1-5.将Hadoop添加到环境变量,初始化HDFS,启动Hadoop,测试hdfs(Hadoop系列day01)
2016-09-21 11:33
316 查看
>>将Hadoop添加到环境变量
1. [root@itcast01 Hadoop]# vim /etc/profile 2. #打开这个文件之后,在文件末尾添加以下代码(上次配置的JDK也在下方写了出来) export JAVA_HOME=/uer/java/jdk1.7.0_60 export HADOOP_HOME=/itcast/hadoop-2.2.0 export PATH =$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin #保存退出 3. #最后刷新一下配置文件 [root@itcast01 Hadoop]# source /etc/profile
>>初始化HDFS(格式化文件系统)
#一个过时的老命令。不过还可以用。 [root@itcast01 Hadoop]#Hadoop namenode -format
现在的方式

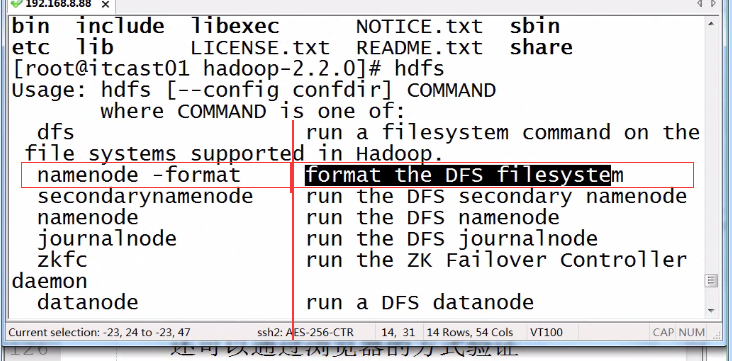
格式化命令– 开始格式化

格式化成功
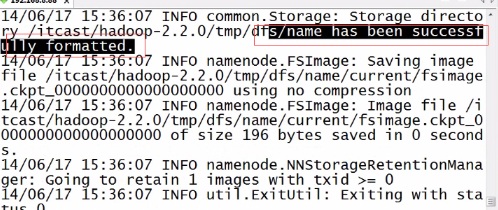
tmp文件夹并不是保存临时文件的,而是Hadoop运行时一个非常重要的文件

>>启动Hadoop
Hadoop两个重要的核心–hdfs和yarn进入sbin目录
启动Hadoop

多次输入密码确认即可
这个方法也过时了,看下图(上面写着正确的方法)
查看是否启动成功
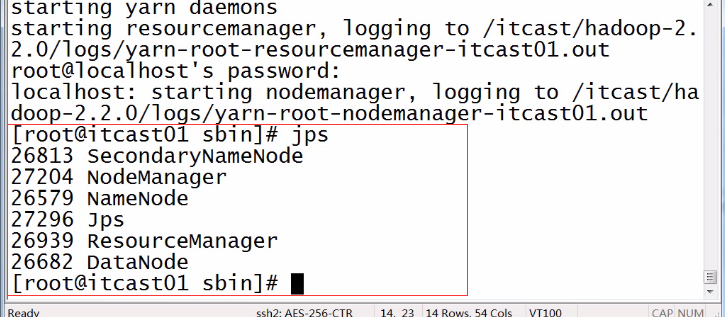
jps命令http://blog.csdn.net/wisgood/article/details/38942449
浏览器访问检查是否成功启动

