HashMap的底层工作原理和并发问题
2016-09-19 20:26
633 查看
通过源码分析工作原理
首先来看下HashMap一个典型的构造函数:transient HashMapEntry<K, V>[] table;
public HashMap(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("Capacity: " + capacity);
}
if (capacity == 0) {
@SuppressWarnings("unchecked")
HashMapEntry<K, V>[] tab = (HashMapEntry<K, V>[]) EMPTY_TABLE;
table = tab;
threshold = -1; // Forces first put() to replace EMPTY_TABLE
return;
}
if (capacity < MINIMUM_CAPACITY) {
capacity = MINIMUM_CAPACITY;
} else if (capacity > MAXIMUM_CAPACITY) {
capacity = MAXIMUM_CAPACITY;
} else {
capacity = Collections.roundUpToPowerOfTwo(capacity);
}
makeTable(capacity);
}HashMap里有一个数组table,它存储的元素类型是HashMapEntry,后面会介绍;capacity指的就是这个数组的长度。如果指定数组长度为0,会抛出异常;如果为0,会将table指向EMPTY_TABLE,这个EMPTY_TABLE实际就是长度为2的数组(MINIMUM_CAPACITY 右移1位):
private static final int MINIMUM_CAPACITY = 4; private static final int MAXIMUM_CAPACITY = 1 << 30; private static final Entry[] EMPTY_TABLE = new HashMapEntry[MINIMUM_CAPACITY >>> 1];
从源码可以看出,如果指定的capacity在MINIMUM_CAPACITY和MAXIMUM_CAPACITY之间,那么就会调用Collections.roundUpToPowerOfTwo(capacity); 这个方法的作用是将capacity转化为比它大而且离它最近的2的某个次方数(比如3就会转化成4,9就会转化成16)。由此可见,HashMap中分配的数组大小长度一定是2的次方数。这个HashMapEntry数组里每个存储元素的位置称为bucket,每个bucket只能存放一个Entry元素,系统可根据bucket的索引迅速访问其中存储的元素。
确定数组大小后,就会调用makeTable(capacity);
/**
* The table is rehashed when its size exceeds this threshold.
* The value of this field is generally .75 * capacity, except when
* the capacity is zero, as described in the EMPTY_TABLE declaration
* above.
*/
private transient int threshold;
private HashMapEntry<K, V>[] makeTable(int newCapacity) {
@SuppressWarnings("unchecked") HashMapEntry<K, V>[] newTable
= (HashMapEntry<K, V>[]) new HashMapEntry[newCapacity];
table = newTable;
threshold = (newCapacity >> 1) + (newCapacity >> 2); // 3/4 capacity
return newTable;
}这里有一个成员变量threshold,它是HashMap中table数组是否要扩容的一个衡量指标:如果已存储bucket个数已经达到threshold的值,那么HashMap会重新创建数组并将之前已存储的元素重新计算插入到新数组的bucket中(这个我们在后面分析HashMap的put方法时可以看到)。threshold的值一般会取capacity的3/4。
接下来我们来看下HashMapEntry的结构(省略了里面的get/set方法):
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
HashMapEntry(K key, V value, int hash, HashMapEntry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
@Override public final boolean equals(Object o) {
if (!(o instanceof Entry)) {
return false;
}
Entry<?, ?> e = (Entry<?, ?>) o;
return Objects.equal(e.getKey(), key)
&& Objects.equal(e.getValue(), value);
}
@Override public final int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
}
}可以看出里面除了我们所熟悉的key和value以外,还有int hash和HashMapEntry next两个成员变量。hash是用来验证某个key经过hash算法计算得到的值是否与当前HashMapEntry的hash值相等;next也是HashMapEntry类型,这就类似于链表的结构(HashMapEntry内部还有HashMapEntry),当同一个bucket发生数据碰撞时(两个及以上Entry对应一个bucket),就会用到next,后面我们再做详细介绍。
下面来分析put方法:
@Override
public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);
return null;
}如果key为null,就调用putValueForNullKey方法:
transient HashMapEntry<K, V> entryForNullKey;
private V putValueForNullKey(V value) {
HashMapEntry<K, V> entry = entryForNullKey;
if (entry == null) {
addNewEntryForNullKey(value);
size++;
modCount++;
return null;
} else {
preModify(entry);
V oldValue = entry.value;
entry.value = value;
return oldValue;
}
}这个entryForNullKey指的就是专门存放key为null的数据的HashMapEntry。
