基于B+树的数据索引存储
2016-09-22 00:00
288 查看
目前, 索引技术广泛应用于数据库中数字数据的搜索查询, B+树由于其自身的特点决定其适合
应用于数据索引系统. 在 B+树应用中, 其节点记录了每个子节点附加的数据信息, 并将键值和附加
数据相结合. 一棵节点数量很多的 B+树, 在构建过程中时间和空间开销也较大, 因此, 有必要将
B+树 事先写入磁盘. 不同类型的节点所需空间和实际附加数据大小直接关联, 节点读取效率及其存
储介质读取方式直接关联. 为了有效组织树节点信息单元, 可采用多级位图链表方式进行管理[1 - 3] .
B+树特性:
1) B+树中子树节点和关键字的数量相同;
2) 关键字和叶子节点相对应并且是有序的;
3) 非叶子节点不存储数据;
4) 非叶子节点被当做索引部分, 叶子节点包含子树的关键字;
5) 随机和顺序查找可同时进行[4 - 6] .
页标准大小是5 1 2字节, 如果节点附加信息存储在其他存储单元, 则节点的物理大小将远小于一个物
理页. B+树节点分为根节点、 内节点和叶子节点3种类型. 这3种节点的物理单元大小可能不同. 作
为 B+树存储, 一个系统需要存储的 B+树数量并不确定. 如果选择对 B+树3种节点类型分开存储,
并对多个 B+树进行统一管理, 则结构清晰且易于维护. 每棵 B+树的分配将由3种不同管理类型负
责分配, 由维护这3类节点的系统统一删除和分配. 这种方式的弊端是对于任意一棵 B+树存储, 都
可能是分散的. 在访问过程中会对分散在不同物理页的节点进行读取和其他操作, 系统I /O 开销负载
较大. 其中节点删除也会导致存储碎片增多.
系统通过构建一种上一层位图管理方法实现文件中节点链表的申请与释放操作. B+树中一些节
点的位图区在系统数据初始化时被记录, 同时构建相应级别的管理模型.
节点存储在连续页面上, 并对 B+树节点种类实行单一管理. 这样可在操作过程中充分利用系统的页
缓存存储临近节点特性, 增加 B+树下其他节点在缓存中命中的可能性, 从而减少了I /O 负载. 由于
B+树中根节点是唯一的, 因此可为 B+树的根节点与内节点、 外节点配备并共用两种不同的存储空
间[7] . 这样既便于管理又节省了宝贵的存储资源. 根节点的地址分配可依据B+树状态操作. 构建B+
树时把根节点分在叶节点地址中, 当树深度大于1时, 则把根节点分在内节点地址中. 为获得树中页
面节点的各种状态, 把节点页面的使用区域分开单独管理, 这样可提供快速系统处理接口. 因此使用
单独分离标志显示该页区域分配情况.
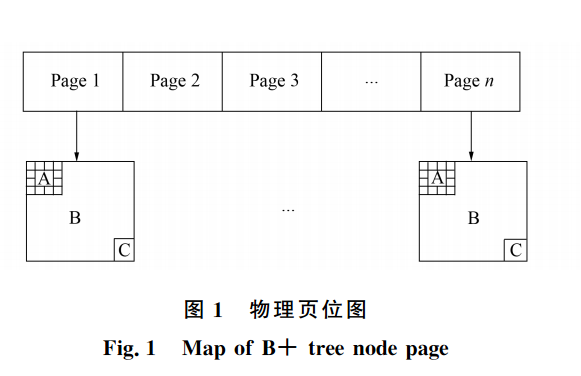
如图1所示, 物理页中存储3个区域: A 表示该物理页内节点区域(B区域)位图; B表示节点存储区域; C表示当前页的下一个关联页链接地址.当有新键值插入时, 先查看该 B+树节点物理页位图起始处, 考虑是否需要构建新节点. 如果需要,则在物理页位图 A 部分查看是否有闲置的空间, 若有则直接插入键值; 若没有, 则把当前节点分成两个叶节点, 把新键值平分到两个叶节点中, 并在两个叶节点的上一层构建新节点. 两个刚生成的叶节点即变为上一层节点的子节点. 本文以物理页为单位存放相异类型的节点, 通过对系统缓存采用优化策略, 把B+树的相关节点存储都尽可能存放在某固定的物理页或某个区域, 这样可使 B+树在存储介质的存放更集中, 同时缩减了I /O 读取次数, 提高了系统效率. 存储系统的物理页都可视为 Ma p位图, 可容纳5 1 2字节的数据, 即可容纳5 1 2个节点[8 - 9] , 并每个 Ma p位图都相关联, 这样使 B+树中节点更易于管理.
