深入理解计算机系统——第02章——信息的表示和处理
2016-09-18 23:53
821 查看
博客源自:http://blog.csdn.net/xuejianhui/article/details/52579284
我们研究三种最重要的数字表示:
- 无符号(unsigned) :编码基于二进制表示法,表示大于或者等于零的数字。
- 补码(two’s-complement) :编码表示有符号整数。
- 浮点数(floating-point) :编码表示实数的科学记数法的二进制位基数的版本。
计算机的表示法是用有限的数量的位来对一个数字编码,因此,当结果太大以至于不能表示时,某些运算就会
例如:32位系统的int型:200*300*400*500会得出结果 -884,091,888。
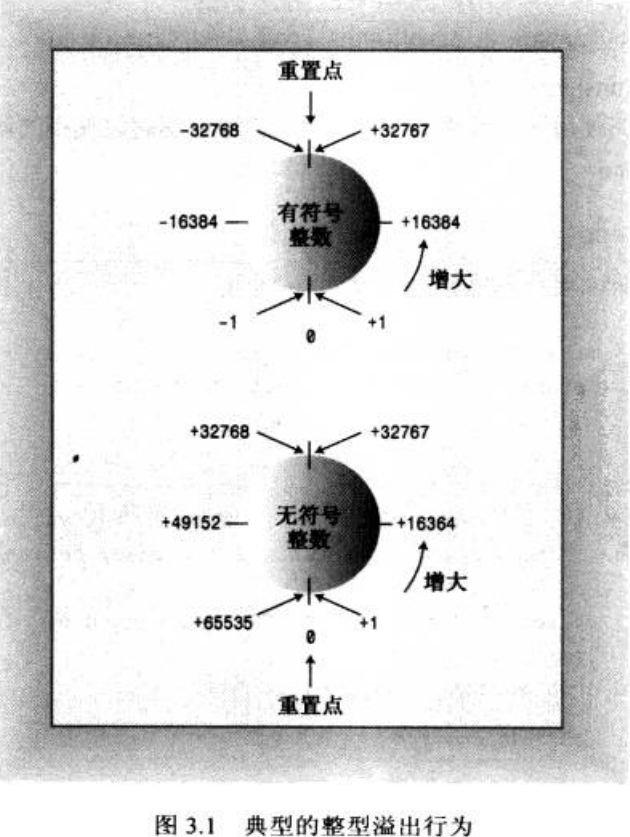
浮点数运算有完全不同的数学属性。虽然溢出会产生特殊的值+∞,但是一组乘积总是正的。
由于表示的精度有限,浮点数运算不是不可结合的。
例如:在大多数机器上,C表达式
整数的表示虽然只能编码一个相对较小的数值范围,但是这种表示是精确的;而浮点数虽然可以编码一个较大的数值范围,但是这种表示却只是近似的。第 03 章将介绍几种不同的二进制表示形式来编码数值。
C 语言的演变:
最初,
1999年国际标准化组织发布了“ISO C99”,后续很多编译器就实现了这个标准。比如GNU编译器套件(GUN Compiler Collection,GCC)可基于不同命令行选项,依照多个不同版本的C语言规则来编译程序。
向GCC指定不同的 C 语言版本:
题外补充内容:
《C++ Primer Plus》中关于int、short、long等字段的介绍:
short至少16位。
int至少与short一样长。
long至少32位,且至少与int一样长。
8位最大为 :2*2*2*2*2*2*2*2=256,可表示0~255或者-128~127。
16位最大为:256*256=65535。
32位最大为:65535*65535=4,294,672,296(约为43亿bit,4G)。
64位最大为:43亿*43亿=18,446,744,073,709,551,616(约为1,849亿bit,16EB)。
字节单位:
1KB (Kilobyte 千字节)=1024B,
1MB (Megabyte 兆字节 简称“兆”)=1024KB,
1GB (Gigabyte 吉字节 又称“千兆”)=1024MB,
1TB (Trillionbyte 万亿字节 太字节)=1024GB,其中1024=2^10 ( 2 的10次方),
1PB(Petabyte 千万亿字节 拍字节)=1024TB,
1EB(Exabyte 百亿亿字节 艾字节)=1024PB,
1ZB (Zettabyte 十万亿亿字节 泽字节)= 1024 EB,
1YB (Jottabyte 一亿亿亿字节 尧字节)= 1024 ZB,
1BB (Brontobyte 一千亿亿亿字节)= 1024 YB.
