hadoop 2.x之HDFS HA讲解之十WEB UI监控页面分析和查看NN与JN存储的编辑日志
2016-09-25 15:38
288 查看
到现在为止,我们已经配置了hadoop的HA,让我们通过页面去查看下hadoop的文件系统。
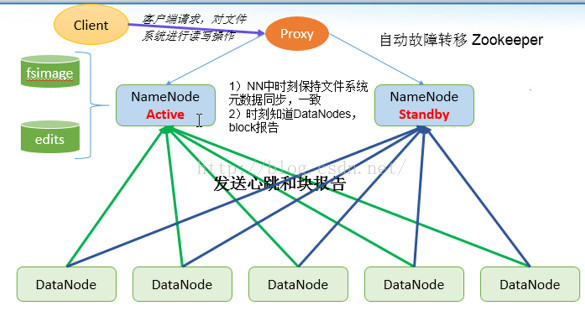
1. 分析active namenode和standby namenode对客户端服务的情况。
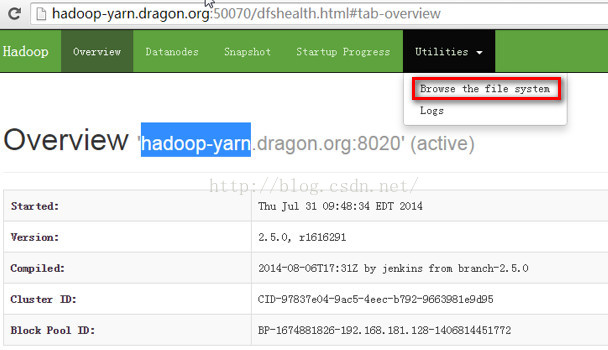
我们可以清楚看到hadoop文件系统的目录结构:
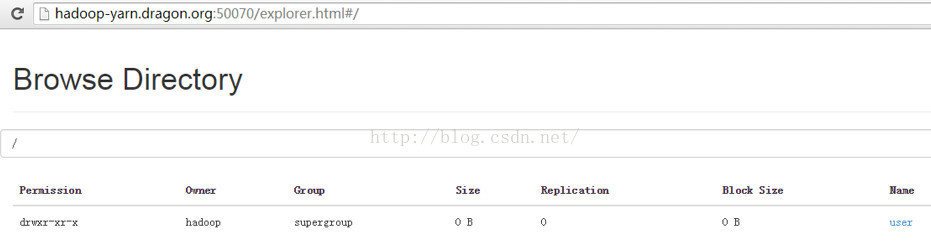
以上我们都是通过active的namenode访问hadoop的,那么如果我们通过standby namenode可不可以访问hadoop呢?
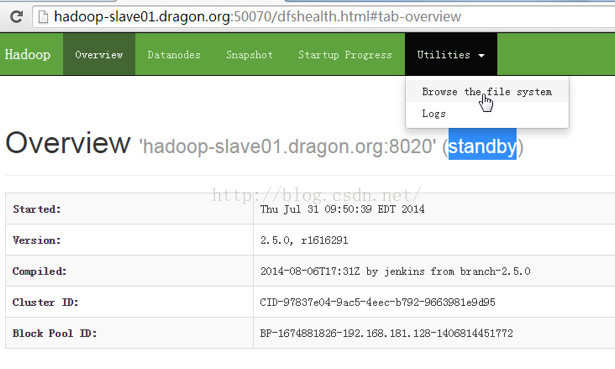
接下来我们看到,通过standby namenode是无法访问hadoop的文件系统的。根据提示,我们知道,standby namenode是不支持读操作的。
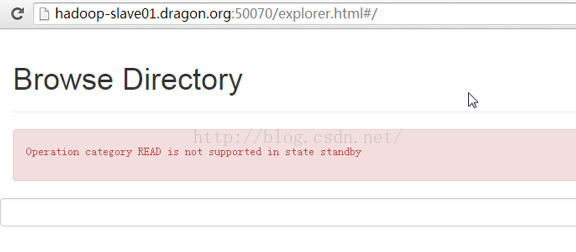
这也就证明了,在HA机制中,standby namenode是不能给客户端提供服务的。