的分支因子数量, 提高访问效率. 每个节点都存放节点本身的一些位置信息, 这些位置信息内容有存
储地址及数据存放的相关地址, 因此树中的节点由子节点及节点自身的一些相关数据构成, 节点间通
过记录节点存储位置进行关联. 键值信息单元存储了每个键值相关的附加信息, 这些附加信息按特定
格式存储, B+树只需记录附加信息物理位置, 即时读取.
关系. 在需要时读取, 可减轻系统内存和I /O 负载, 提高系统效率. 在树的操作过程中, 根据所访问的
键值寻找根节点到叶子节点通路, 若 B+树分支节点较多, 可对树中所有节点关键字使用二分查找方
法, 即可找到下一级节点, 最终查找到叶子节点. 数据在随意写入读取过程中, 随机对不同元数据的
读写操作可能会产生较多琐碎数据块, 这些数据块分配在不同的存储页面, 当要读取其中某一数据
时, 需要查阅很多存储页面, 既消耗了大量的缓存资源, 也使查找缓存中数据的命中率极大降低, 同
时使I /O 负担过重, 从而使系统的性能下降. 本文把 B+树中节点所包含的数据存放在整个以物理页
面为单位的存储介质上, 同时使用位图模式支配物理页面的使用, 提高系统的读取效率.
键值在存储单元存放时, 要记录链表中相应节点的地址. 当对其他新键值进行各种操作时, 先使用某种
顺序(或路径)查找到链表中节点位置的地址, 通过对地址中节点的内容进行比较, 再确定新键值的地址,
并记录. 因此, 当有新键值需要做插入或删除操作时, 调整其节点的地址即可, 并且这种调整是有序的.
B+树操作的主要步骤如下:
1) 产生 B+树根节点.
当B+树中有新键值插入时, 先通过键值对比, 找到其要插入节点的地址,
然后将该位置的节点分裂成两个节点, 在其上一层生成根节点, 并记录这些节点的地址信息, 相应
B+树 的位图标志信息也需修改.
2) B+树回写信息.
B+树根节点和叶子节点可能在插入或删除等操作中进行了修改, 但其他路
径上相关节点内容没有变化. 因此, 每个节点都有相应的标志位F l u s h. 若F l u s h=1, 则由根节点对该
叶子节点进行信息回写. 因为根节点存放B+树相关节点的信息, 因此需通过递归回写完成索引过程.
要注意在回写根节点前需把 B+树相关节点位置的数据复制到根节点空间.
3) B+树键值插入操作.
当B+树中有新键值插入时, 先遍历整个页面, 找空闲位置, 把新键值放
在空闲位置, 再查找和新键值大小相近的叶子节点, 看是否有空闲位置, 若有位置则直接插入新键值,
若没有空位置, 则该节点自动分裂成两个新节点, 并把新键值插在新节点位置, 且新节点键值的数量
≥1 / 2键值数. 把新节点中键值大的递归向上插在其上一层节点中, 一直插到根节点位置. 如果根节
点没有空位置, 则根节点也分裂成两个节点, 同时在其上层生成新的根节点.
1) 把找到放置键值 K 叶子节点的索引内容删除. 当前键值后的叶子节点如果为空, 则回收已经
分配的树节点空间; 如果被删除节点键的数量大于或等于 B+树中节点键的最小数量, 则操作结束;
2) 如果被删除叶子节点兄弟节点的键值数小于B+树中节点键最小数量, 则把该节点的键值移到
被删除的叶子节点位置, 合并兄弟节点, 删除父节点位置的键值信息, 其相应的键值也要修改;
3) 若修改后父节点位置的键值和 B+树的条件一致, 删除操作结束; 否则, 一直递归向上到根节
点进行删除操作.
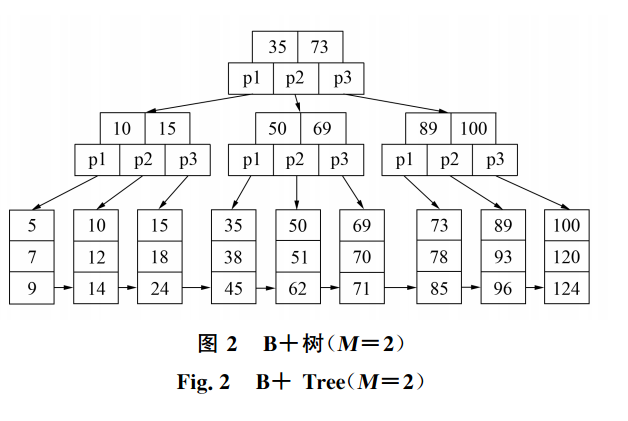
对于以字符串为单位存储键值的情况, 可在存储介质中存储键值内容, 在删除叶子节点而没有影响到内节点的情况下, 作为树的存储, 需为内节点含有相关键值节点做调整, 把键值更换为子树做左节点键值, 更新其与键值的元数据. 图2为对节点删除和调整的过程. 由图 2 可见, 如删除节点 3 5时, 需在查找路径上记录删除键值节点的位置, 最后, 将最左值3 8键值信息写入根节点, 从而避免了键值信息的额外存储.
