, PageRankWritable
input: (A, [(M, 1/3), (M, 1/2), (V, 1/N)]) => output: (A, (V, ((1 - Q) x (1/3 + 1/2) x V) + E x (Q/N))
N = PageCount值(加载到内存)
M = PageLinks转移概率值
Q = 0.15(心灵转移概率值)
E = 1(N维单位向量)
V = 上次PageRank值
算法描述如下:
V′=(1−Q)(MV)+EQN
PageRankReducer.java
PageRank.java
在Hadoop中运行
源代码下载地址
https://git.oschina.net/elbertmalone/PageRank.git
维基百科 https://en.wikipedia.org/wiki/PageRank
浅析PageRank算法 http://blog.codinglabs.org/articles/intro-to-pagerank.html
PageRank算法 http://blog.csdn.net/hguisu/article/details/7996185
PageRank算法简介及Map-Reduce实现 http://blog.sae.sina.com.cn/archives/4576
HDFS目录结构
input/PageLinks
PageLinks存储的是每一个页面链接到其它页面的数据
存储示例:
A,B,C,D B,A,C C,D D,A,B
input/Pages
Pages存储的是所有的页面数据
存储示例:
A B C D
output/PageCount
PageCount存储的是所有的页面总计数
output/PageMatrix
PageMatrix存储的是所有页面的转移稀疏矩阵数据
output/PageRank1
交替计算新的PageRank值输出结果
output/PageRank2
交替计算新的PageRank值输出结果
PageMatrix: 依据PageLinks资料计算M概率转移矩阵
Mapper input: LongWritable, Text; output: Text, Text
input: (0, (A,B,C,D)) =>output: (A, B)(A,C)(A,D)
PageMatrixMapper.java
package org.feather.mapreduce.PageRank;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class PageMatrixMapper extends Mapper<LongWritable, Text, Text, Text> {
private Text outputKey = new Text();
private Text outputValue = new Text();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String lineValue = value.toString();
String[] values = lineValue.split(",");
if (values.length < 2) {
return;
}
int index = 0;
for (String val : values) {
if (index == 0) {
outputKey.set(val);
} else {
outputValue.set(val);
context.write(outputKey, outputValue);
}
index++;
}
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
}
}Reducer input: Text, Text; output: Text, PageRankWritable
input: (A, (B,C,D)) => output: (B, (M,1/3)), (C,(M,1/3)),(D,(M,1/3))
PageMatrixReducer.java
package org.feather.mapreduce.PageRank;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class PageMatrixReducer extends
Reducer<Text, Text, Text, PageRankWritable> {
private Text outputKey = new Text();
private PageRankWritable outputValue = new PageRankWritable();
private ArrayList<String> outputKeys = new ArrayList<String>();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int length = 0;
outputKeys.clear();
for (Text value : values) {
outputKeys.add(value.toString());
length++;
}
if (length == 0) {
return;
}
for (String outKey : outputKeys) {
outputKey.set(outKey);
outputValue.set("M", 1D / length);
context.write(outputKey, outputValue);
}
}
}PageRankWritable属性定义
tag: String;
value: Double;
PageRankWritable.java
package org.feather.mapreduce.PageRank;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class PageRankWritable implements WritableComparable<PageRankWritable> {
private String tag;
private Double value;
public String getTag() {
return tag;
}
public void setTag(String tag) {
this.tag = tag;
}
public Double getValue() {
return value;
}
public void setValue(Double value) {
this.value = value;
}
public void set(String tag, Double value) {
this.setTag(tag);
this.setValue(value);
}
public PageRankWritable() {
}
public PageRankWritable(String tag, Double value) {
this.set(tag, value);
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.tag);
out.writeDouble(this.value);
}
@Override
public void readFields(DataInput in) throws IOException {
this.tag = in.readUTF();
this.value = in.readDouble();
}
@Override
public int compareTo(PageRankWritable o) {
int comp = this.getTag().compareTo(o.getTag());
if (comp != 0) {
return comp;
}
return this.getValue().compareTo(o.getValue());
}
@Override
public String toString() {
return tag + "," + value.toString();
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((tag == null) ? 0 : tag.hashCode());
result = prime * result + ((value == null) ? 0 : value.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
PageRankWritable other = (PageRankWritable) obj;
if (tag == null) {
if (other.tag != null)
return false;
} else if (!tag.equals(other.tag))
return false;
if (value == null) {
if (other.value != null)
return false;
} else if (!value.equals(other.value))
return false;
return true;
}
}PageMatrix.java
package org.feather.mapreduce.PageRank;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class PageMatrix extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int status = ToolRunner.run(configuration, new PageMatrix(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Configuration configuration = this.getConf();
Job job = Job.getInstance(configuration, this.getClass()
.getSimpleName());
job.setJarByClass(this.getClass());
Path inputPath = new Path(args[0]);
FileInputFormat.addInputPath(job, inputPath);
job.setMapperClass(PageMatrixMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(PageMatrixReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(PageRankWritable.class);
Path outputPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outputPath);
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1;
}
}在Hadoop中运行
$ bin/hdfs dfs -rm -r output/PageMatrix $ bin/yarn jar jars/PageRank.jar org.feather.mapreduce.PageRank.PageMatrix input/PageLinks output/PageMatrix