2. 分析active namenode和standby namenode的datanode的情况。
在我们的HA配置中,总共有3个datanode,这3个datanode同时为active namenode和standby namenode服务。
第一:我们首先分析下standby namenode下的datanode个数情况以及standby namenode是从哪里读取编辑日志的。
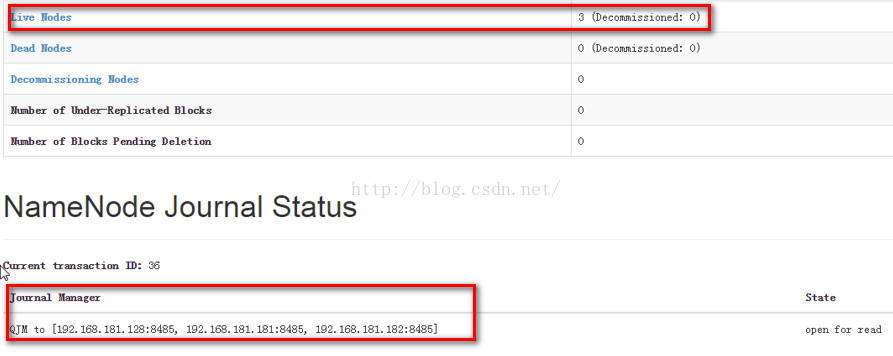
通过上图我们知道,standby namenode下面有3个datanode, 并且standby namenode是通过QJM的方式读取编辑日志的。
第二,我们来查看一下active namenode是如何向三个journal node写编辑日志的。
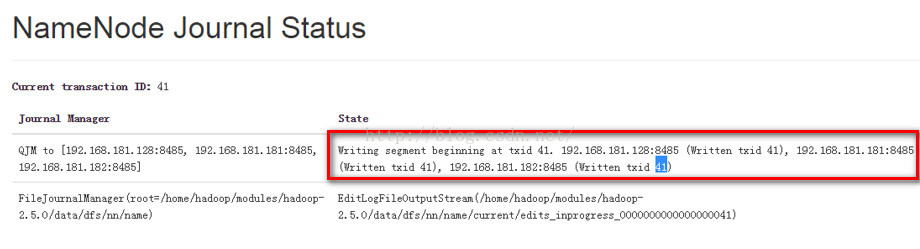
我们可以看到当前的active namenode正在向3个journal node写编辑日志,当前的编辑日志的transaction id 是 41。
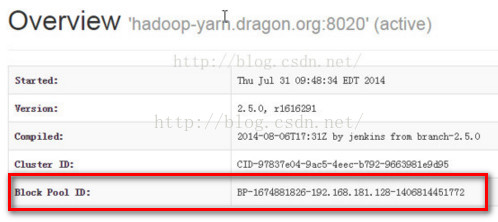
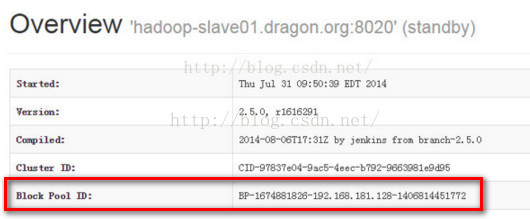