扇区次数不同. 对含有1 0 0个节点的4阶 B+树进行存储, 采用集中存储的存储方式, 模拟器读写对
比测试结果列于表1.

综上所述, 索引是影响数字数据库查找性能因素之一[1 2] , 较好的索引机制可提高检索数据速度,
并能提高数据空间利用率. 实验结果表明, 本文在 B+树节点存储的情况下访问键值信息, 速度得到
较大提升. 同时, B+树存储的管理需耗费一定资源, 由于节点访问次数不同, 若将常访问的节点放入
节点缓存, 则可减轻系统查询负载, 提高系统性能, 并可通过权值进行调整, 根据权值因子做出动态
调整, 提前命中需要存储在叶子节点的附加信息. 对B+树多任务访问, 避免了读写操作冲突, 设置锁
机制, 避免了节点调整冲突.
转自:
第51卷 第6期 吉 林 大 学 学 报 ( 理 学 版 ) Vo l.5 1 No.6
2 0 1 3年1 1月 J o u r n a lo fJ i l i nUn i v e r s i t y
耿庆田1,2, 狄 婧3, 常 亮1, 赵宏伟1
(1. 吉林大学 计算机科学与技术学院, 长春 1 3 0 0 1 2;
2. 长春师范大学 计算机科学与技术学院, 长春 1 3 0 0 3 2;3. 长春师范大学 网络中心, 长春 1 3 0 0 3 2)
应用于数据索引系统. 在 B+树应用中, 其节点记录了每个子节点附加的数据信息, 并将键值和附加
数据相结合. 一棵节点数量很多的 B+树, 在构建过程中时间和空间开销也较大, 因此, 有必要将
B+树 事先写入磁盘. 不同类型的节点所需空间和实际附加数据大小直接关联, 节点读取效率及其存
储介质读取方式直接关联. 为了有效组织树节点信息单元, 可采用多级位图链表方式进行管理[1 - 3] .
B+树特性:
1) B+树中子树节点和关键字的数量相同;
2) 关键字和叶子节点相对应并且是有序的;
3) 非叶子节点不存储数据;
4) 非叶子节点被当做索引部分, 叶子节点包含子树的关键字;
5) 随机和顺序查找可同时进行[4 - 6] .
1 B+树的存储方式
1.1 系统对 B+树节点的管理
树节点大小可能和存储单元大小吻合, 文件系统的一个逻辑层物理页标准大小是5 1 2字节, 如果节点附加信息存储在其他存储单元, 则节点的物理大小将远小于一个物
理页. B+树节点分为根节点、 内节点和叶子节点3种类型. 这3种节点的物理单元大小可能不同. 作
为 B+树存储, 一个系统需要存储的 B+树数量并不确定. 如果选择对 B+树3种节点类型分开存储,
并对多个 B+树进行统一管理, 则结构清晰且易于维护. 每棵 B+树的分配将由3种不同管理类型负
责分配, 由维护这3类节点的系统统一删除和分配. 这种方式的弊端是对于任意一棵 B+树存储, 都
可能是分散的. 在访问过程中会对分散在不同物理页的节点进行读取和其他操作, 系统I /O 开销负载
较大. 其中节点删除也会导致存储碎片增多.
系统通过构建一种上一层位图管理方法实现文件中节点链表的申请与释放操作. B+树中一些节
点的位图区在系统数据初始化时被记录, 同时构建相应级别的管理模型.
1.2 B+树节点的构成
为提高对 B+树各种操作的效率, 增加磁盘空间利用率, 需要把相同种类的节点存储在连续页面上, 并对 B+树节点种类实行单一管理. 这样可在操作过程中充分利用系统的页
缓存存储临近节点特性, 增加 B+树下其他节点在缓存中命中的可能性, 从而减少了I /O 负载. 由于
B+树中根节点是唯一的, 因此可为 B+树的根节点与内节点、 外节点配备并共用两种不同的存储空
间[7] . 这样既便于管理又节省了宝贵的存储资源. 根节点的地址分配可依据B+树状态操作. 构建B+
树时把根节点分在叶节点地址中, 当树深度大于1时, 则把根节点分在内节点地址中. 为获得树中页
面节点的各种状态, 把节点页面的使用区域分开单独管理, 这样可提供快速系统处理接口. 因此使用
单独分离标志显示该页区域分配情况.