PageCount: 依据Pages资料计算总页数
Mapper input: LongWritable, Text; output: Text, LongWritable
input: (0, A) => output: (PC, 1)
input: (1, B) => output: (PC, 1)
PageCountMapper.java
package org.feather.mapreduce.PageRank;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class PageCountMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
private Text outputKey = new Text();
private LongWritable outputValue = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
outputKey.set("PC");
outputValue.set(1);
context.write(outputKey, outputValue);
}
}此处需要设置Combiner以大大降低磁盘和网络IO
Combiner与Reducer是同一个类
Reducer input: Text, LongWritable; output: Text, LongWritable
input: (PC, 1) (PC, 1) => output: (PC, 2)
PageCountReducer.java
package org.feather.mapreduce.PageRank;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class PageCountReducer extends
Reducer<Text, LongWritable, Text, LongWritable> {
private Text outputKey = new Text();
private LongWritable outputValue = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Context context) throws IOException, InterruptedException {
Long count = 0L;
for (LongWritable value : values) {
count += value.get();
}
outputKey.set(key);
outputValue.set(count);
context.write(outputKey, outputValue);
}
}PageCount.java
package org.feather.mapreduce.PageRank;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class PageCount extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
Path inputPath = new Path(args[0]);
FileInputFormat.addInputPath(job, inputPath);
job.setMapperClass(PageCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setCombinerClass(PageCountReducer.class);
job.setReducerClass(PageCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
Path outputPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outputPath);
boolean isSuccessful = job.waitForCompletion(true);
return isSuccessful ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new PageCount(), args);
System.exit(status);
}
}在Hadoop中运行
$ bin/hdfs dfs -rm -r output/PageCount $ bin/yarn jar jars/PageRank.jar org.feather.mapreduce.PageRank.PageCount input/Pages output/PageCount
依据Pages和PageCount计算V网页排名初始值PageRank值
Mapper input: LongWritable, Text; output: Text, LongWritable
PageCount值加载到内存
input: (0, A) => output: (A, 1/PageCount)
input: (1, B) => output: (B, 1/PageCount)
InitPageRankMapper.java
package org.feather.mapreduce.PageRank;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashMap;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class InitPageRankMapper extends
Mapper<LongWritable, Text, Text, PageRankWritable> {
private HashMap<String, Long> pageCount = new HashMap<String, Long>();
private Text outputKey = new Text();
private PageRankWritable outputValue = new PageRankWritable();
@SuppressWarnings("deprecation")
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
BufferedReader br = null;
String pageCountLine = null;
Path[] uris = context.getLocalCacheFiles();
for (Path uri : uris) {
if (uri.toString().endsWith("part-r-00000")) {
br = new BufferedReader(new FileReader(uri.toString()));
while (null != (pageCountLine = br.readLine())) {
String[] counts = pageCountLine.split("\t");
if (counts.length == 2) {
String key = counts[0];
Long value = Long.valueOf(counts[1]);
pageCount.put(key, value);
}
}
}
}
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
Long count = pageCount.get("PC");
if (count == null) {
return;
}
outputKey.set(value);
outputValue.set("V", 1D / count);
context.write(outputKey, outputValue);
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
pageCount.clear();
pageCount = null;
}
}没有Reducer类
InitPageRank.java
package org.feather.mapreduce.PageRank;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class InitPageRank extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
job.addCacheFile(new Path(args[0]).toUri());
job.setNumReduceTasks(0);
Path inputPath = new Path(args[1]);
FileInputFormat.addInputPath(job, inputPath);
job.setMapperClass(InitPageRankMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PageRankWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(PageRankWritable.class);
Path outputPath = new Path(args[2]);
FileOutputFormat.setOutputPath(job, outputPath);
boolean isSuccessful = job.waitForCompletion(true);
return isSuccessful ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new InitPageRank(), args);
System.exit(status);
}
}在Hadoop中运行
$ bin/hdfs dfs -rm -r output/PageRank1 $ bin/yarn jar jars/PageRank.jar org.feather.mapreduce.PageRank.InitPageRank output/PageCount/part-r-00000 input/Pages output/PageRank1
依据PageMatrix和PageRank值计算新的PageRank值(循环调用)
Mapper input: LongWritable, Text; output: Text, PageRankWritable
input: (0, (A, M, 1/3)) => output: (A, (M, 1/3))
input: (1, (A, M, 1/3)) => output: (A, (M, 1/2))
input: (2, (A, V, 1/PageCount)) => output: (A, (V, 1/PageCount))
PageRankMapper.java
package org.feather.mapreduce.PageRank;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class PageRankMapper extends
Mapper<LongWritable, Text, Text, PageRankWritable> {
private Text outputKey = new Text();