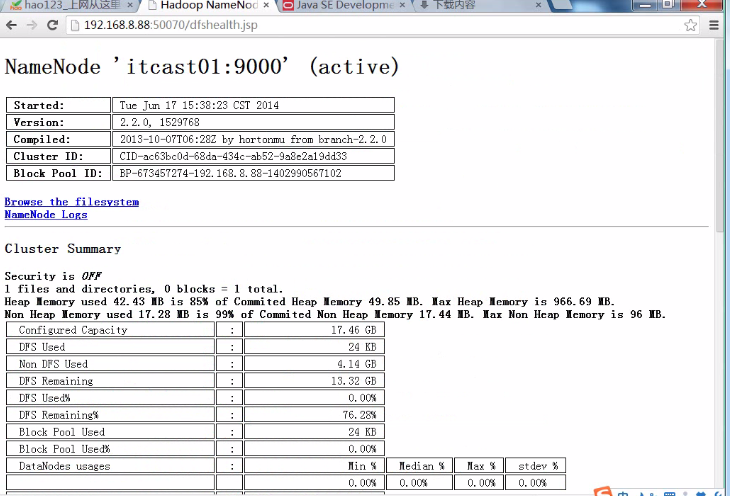
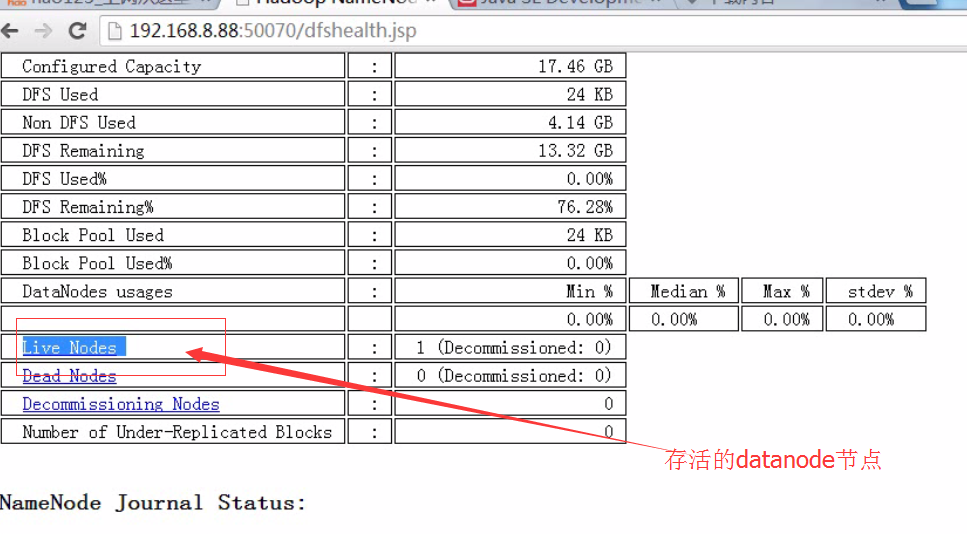
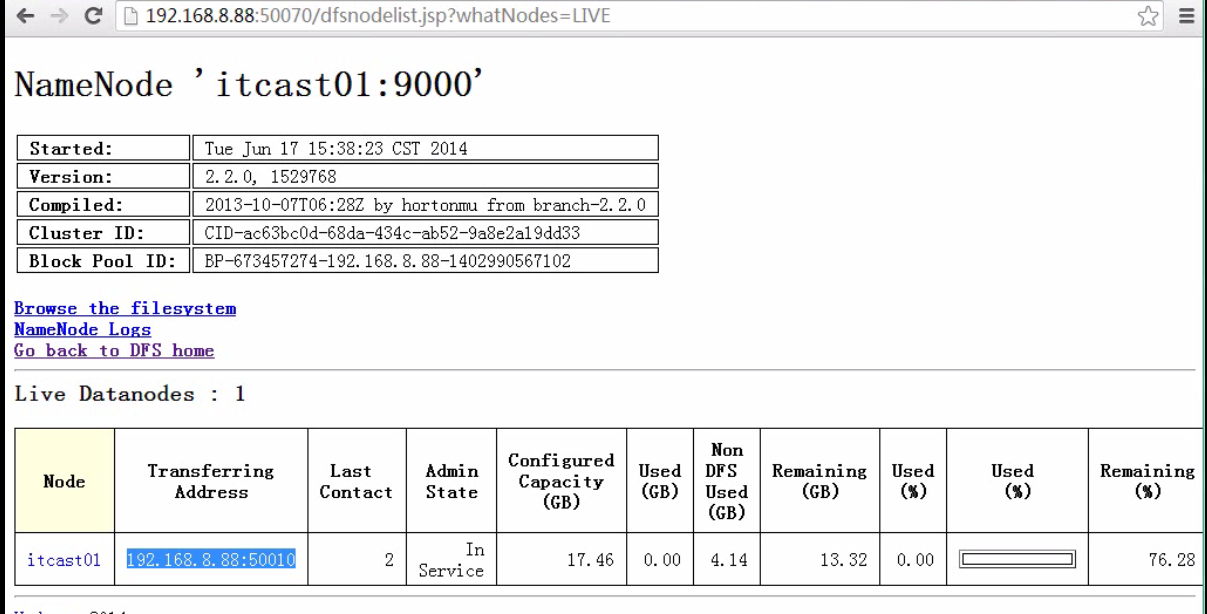