如图1所示, 物理页中存储3个区域: A 表示该物理页内节点区域(B区域)位图; B表示节点存储区域; C表示当前页的下一个关联页链接地址.当有新键值插入时, 先查看该 B+树节点物理页位图起始处, 考虑是否需要构建新节点. 如果需要,则在物理页位图 A 部分查看是否有闲置的空间, 若有则直接插入键值; 若没有, 则把当前节点分成两个叶节点, 把新键值平分到两个叶节点中, 并在两个叶节点的上一层构建新节点. 两个刚生成的叶节点即变为上一层节点的子节点. 本文以物理页为单位存放相异类型的节点, 通过对系统缓存采用优化策略, 把B+树的相关节点存储都尽可能存放在某固定的物理页或某个区域, 这样可使 B+树在存储介质的存放更集中, 同时缩减了I /O 读取次数, 提高了系统效率. 存储系统的物理页都可视为 Ma p位图, 可容纳5 1 2字节的数据, 即可容纳5 1 2个节点[8 - 9] , 并每个 Ma p位图都相关联, 这样使 B+树中节点更易于管理.
2 B+树操作
2.1 元数据的存储
由于 B+树节点众多, 压缩树节点信息量, 因此可扩大一个节点物理存储单元上的分支因子数量, 提高访问效率. 每个节点都存放节点本身的一些位置信息, 这些位置信息内容有存
储地址及数据存放的相关地址, 因此树中的节点由子节点及节点自身的一些相关数据构成, 节点间通
过记录节点存储位置进行关联. 键值信息单元存储了每个键值相关的附加信息, 这些附加信息按特定
格式存储, B+树只需记录附加信息物理位置, 即时读取.
2.2 读取部分访问路径
从叶子节点到根节点只有一条路径[1 0 - 1 1] , 此外, 其他数据与访问没有直接关系. 在需要时读取, 可减轻系统内存和I /O 负载, 提高系统效率. 在树的操作过程中, 根据所访问的
键值寻找根节点到叶子节点通路, 若 B+树分支节点较多, 可对树中所有节点关键字使用二分查找方
法, 即可找到下一级节点, 最终查找到叶子节点. 数据在随意写入读取过程中, 随机对不同元数据的
读写操作可能会产生较多琐碎数据块, 这些数据块分配在不同的存储页面, 当要读取其中某一数据
时, 需要查阅很多存储页面, 既消耗了大量的缓存资源, 也使查找缓存中数据的命中率极大降低, 同
时使I /O 负担过重, 从而使系统的性能下降. 本文把 B+树中节点所包含的数据存放在整个以物理页
面为单位的存储介质上, 同时使用位图模式支配物理页面的使用, 提高系统的读取效率.
2.3 键值对比
B+树中相关节点的键值可由不同方式表示, 可通过排列 H a s h值或字符串值表示. 当键值在存储单元存放时, 要记录链表中相应节点的地址. 当对其他新键值进行各种操作时, 先使用某种
顺序(或路径)查找到链表中节点位置的地址, 通过对地址中节点的内容进行比较, 再确定新键值的地址,
并记录. 因此, 当有新键值需要做插入或删除操作时, 调整其节点的地址即可, 并且这种调整是有序的.
B+树操作的主要步骤如下:
1) 产生 B+树根节点.
当B+树中有新键值插入时, 先通过键值对比, 找到其要插入节点的地址,
然后将该位置的节点分裂成两个节点, 在其上一层生成根节点, 并记录这些节点的地址信息, 相应
B+树 的位图标志信息也需修改.
2) B+树回写信息.
B+树根节点和叶子节点可能在插入或删除等操作中进行了修改, 但其他路
径上相关节点内容没有变化. 因此, 每个节点都有相应的标志位F l u s h. 若F l u s h=1, 则由根节点对该
叶子节点进行信息回写. 因为根节点存放B+树相关节点的信息, 因此需通过递归回写完成索引过程.
要注意在回写根节点前需把 B+树相关节点位置的数据复制到根节点空间.
3) B+树键值插入操作.
