基于RNN的个性化电影推荐尝试
2016-09-23 18:34
127 查看
基于RNN的个性化电影推荐尝试
随着深度学习在工业界的应用越来越多,优酷土豆尝试在视频推荐领域中利用深度学习方法,提高视频推荐的准确性,为用户提供优质的视频推荐服务。本次为大家分享在个性化电影推荐上的尝试,利用RNN的序列模型进行用户电影推荐。
目前的序列模型中,比较火和使用的为RNN模型,其在语音识别、机器翻译、文本处理等领域中取到了较好的结果。因此,我们采用了RNN模型进行用户观看序列的建模和预测。
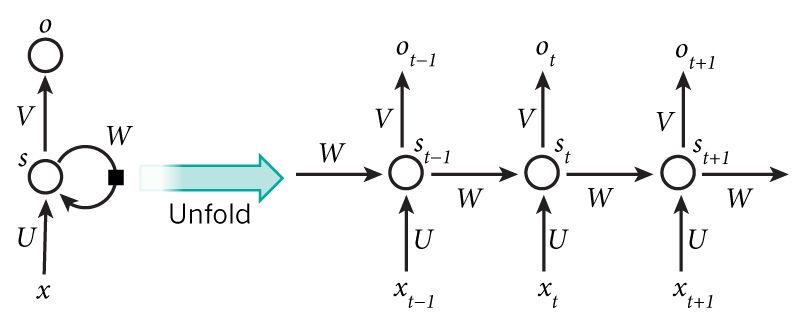
RNNs包含输入单元(Input units),输入集标记为{x0,x1,…,xt,xt+1,…},而输出单元(Output units)的输出集则被标记为{y0,y1,…,yt,yt+1.,..}。RNN还包含隐藏单元(Hidden units),我们将其输出集标记为{s0,s1,…,st,st+1,…},这些隐藏单元完成了最为主要的工作。你会发现,在图中:有一条单向流动的信息流是从输入单元到达隐藏单元的,与此同时另一条单向流动的信息流从隐藏单元到达输出单元。在某些情况下,RNNs会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”,并且隐藏层的输入还包括上一隐藏层的状态,即隐藏层内的节点可以自连也可以互连。
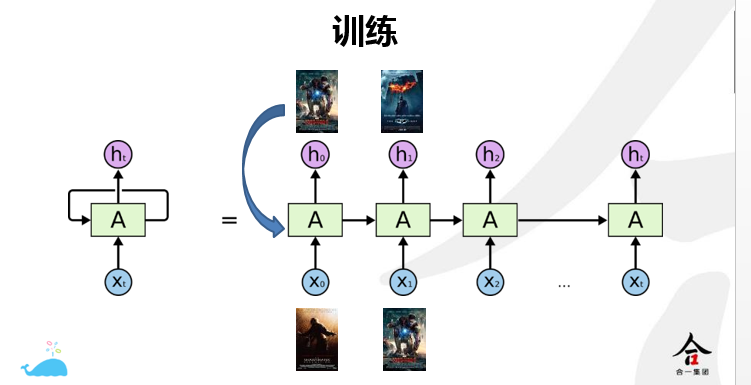
在电影推荐中,我们要解决的是根据用户历史观看的视频预测用户未来观看的电影,如下图所示:

其实,对于用户和视频数据而言,可用的数据还有用户的画像和视频的画像。为了模型的简化和训练时间的考虑,实验中只采用了用户的观看历史。
首先,定义目标函数,用交叉熵函数定义目标函数:
E=1N∑nylogp+(1−y)log(1−p)
其中,y为label数据,p为用户下一个视频的预测概率。
具体训练流程如图,将视频预测问题转换为序列预测问题,如用户观看历史为v1,v2,v3, 当模型输入为v1,v2时,目标则是最大化视频v3的概率。
试验中样本数量为千万级,视频数为千级别,采用1个LSTM层,50个cell,迭代次数为60。在此配置上,训练时间为40minue。
为了验证其效果,我们在优酷土豆上进行AB小流量测试,发现RNN点击率的收益效果明显。
随着深度学习在工业界的应用越来越多,优酷土豆尝试在视频推荐领域中利用深度学习方法,提高视频推荐的准确性,为用户提供优质的视频推荐服务。本次为大家分享在个性化电影推荐上的尝试,利用RNN的序列模型进行用户电影推荐。
视频推荐问题