如果key不为null,会通过key计算出一个hash值,再利用这个hash值计算出HashMapEntry对应的bucket在数组中的索引:
int index = hash & (tab.length - 1);
这行代码十分巧妙,由于数组大小一定是2的倍数,所以减1后转化成二进制就是首位是0,后面全是1;而hash值可能是个比较大的数,这个一“与”,计算出的index绝对不会出现数组越界的情况。
如果找到bucket的位置(hash值相同),然后就沿着里面存放的HashMapEntry开始进行链表遍历(通过next),直到找到key相同的那个HashMapEntry。图示:
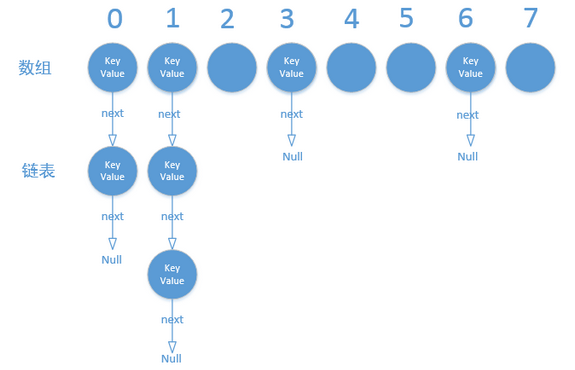
如果没有找到bucket的位置,或者找到了但沿链表遍历没找到key相同的元素,证明现在要put的这个数据的key之前没有出现过,那么就判断添加一个HashMapEntry后大小会不会超过threshold,如果超了就先调用doubleCapacity()进行2倍扩容,最后调用addNewEntry:
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}这里创建了一个新的HashMapEntry,并把之前这里存储的HashMapEntry作为它的next元素。get方法基本同理这里就不在赘述了。
总结
HashMap的数据结构基于数组和链表。用数组存储HashMapEntry元素,当调用put方法去存储数据时,对key调用hashCode()并可能再做进一步加工,得到一个hash值,通过hash值可以找到bucket的位置,如果bucket位置已经有其他元素了(即hash值相同),那么就通过链表结构把hash相同的元素放到链表的下一个节点;当调用get方法去获取数据时,找到bucket以后,会通过key的equals方法在链表中找到目标元素。这里需要注意hashCode()和equals()方法的区别,它们均需保证计算得到的值在插入HashMap后不会发生改变;并需尽可能保证两个不同元素的hashCode方法返回值不同,这样碰撞的几率会小,从而提高HashMap的性能;当HashMap中已经填充了超过3/4的bucket时,会发生rehash,即会创建原来大小两倍的bucket数组,并将原来的元素放入新的bucket数组中。这里的3/4指的是装填因子(load factor),用户可以自行指定,默认是0.75。增大装填因子可以减少 Hash表(Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小装填因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。
多线程并发问题
多线程put时可能导致元素丢失
addNewEntry时,调用table[index] = new HashMapEntry< K, V >(key, value, hash, table[index]);如果两个线程同时取得了旧的table[index],然后赋值给新的table[index]时会有一个成功一个丢失。
Rehash时可能出现环链导致死循环
Rehash时,元素存储位置可能发生更换,代码如下:for (int j = 0; j < oldCapacity; j++) {
/*
* Rehash the bucket using the minimum number of field writes.
* This is the most subtle and delicate code in the class.
*/
HashMapEntry<K, V> e = oldTable[j];
if (e == null) {
continue;
}
int highBit = e.hash & oldCapacity;
HashMapEntry<K, V> broken = null;
newTable[j | highBit] = e;
for (HashMapEntry<K, V> n = e.next; n != null; e = n, n = n.next) {
int nextHighBit = n.hash & oldCapacity;
if (nextHighBit != highBit) {
if (broken == null)
newTable[j | nextHighBit] = n;
else
broken.next = n;
broken = e;
highBit = nextHighBit;
}
}
if (broken != null)
broken.next = null;
}这里面要将oldTable里的元素移动到newTable里,用了链表常用的插入语句,在并发时就可能会出现指针指向混乱的问题从而导致产生环链,遍历时就会出现死循环。详细的死循环产生过程大家可以参考下面的链接,这里就不赘述了。http://www.cnblogs.com/alexlo/p/4955391.html
解决方案
1.Hashtable替换HashMap2.Collections.synchronizedMap将HashMap包装起来
Map m = Collections.synchronizedMap(new HashMap());
synchronized(m) {
......
}3.ConcurrentHashMap替换HashMap

相关文章推荐
- HashMap的底层工作原理和并发问题
- Hashtable,HashMap,ConcurrentHashMap 底层实现原理与线程安全问题
- Hashtable,HashMap,ConcurrentHashMap 底层实现原理与线程安全问题
- Hashtable、HashMap、ConcurrentHashMap底层实现原理与线程安全问题
- Java面试绕不开的问题: Java中HashMap底层实现原理(JDK1.8)源码分析
- HashMap、Hashtable和ConcurrentHashMap底层实现原理和线程安全问题
- Hashtable,HashMap,ConcurrentHashMap 底层实现原理与线程安全问题
- Hashtable、HashMap、ConcurrentHashMap 底层实现原理与线程安全问题
- Hashtable,HashMap,ConcurrentHashMap 底层实现原理与线程安全问题
- hashmap底层实现原理以及常见的面试问题
- HashMap底层详解-003-resize、并发下的安全问题
- HashMap的原理,底层数据结构,rehash的过程,指针碰撞问题
- Hashtable,HashMap,ConcurrentHashMap 底层实现原理与线程安全问题
- Hashtable,HashMap,ConcurrentHashMap 底层实现原理与线程安全问题
- Hashtable,HashMap,ConcurrentHashMap 底层实现原理与线程安全问题
- Hashtable,HashMap,ConcurrentHashMap 底层实现原理与线程安全问题
- 高并发下的HashMap问题
- ASP.NET页面与IIS底层交互和工作原理详解
- 并发场景下HashMap死循环导致CPU100%的问题
- HashMap进行put操作时遇到的并发问题