第三,我们来对比下active namenode和standby namenode的cluster ID,必定是相同的。
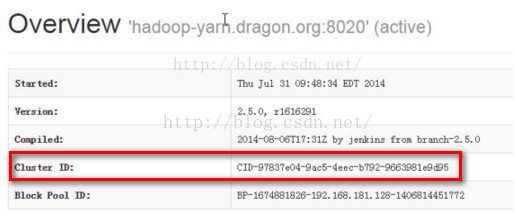
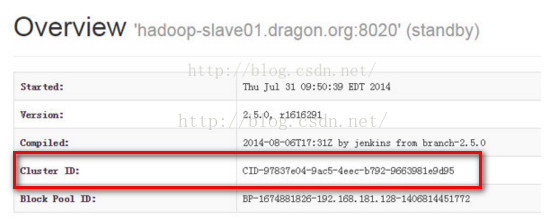
第四:对比Block ID,我们知道Block ID存储的是hadoop分布式文件系统的元信息,因为standby namenode是active namenode的备份节点,
他们管理的元信息应该是一样的,所以他们的Block ID应该也是相同的。
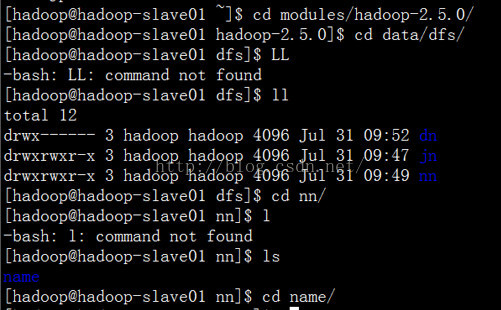
第五:现在我们去active namenode的存储目录中去看下。
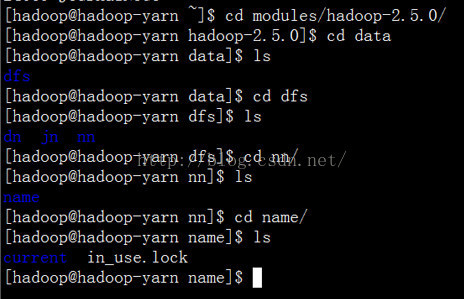
有一个in_user.lock的文件,证明当前这个文件正在被使用。current 目录下存放的是当前的active namenode下存放的映像文件和编辑日志文件。
我们查看下current 目录下的文件:
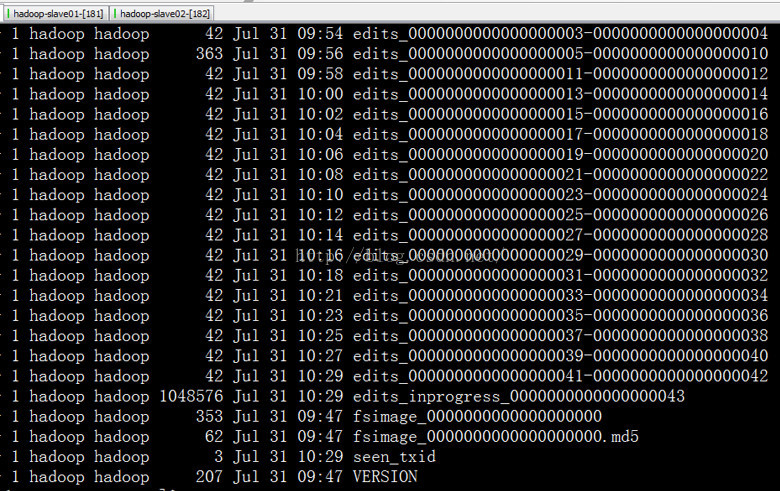
有人肯定会有疑问,我们的编辑日志文件不是存放在journal node里面吗?为什么active namenode里面也会有编辑日志文件呢?