当B+树中有新键值插入时, 先遍历整个页面, 找空闲位置, 把新键值放
在空闲位置, 再查找和新键值大小相近的叶子节点, 看是否有空闲位置, 若有位置则直接插入新键值,
若没有空位置, 则该节点自动分裂成两个新节点, 并把新键值插在新节点位置, 且新节点键值的数量
≥1 / 2键值数. 把新节点中键值大的递归向上插在其上一层节点中, 一直插到根节点位置. 如果根节
点没有空位置, 则根节点也分裂成两个节点, 同时在其上层生成新的根节点.
2.4 B+树节点键值删除
如果要删除某一键值 K, 则先要找到键值 K 所在的叶子节点. 算法如下:1) 把找到放置键值 K 叶子节点的索引内容删除. 当前键值后的叶子节点如果为空, 则回收已经
分配的树节点空间; 如果被删除节点键的数量大于或等于 B+树中节点键的最小数量, 则操作结束;
2) 如果被删除叶子节点兄弟节点的键值数小于B+树中节点键最小数量, 则把该节点的键值移到
被删除的叶子节点位置, 合并兄弟节点, 删除父节点位置的键值信息, 其相应的键值也要修改;
3) 若修改后父节点位置的键值和 B+树的条件一致, 删除操作结束; 否则, 一直递归向上到根节
点进行删除操作.
对于以字符串为单位存储键值的情况, 可在存储介质中存储键值内容, 在删除叶子节点而没有影响到内节点的情况下, 作为树的存储, 需为内节点含有相关键值节点做调整, 把键值更换为子树做左节点键值, 更新其与键值的元数据. 图2为对节点删除和调整的过程. 由图 2 可见, 如删除节点 3 5时, 需在查找路径上记录删除键值节点的位置, 最后, 将最左值3 8键值信息写入根节点, 从而避免了键值信息的额外存储.
3 随机存储与位图存储对比
下面对随机存储和位图存储两种存储方式进行对比, 同等规模的存储会使用不同数量扇区, 读取扇区次数不同. 对含有1 0 0个节点的4阶 B+树进行存储, 采用集中存储的存储方式, 模拟器读写对
比测试结果列于表1.
综上所述, 索引是影响数字数据库查找性能因素之一[1 2] , 较好的索引机制可提高检索数据速度,
并能提高数据空间利用率. 实验结果表明, 本文在 B+树节点存储的情况下访问键值信息, 速度得到
较大提升. 同时, B+树存储的管理需耗费一定资源, 由于节点访问次数不同, 若将常访问的节点放入
节点缓存, 则可减轻系统查询负载, 提高系统性能, 并可通过权值进行调整, 根据权值因子做出动态
调整, 提前命中需要存储在叶子节点的附加信息. 对B+树多任务访问, 避免了读写操作冲突, 设置锁
机制, 避免了节点调整冲突.
转自:
第51卷 第6期 吉 林 大 学 学 报 ( 理 学 版 ) Vo l.5 1 No.6
2 0 1 3年1 1月 J o u r n a lo fJ i l i nUn i v e r s i t y
耿庆田1,2, 狄 婧3, 常 亮1, 赵宏伟1
(1. 吉林大学 计算机科学与技术学院, 长春 1 3 0 0 1 2;
2. 长春师范大学 计算机科学与技术学院, 长春 1 3 0 0 3 2;3. 长春师范大学 网络中心, 长春 1 3 0 0 3 2)

相关文章推荐
- 基于B-树和B+树的使用:数据搜索和数据库索引的详细介绍
- 基于B-树和B+树的使用:数据搜索和数据库索引的详细介绍
- 基于B-树和B+树的使用:数据搜索和数据库索引的详细介绍
- 基于Mongodb进行分布式数据存储(转)
- BlogEngine.Net架构与源代码分析系列part3:数据存储——基于Provider模式的实现
- oracle采用分区表+字段索引测试存储大量数据
- 基于Mongodb进行分布式数据存储
- 基于ARM的嵌入式大容量数据存储解决方案
- sql索引影响数据存储位置的示例
- 数据在计算机中存储的物理结构有四种:顺序、链表、散列与索引
- BlogEngine.Net架构与源代码分析系列part3:数据存储——基于Provider模式的实现
- Neo4j推出基于Python的嵌入式图数据存储
- 基于关系数据库系统链式存储的树型结构数据,求某结点下的子树所有结点算法(t-sql语言实现)
- 基于MongoDB进行分布式数据存储的步骤
- 开发基于Safari的wap网站时,本地数据存储(sessionStorage localStorage sqlite)小结
- 基于Mongodb进行分布式数据存储
- SQL优化(索引、存储过程、数据分页的存储过程)
- 基于树型结构数据的关系数据库存储与网页显示的研究 推荐
- 基于闪存存储原理的U盘数据安全测试和U盘数据保护软件
- 基于SST25VF020的数据存储系统设计