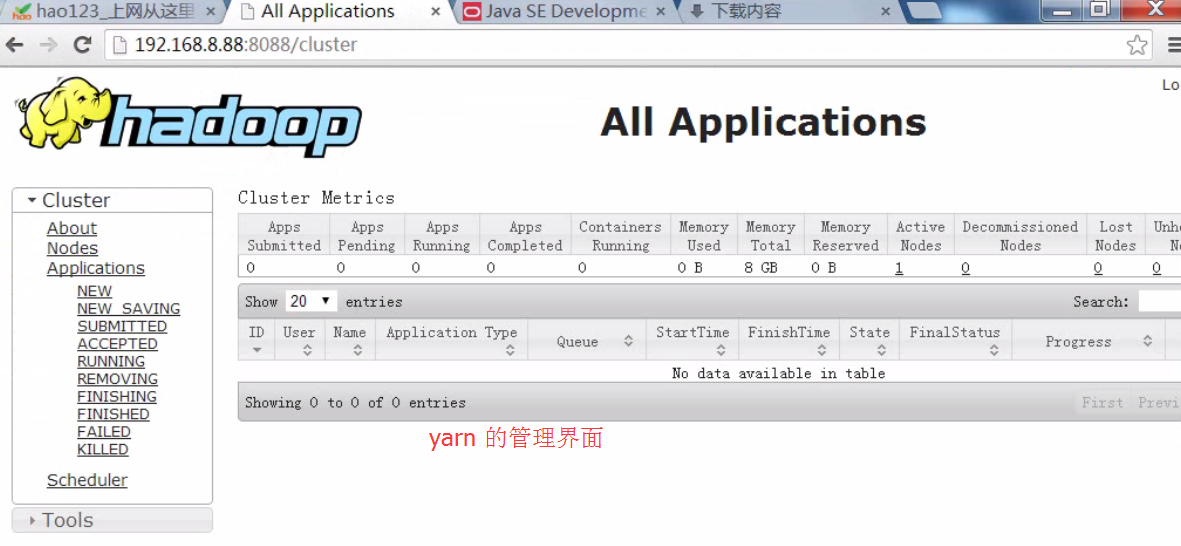
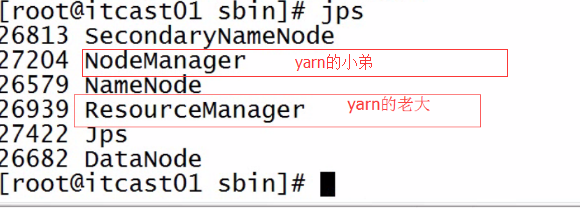
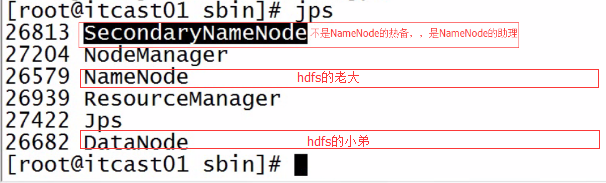
Secondary NameNode:它究竟有什么作用?
http://blog.csdn.net/xh16319/article/details/31375197
>>测试hdfs
>>Linux上传文件到Hadoop