让我们来看下面的一张图,来解释下。我们发现,编辑日志文件在active namenode端始终是有的。当客户端请求namenode的时候,
namenode不仅将编辑日志写到本地,还会将编辑日志文件写QJM的节点中。
第六:现在我们去standby namenode的存储目录中去看下。
进入到current目录下面:
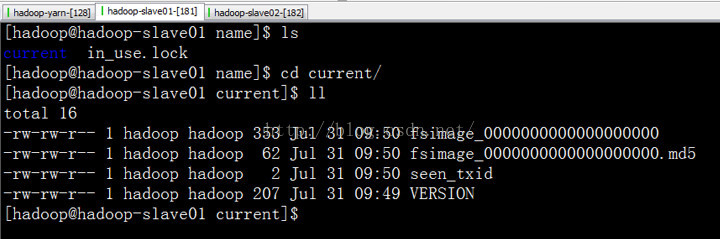
我们发现,这里只有映像文件,没有编辑日志文件。这里的映像文件,我们在启动的时候,使用的一个命令,将active namenode的映像文件完全复制过来的。

第七:现在我们去journal node为当前的namespace(ns1)创建的存储目录中去看下。

至于为什么要这么配置,官方文档有一个很好的说明:
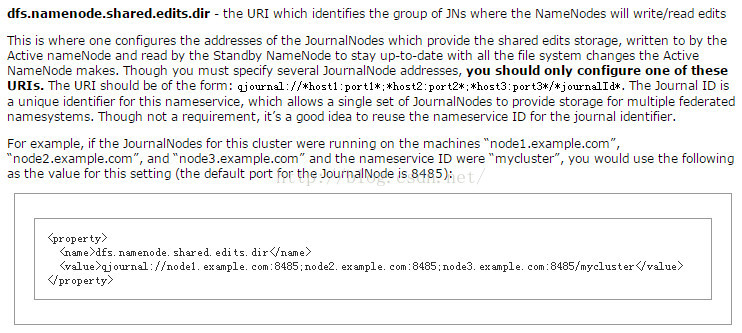
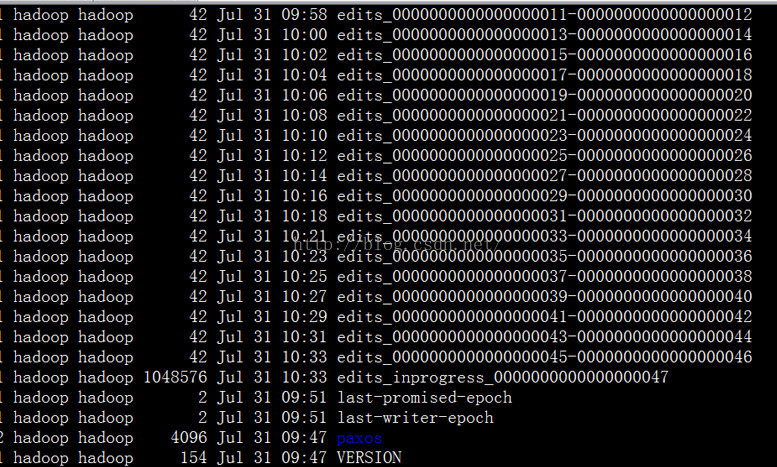
我们先进去看下这个目录下存放的是什么?里面存放的应该是编辑日志。
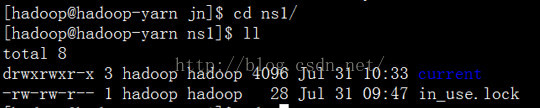
首先是current 文件夹,然后current下面存放的是编辑日志。
1. 分析active namenode和standby namenode对客户端服务的情况。
我们可以清楚看到hadoop文件系统的目录结构:
以上我们都是通过active的namenode访问hadoop的,那么如果我们通过standby namenode可不可以访问hadoop呢?
