Hadoop配置以及WordCount示例
2016-09-24 10:59
267 查看
我使用的Hadoop版本是2.7.3,版本之间有差异,可能并不适用于所有人。
环境:
Linux Ubuntu
Eclipse
双手
大脑
耐心!!!
说出来也不怕你们笑话,光是伪分布式配置加这一个例子,折腾了我两天。
官方的文档默认是最新版本的,如果要看老版本,可以把URL中的current修改为rx.x.x比如r2.7.3,这样就可以看到对应版本的介绍。
1.首先安装jdk,并配置环境。
2.然后要安装ssh,centos下是默认就安装了,ubuntu我的只有ssh-client,再装一个ssh-server就可以。执行sudo apt-get install openssh-server即可。
3.配置hadoop-env.sh(我的在etc/hadoop下),将java路径写入
export JAVA_HOME=your path
4.在etc/hadoop/core-site.xml中添加如下配置:
5.登录ssh ssh localhost 退出的话,执行exit即可
无密码登录:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
6.格式化文件系统 bin.hdfs namenode -format
7.启动服务 sbin/start-dfs.sh
8.创建目录:
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/frank(your name)
必须要分两步执行,一次只能创建一层目录。
9.在当前目录创建文件并上传至分布式文件系统
mkdir input
cd input
vi h1.txt
输入一些单词并保存
同理生成另一个文件
然后执行bin/hdfs dfs -put input input上传文件
hadoop端完成,配置eclipse端:
首先下载与你的hadoop版本匹配的hadoop-eclipse-plugin放到eclipse的plugin中,重启eclipse,在window-->preferences中会发现多了一个hadoop map/reduce,在里面配置你的hadoop的路径
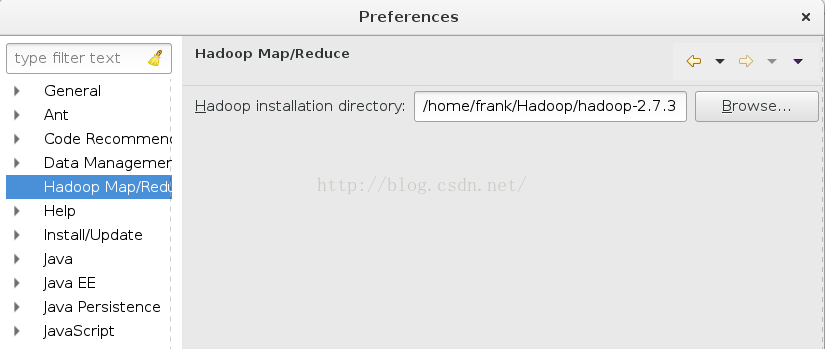
保存之后在window-->show view中找出map/reduce location视图,然后点击右边的蓝色小象,

如果有的话,直接点左边的那个配置按钮,将端口改成与core-site.xml中一致
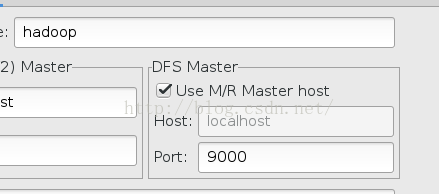
保存后在eclipse左端会出现DFS,如图:

只有在hadoop服务启动时,才会刷新出目录,否则会出现java.net.XXXXXXX错误,并且出现无法连接到localhost:9000/,意思是无法连接到hadoop。
然后新建一个map/reduce project,使用WordCount范例,代码如下:
然后右键run as-->run configurations,配置参数:

保存后,选择run as-->run on hadoop,这个地方不要选成java application。
运行结束之后,在hadoop端命令行执行bin/hdfs dfs -cat output/part-r-00000就可以看到运行结果,统计单词出现的次数。好啦,这个简单的例子到此就算运行结束了。各位尽情折腾去吧。Bye~
环境:
Linux Ubuntu
Eclipse
双手
大脑
耐心!!!
说出来也不怕你们笑话,光是伪分布式配置加这一个例子,折腾了我两天。
官方的文档默认是最新版本的,如果要看老版本,可以把URL中的current修改为rx.x.x比如r2.7.3,这样就可以看到对应版本的介绍。
1.首先安装jdk,并配置环境。
2.然后要安装ssh,centos下是默认就安装了,ubuntu我的只有ssh-client,再装一个ssh-server就可以。执行sudo apt-get install openssh-server即可。
3.配置hadoop-env.sh(我的在etc/hadoop下),将java路径写入
export JAVA_HOME=your path
4.在etc/hadoop/core-site.xml中添加如下配置:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration> 在etc/hadoop/hdfs-site.xml中添加如下配置: <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
5.登录ssh ssh localhost 退出的话,执行exit即可
无密码登录:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
6.格式化文件系统 bin.hdfs namenode -format
7.启动服务 sbin/start-dfs.sh
8.创建目录:
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/frank(your name)
必须要分两步执行,一次只能创建一层目录。
9.在当前目录创建文件并上传至分布式文件系统
mkdir input
cd input
vi h1.txt
输入一些单词并保存
同理生成另一个文件
然后执行bin/hdfs dfs -put input input上传文件
hadoop端完成,配置eclipse端:
首先下载与你的hadoop版本匹配的hadoop-eclipse-plugin放到eclipse的plugin中,重启eclipse,在window-->preferences中会发现多了一个hadoop map/reduce,在里面配置你的hadoop的路径
保存之后在window-->show view中找出map/reduce location视图,然后点击右边的蓝色小象,
如果有的话,直接点左边的那个配置按钮,将端口改成与core-site.xml中一致
保存后在eclipse左端会出现DFS,如图:
只有在hadoop服务启动时,才会刷新出目录,否则会出现java.net.XXXXXXX错误,并且出现无法连接到localhost:9000/,意思是无法连接到hadoop。
然后新建一个map/reduce project,使用WordCount范例,代码如下:
import java.io.IOException;
public class WordCount {
public static class WordCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}然后右键run as-->run configurations,配置参数:
保存后,选择run as-->run on hadoop,这个地方不要选成java application。
运行结束之后,在hadoop端命令行执行bin/hdfs dfs -cat output/part-r-00000就可以看到运行结果,统计单词出现的次数。好啦,这个简单的例子到此就算运行结束了。各位尽情折腾去吧。Bye~

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 单机版搭建Hadoop环境图文教程详解
- hadoop常见错误以及处理方法详解
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- Apache Hadoop版本详解
- linux下搭建hadoop环境步骤分享
- hadoop client与datanode的通信协议分析
- hadoop中一些常用的命令介绍
- Hadoop单机版和全分布式(集群)安装
- 用PHP和Shell写Hadoop的MapReduce程序
- hadoop map-reduce中的文件并发操作
- Hadoop1.2中配置伪分布式的实例
- hadoop上传文件功能实例代码
- java结合HADOOP集群文件上传下载
- Hadoop 2.x伪分布式环境搭建详细步骤
- Java访问Hadoop分布式文件系统HDFS的配置说明