private PageRankWritable outputValue = new PageRankWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String valueLine = value.toString();
String[] values = valueLine.split("\t");
if (values.length != 2) {
return;
}
String[] outputValues = values[1].split(",");
if (outputValues.length != 2) {
return;
}
outputKey.set(values[0]);
outputValue.set(outputValues[0], Double.valueOf(outputValues[1]));
context.write(outputKey, outputValue);
}
}设置Combiner,合并Mapper输出资料
PageRankCombiner.java
package org.feather.mapreduce.PageRank;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class PageRankCombiner extends
Reducer<Text, PageRankWritable, Text, PageRankWritable> {
private Text outputKey = new Text();
private PageRankWritable outputValue = new PageRankWritable();
@Override
protected void reduce(Text key, Iterable<PageRankWritable> values,
Context context) throws IOException, InterruptedException {
Double M = 0D;
Double V = 0D;
for (PageRankWritable value : values) {
if (value.getTag().equals("M")) {
M += value.getValue();
}
if (value.getTag().equals("V")) {
V += value.getValue();
}
}
outputKey.set(key.toString());
outputValue.set("M", M);
context.write(outputKey, outputValue);
outputKey.set(key.toString());
outputValue.set("V", V);
context.write(outputKey, outputValue);
}
}Reducer input: Text, PageRankWritable; output: Text, PageRankWritable
input: (A, [(M, 1/3), (M, 1/2), (V, 1/N)]) => output: (A, (V, ((1 - Q) x (1/3 + 1/2) x V) + E x (Q/N))
N = PageCount值(加载到内存)
M = PageLinks转移概率值
Q = 0.15(心灵转移概率值)
E = 1(N维单位向量)
V = 上次PageRank值
算法描述如下:
V′=(1−Q)(MV)+EQN
PageRankReducer.java
package org.feather.mapreduce.PageRank;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashMap;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
@SuppressWarnings("deprecation")
public class PageRankReducer extends
Reducer<Text, PageRankWritable, Text, PageRankWritable> {
private HashMap<String, Long> pageCount = new HashMap<String, Long>();
private Text outputKey = new Text();
private PageRankWritable outputValue = new PageRankWritable();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
BufferedReader br = null;
String pageCountLine = null;
Path[] uris = context.getLocalCacheFiles();
for (Path uri : uris) {
if (uri.toString().endsWith("part-r-00000")) {
br = new BufferedReader(new FileReader(uri.toString()));
while (null != (pageCountLine = br.readLine())) {
String[] counts = pageCountLine.split("\t");
if (counts.length == 2) {
String key = counts[0];
Long value = Long.valueOf(counts[1]);
pageCount.put(key, value);
}
}
}
}
}
@Override
protected void reduce(Text key, Iterable<PageRankWritable> values,
Context context) throws IOException, InterruptedException {
Double N = pageCount.get("PC").doubleValue();
Double Q = 0.15D;
Double E = 1D;
Double M = 0D;
Double V = 0D;
if (N == null || N == 0) {
return;
}
for (PageRankWritable value : values) {
if (value.getTag().equals("M")) {
M += value.getValue();
}
if (value.getTag().equals("V")) {
V += value.getValue();
}
}
Double value = (1D - Q) * M * V + E * (Q / N);
outputKey.set(key.toString());
outputValue.set("V", value);
context.write(outputKey, outputValue);
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
pageCount.clear();
pageCount = null;
}
}PageRank.java
package org.feather.mapreduce.PageRank;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class PageRank extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
job.addCacheFile(new Path(args[0]).toUri());
Path inputPath1 = new Path(args[1]);
FileInputFormat.addInputPath(job, inputPath1);
Path inputPath2 = new Path(args[2]);
FileInputFormat.addInputPath(job, inputPath2);
job.setMapperClass(PageRankMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PageRankWritable.class);
job.setCombinerClass(PageRankCombiner.class);
job.setReducerClass(PageRankReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(PageRankWritable.class);
Path outputPath = new Path(args[3]);
FileOutputFormat.setOutputPath(job, outputPath);
boolean isSuccessful = job.waitForCompletion(true);
return isSuccessful ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new PageRank(), args);
System.exit(status);
}
}在Hadoop中运行
$ bin/hdfs dfs -rm -r output/PageRank2 $ bin/yarn jar jars/PageRank.jar org.feather.mapreduce.PageRank.PageRank hdfs://hadoop01.malone.com:8020/user/hadoop/output/PageCount/part-r-00000 output/PageMatrix/part-r-00000 output/PageRank1/part-m-00000 output/PageRank2
$ bin/hdfs dfs -rm -r output/PageRank1 $ bin/yarn jar jars/PageRank.jar org.feather.mapreduce.PageRank.PageRank hdfs://hadoop01.malone.com:8020/user/hadoop/output/PageCount/part-r-00000 output/PageMatrix/part-r-00000 output/PageRank2/part* output/PageRank1
源代码下载地址
https://git.oschina.net/elbertmalone/PageRank.git

相关文章推荐
- Hadoop_2.1.0 MapReduce序列图
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- 交换机升级排障实例
- C#递归算法之分而治之策略
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- C#算法之大牛生小牛的问题高效解决方法
- C#算法函数:获取一个字符串中的最大长度的数字
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- 经典排序算法之冒泡排序(Bubble sort)代码
- sql2008启动代理未将对象应用到实例解决方案
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解