通过浏览器查看一下

>>Hadoop下载文件到Linux
通过浏览器下载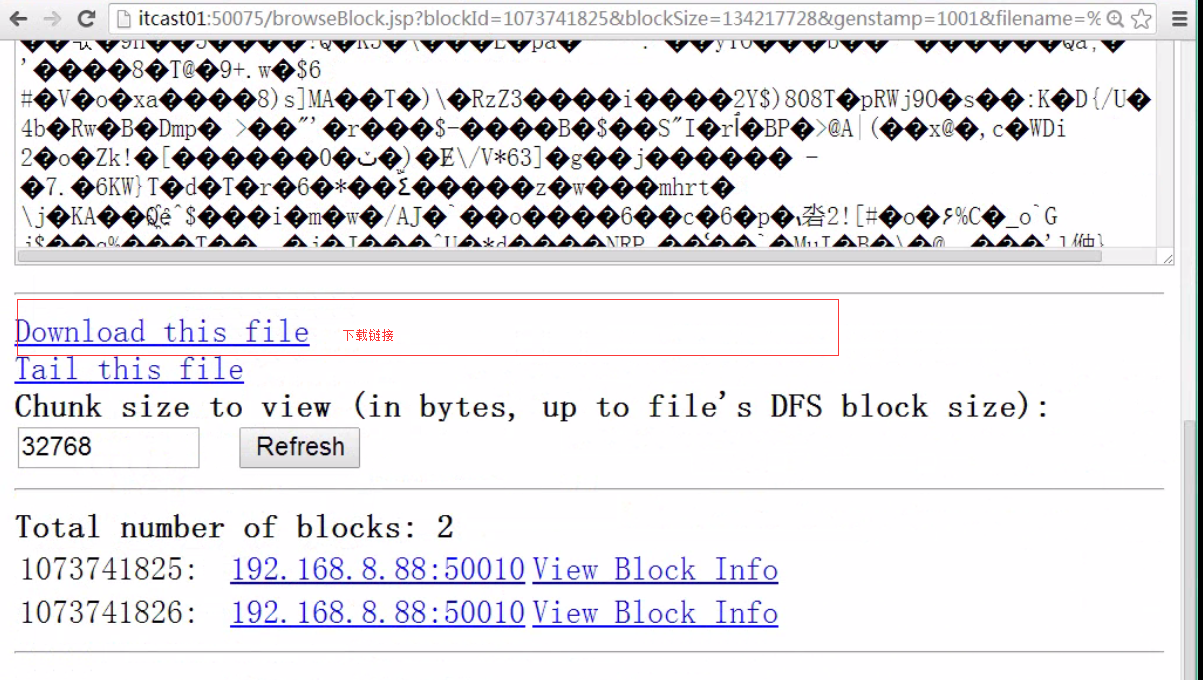
通过命令行下载

测试看能不能解压


相关文章推荐
- Hadoop 学习笔记 (八) hadoop2.2.0 测试环境部署 及两种启动方式
- Hadoop系列二:启动HDFS和YARN过程日志
- 企业级Hadoop 2.x入门系列之八HDFS和YARN的启动方式
- Hadoop之添加环境变量-yellowcong
- Hadoop环境搭建之二配置启动HDFS及本地模式运行MapReduce案例(使用HDFS上数据)
- Linux Shell脚本系列教程(四):使用函数添加环境变量
- Ubuntu16 搭建 Hadoop2.x HDFS 源码测试环境
- centos下添加环境变量和启动apache
- 在VMWare Workstation上使用RedHat Linux安装和配置Hadoop群集环境05_HDFS文件系统和Mapreduce框架的启动和运行
- 在uboot里面添加环境变量使用run来执行并启动时自动执行run
- hadoop 2.x之HDFS HA讲解之八HDFS HA测试启动NameNode遇见错误分析解决
- hadoop 2.x之HDFS HA讲解之九HDFS HA测试启动服务进程、页面监控查看和解决问题
- 一个脚本测试系统环境变量配置文件的启动顺序
- 1-6.测试MR和YARN (Hadoop系列day01)
- hadoop - hadoop2.6 分布式 - 集群环境搭建 - Hadoop 2.6 分布式 配置,初始化,启动过程
- CentOS Linux 环境下 开机自动启动 Hadoop vmware虚拟机测试环境的方案
- FIS--关于下载php后的配置(启动fis的调试服务器(注意添加 --no-rewrite 参数),如果报错 没有php-cgi环境,请 安装 它,并把php-cgi命令加到系统的环境变量)
- Spark源码剖析——SparkContext的初始化(四)_Hadoop相关配置及Executor环境变量
- 【软件测试自动化-QTP系列讲座 33】== 环境变量的动态生成与秘密加载 ==
- hadoop环境变量配置及启动