接下来我们看到,通过standby namenode是无法访问hadoop的文件系统的。根据提示,我们知道,standby namenode是不支持读操作的。
这也就证明了,在HA机制中,standby namenode是不能给客户端提供服务的。
2. 分析active namenode和standby namenode的datanode的情况。
在我们的HA配置中,总共有3个datanode,这3个datanode同时为active namenode和standby namenode服务。
第一:我们首先分析下standby namenode下的datanode个数情况以及standby namenode是从哪里读取编辑日志的。
通过上图我们知道,standby namenode下面有3个datanode, 并且standby namenode是通过QJM的方式读取编辑日志的。
第二,我们来查看一下active namenode是如何向三个journal node写编辑日志的。
我们可以看到当前的active namenode正在向3个journal node写编辑日志,当前的编辑日志的transaction id 是 41。
第三,我们来对比下active namenode和standby namenode的cluster ID,必定是相同的。
第四:对比Block ID,我们知道Block ID存储的是hadoop分布式文件系统的元信息,因为standby namenode是active namenode的备份节点,
他们管理的元信息应该是一样的,所以他们的Block ID应该也是相同的。
第五:现在我们去active namenode的存储目录中去看下。
有一个in_user.lock的文件,证明当前这个文件正在被使用。current 目录下存放的是当前的active namenode下存放的映像文件和编辑日志文件。
我们查看下current 目录下的文件:
有人肯定会有疑问,我们的编辑日志文件不是存放在journal node里面吗?为什么active namenode里面也会有编辑日志文件呢?
让我们来看下面的一张图,来解释下。我们发现,编辑日志文件在active namenode端始终是有的。当客户端请求namenode的时候,
namenode不仅将编辑日志写到本地,还会将编辑日志文件写QJM的节点中。
第六:现在我们去standby namenode的存储目录中去看下。
进入到current目录下面:
我们发现,这里只有映像文件,没有编辑日志文件。这里的映像文件,我们在启动的时候,使用的一个命令,将active namenode的映像文件完全复制过来的。
第七:现在我们去journal node为当前的namespace(ns1)创建的存储目录中去看下。
至于为什么要这么配置,官方文档有一个很好的说明:
我们先进去看下这个目录下存放的是什么?里面存放的应该是编辑日志。
首先是current 文件夹,然后current下面存放的是编辑日志。

相关文章推荐
- hadoop 2.x之HDFS HA讲解之九HDFS HA测试启动服务进程、页面监控查看和解决问题
- hadoop 2.x之HDFS HA讲解之八HDFS HA测试启动NameNode遇见错误分析解决
- hadoop 2.x之HDFS HA讲解之五 HA管理命令、元数据同步和基于QJM方式存储的硬件配置说明
- Hadoop HDFS源码分析 读取命名空间镜像和编辑日志数据
- hadoop状态分析系统chukwa (日志收集存储分析系统)
- Hadoop0.23.0初探3---HDFS NN,SNN,BN和HA
- 用服务器日志监控软件、服务器日志分析工具软件教你如何查看服务器日志?
- hadoop 2.x之HDFS HA讲解之十二基于已有HDFS集群配置NN HA
- hadoop源码解读namenode高可靠:HA;web方式查看namenode下信息;dfs/data决定datanode存储位置
- Hadoop深入学习:HDFS主要流程——SNN合并fsimage和编辑日志
- 揭秘FaceBook Puma演变及发展——FaceBook公司的实时数据分析平台是建立在Hadoop 和Hive的基础之上,这个根能立稳吗?hive又是sql的Map reduce任务拆分,底层还是依赖hbase和hdfs存储
- HDFS源码分析EditLog之获取编辑日志输入流
- hadoop源代码解读namenode高可靠:HA;web方式查看namenode下信息;dfs/data决定datanode存储位置
- hadoop 2.x之HDFS HA讲解之十一测试failover故障转移和隔离、使用sshfence隔离的配置ssh无密钥登陆
- Hadoop0.23.0初探3---HDFS NN,SNN,BN和HA
- Hadoop分布式文件存储系统HDFS高可用HA搭建(何志雄)
- HDFS源码分析之编辑日志编辑相关双缓冲区EditsDoubleBuffer
- Hadoop监控页面查看Hive的完整SQL
- hadoop hdfs HA原理讲解、脑裂问题产生
- Hadoop0.23.0初探3---HDFS NN,SNN,BN和HA