目前常用的个性化推荐包括:基于关联规则的推荐算法、基于内容的推荐算法和基于协同过滤的推荐算法。在视频网站中的个性化推荐中,基于协同过滤的个性化推荐算法为主要的推荐算,它能够过滤难以进行机器自动基于内容分析的信息,能够基于一些复杂的难以表达的概念(信息质量、品位)进行过滤。但是协同过滤算法无法处理用户的观看序列信息,不能根据用户的观看序列进行视频的推荐,只是考虑了用户单个观看行为信息。那么如何挖掘用户的观看序列信息,对用户进行更为准确的个性化视频推荐?目前的序列模型中,比较火和使用的为RNN模型,其在语音识别、机器翻译、文本处理等领域中取到了较好的结果。因此,我们采用了RNN模型进行用户观看序列的建模和预测。
RNN模型
本文RNN介绍借鉴了循环神经网络(RNN, Recurrent Neural Networks)介绍,下面部分图和解释来自博客。RNN
RNN模型主要是用来处理序列问题,在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。RNNs包含输入单元(Input units),输入集标记为{x0,x1,…,xt,xt+1,…},而输出单元(Output units)的输出集则被标记为{y0,y1,…,yt,yt+1.,..}。RNN还包含隐藏单元(Hidden units),我们将其输出集标记为{s0,s1,…,st,st+1,…},这些隐藏单元完成了最为主要的工作。你会发现,在图中:有一条单向流动的信息流是从输入单元到达隐藏单元的,与此同时另一条单向流动的信息流从隐藏单元到达输出单元。在某些情况下,RNNs会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”,并且隐藏层的输入还包括上一隐藏层的状态,即隐藏层内的节点可以自连也可以互连。
LSTM
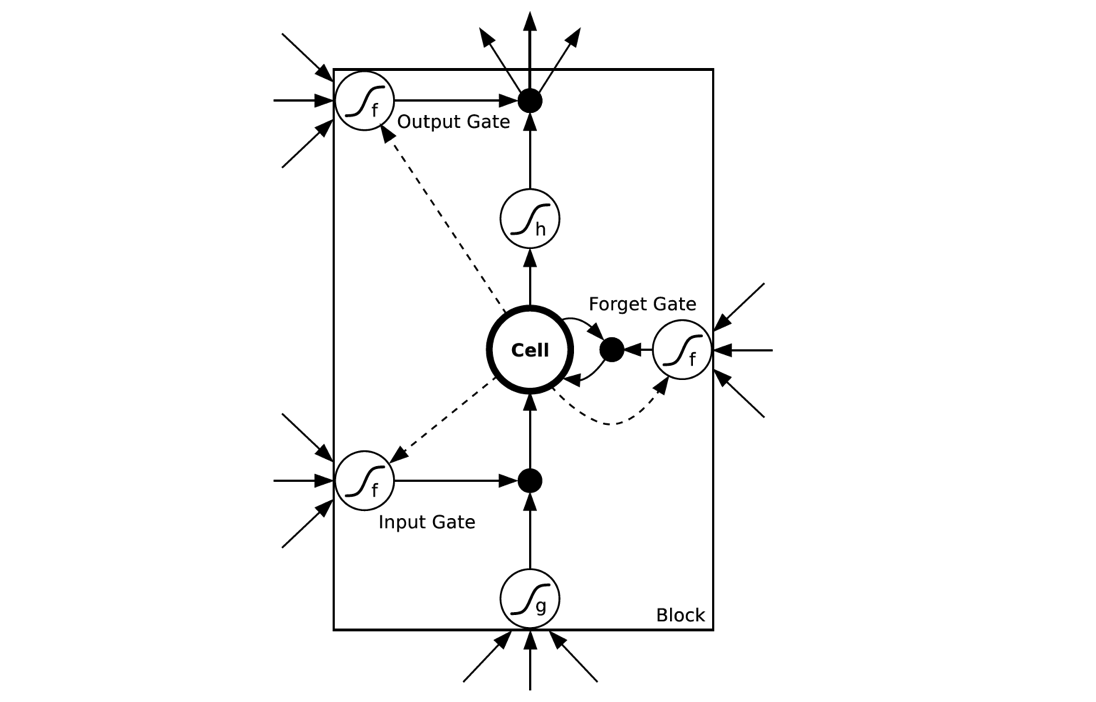
由于在RNN中,更新参数采用的是BPTT方式,当序列长度边长时,会产生梯度消失的问题。为了解决这个问题,产生了LSTM模型。在LSTM模型中,隐藏层变为一个复杂的block,其中记忆结构被称为cells,可以把cells看作是黑盒用以保存当前输入xt之前的保存的状态ht−1,这些cells更加一定的条件决定哪些cell抑制哪些cell兴奋。它们结合前面的状态、当前的记忆与当前的输入。已经证明,该网络结构在对长序列依赖问题中非常有效。LSTMs的网络结构如下图所示。对于LSTMs的学习,参见 Understanding-LSTMs电影推荐应用
以上是关于RNN的简单介绍,如要详细了解,可以参考具体的文献和代码。接下来主要介绍我们如何在优酷土豆电影推荐中使用RNN进行个性化推荐。在电影推荐中,我们要解决的是根据用户历史观看的视频预测用户未来观看的电影,如下图所示:
训练样本
为了解决以上问题,那么我们现在可以拿到用户的数据有什么?显而易见,用户的观看历史我们是可以获得。因此,对于模型的训练数据可以结构化为his(u)={v1,v2,v3,..vn}.其中,v为用户观看的视频,v1,v2.为用户观看时间上的序列。当然,为了数据的准确性,进行了观看历史的清洗,如用户观看视频的播放完成率等。其实,对于用户和视频数据而言,可用的数据还有用户的画像和视频的画像。为了模型的简化和训练时间的考虑,实验中只采用了用户的观看历史。
模型目标
有了上面的数据,接下来就需要对模型进行训练。首先,定义目标函数,用交叉熵函数定义目标函数:
E=1N∑nylogp+(1−y)log(1−p)
其中,y为label数据,p为用户下一个视频的预测概率。
具体训练流程如图,将视频预测问题转换为序列预测问题,如用户观看历史为v1,v2,v3, 当模型输入为v1,v2时,目标则是最大化视频v3的概率。
用户预测
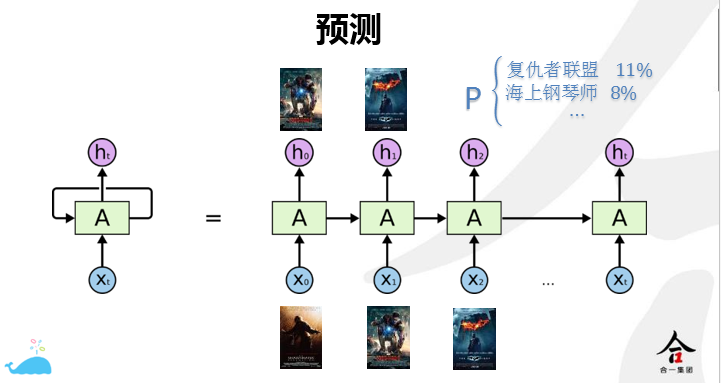
用了模型之后如何使用呢?其实在上面的模型的目标设定时就可以看出。作为一个序列的模型,在进行用户视频预测时,输入用户历史的观看序列,选出用户可能观看的视频(按照预测的概率进行排序)即可。如图所示:实验结果
我们选取了百万级的用户进行采样,构建训练集。并采用tensorflow进行编码实现。由于RNN模型训练周期时间较长,我们使用阿里云的HPC作为训练机器,在M40上进行加速训练。试验中样本数量为千万级,视频数为千级别,采用1个LSTM层,50个cell,迭代次数为60。在此配置上,训练时间为40minue。
为了验证其效果,我们在优酷土豆上进行AB小流量测试,发现RNN点击率的收益效果明显。
总结
虽然RNN在目前的实验中有一定效果,但是由于RNN训练复杂,对于大规模的数据而言计算还是比较困难,对于大规模使用还需要很长的路要走。
相关文章推荐
- 基于RNN的个性化电影推荐尝试
- 微服务应用-基于Spring Cloud和Docker构建电影推荐微服务
- 基于位置的本地商铺个性化推荐
- 基于移动互联网的电子商务个性化推荐的一些思考
- <转>基于Spark Mllib,SparkSQL的电影推荐系统
- 基于Mahout的电影推荐系统
- 微服务应用-基于Spring Cloud和Docker构建电影推荐微服务
- 电影推荐实例--基于协同过滤和DL特征提取的比较
- 基于Spark MLlib平台的协同过滤算法---电影推荐系统
- 个性化推荐基本算法及源码分析(一)— 基于用户的协同过滤
- 基于neighborhood models(item-based) 的个性化推荐系统
- 基于Mahout的电影推荐系统
- 基于Spark Mllib,SparkSQL的电影推荐系统
- 基于混合云存储系统的电影推荐引擎小结
- 基于hadoop的电影推荐结果可视化
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 基于Spark MLlib平台的协同过滤算法---电影推荐系统
- 基于Python库surprise的电影推荐系统
- 基于Spark MLlib平台的协同过滤算法---电影推荐系统
- 微服务应用-基于Spring Cloud和Docker构建电影推荐微服务