注:“兆”为百万级数量单位。
附:进制单位全称及译音
yotta, [尧]它 Y. 10^21,
zetta, [泽]它 Z. 10^18,
exa, [艾]可萨 E. 10^15,
peta, [拍]它 P. 10^12,
tera, [太]拉 T. 10^9,
giga, [吉]咖 G. 10^6,
mega, [兆] M. 10^3
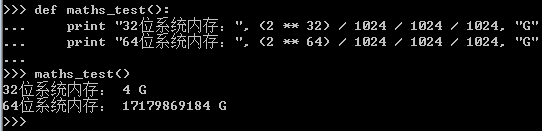
用以下python脚本测试结果如下:
下面是各整数类型分别在32位机器和64位机器的字长情况:
对于有跨平台编程的同学,既然Win64与Linux64有区别,那怎么写出兼容性更好的代码呢,毕竟,很多安全漏洞都是由于计算机算术运算的微妙细节引发的。
在《C++ Primer Plus》中,提到可用
注意:unsigned 本身就是unsigned int的缩写。
C 语言标准对不同数据类型的数字范围设置了下界,但是却没有上界。
比如:在32位机器上,可用一个int类型对象存储一个指针的值,因为它们都是4字节。但64位机器上会出问题,因指针是8字节。
在 C 语言中,以0x或0X开头的数字常量被认为是十六进制的值。字符’A’~’F’即可是大写,也可以是小写,甚至是大小写混合。
十进制to十六机制:
十六机制to十进制:
题外话
第 02 章:信息的表示和处理
第 03 章:程序的机器级表示
第 04 章:处理器体系结构
第 05 章:优化程序性能
第 06 章:存储器层次结构
第 07 章:链接
第 08 章:异常控制流
第 09 章:虚拟存储器
第 10 章:系统级I/O
第 11 章:网络编程
第 12 章:并发编程
我们研究三种最重要的数字表示:
- 无符号(unsigned) :编码基于二进制表示法,表示大于或者等于零的数字。
- 补码(two’s-complement) :编码表示有符号整数。
- 浮点数(floating-point) :编码表示实数的科学记数法的二进制位基数的版本。
计算机的表示法是用有限的数量的位来对一个数字编码,因此,当结果太大以至于不能表示时,某些运算就会
溢出(overflow)。
例如:32位系统的int型:200*300*400*500会得出结果 -884,091,888。
浮点数运算有完全不同的数学属性。虽然溢出会产生特殊的值+∞,但是一组乘积总是正的。
由于表示的精度有限,浮点数运算不是不可结合的。
例如:在大多数机器上,C表达式
(3.14+1e20)-1e20的结果是0.0,而
3.14+(1e20-1e20)结果会是3.14。
整数的表示虽然只能编码一个相对较小的数值范围,但是这种表示是精确的;而浮点数虽然可以编码一个较大的数值范围,但是这种表示却只是近似的。第 03 章将介绍几种不同的二进制表示形式来编码数值。
C 语言的演变:
最初,
Dennis Ritchie创造 C 语言目的是和Unix系统一起使用。那时大多数操作系统,为了访问不同数据类型的低级表示,都必须用大量的汇编语言代码编写。比如说,向malloc库函数提供的内容分配那样的功能,用当时的其他高级语言是无法编写的。
Brian Kernighan和
Dennis Ritchie在著作的第 1 版贝尔实验室的C语言版本。之后美国标准学会发布的ANSI C与贝尔实验室版本有很大不同,尤其是函数的生命方式。
Brian Kernighan和
Dennis Ritchie在著作的第 2 版中描述了ANSI C,这本书至今仍被公认为关于 C 语言最好的参考手册之一。
1999年国际标准化组织发布了“ISO C99”,后续很多编译器就实现了这个标准。比如GNU编译器套件(GUN Compiler Collection,GCC)可基于不同命令行选项,依照多个不同版本的C语言规则来编译程序。
unix>gcc -std=c99 hello.c
向GCC指定不同的 C 语言版本:
| C版本 | GCC命令 |
|---|---|
| GNU 89 | 无,-std==gnu89 |
| ANSI,ISO C90 | -ansi,std=c89 |
| ISO C99 | -std=c99 |
| GNU 99 | -std=gnu99 |
《C++ Primer Plus》中关于int、short、long等字段的介绍:
short至少16位。
int至少与short一样长。
long至少32位,且至少与int一样长。
8位最大为 :2*2*2*2*2*2*2*2=256,可表示0~255或者-128~127。
16位最大为:256*256=65535。
32位最大为:65535*65535=4,294,672,296(约为43亿bit,4G)。
64位最大为:43亿*43亿=18,446,744,073,709,551,616(约为1,849亿bit,16EB)。
字节单位:
1KB (Kilobyte 千字节)=1024B,
1MB (Megabyte 兆字节 简称“兆”)=1024KB,
1GB (Gigabyte 吉字节 又称“千兆”)=1024MB,
1TB (Trillionbyte 万亿字节 太字节)=1024GB,其中1024=2^10 ( 2 的10次方),
1PB(Petabyte 千万亿字节 拍字节)=1024TB,
1EB(Exabyte 百亿亿字节 艾字节)=1024PB,
1ZB (Zettabyte 十万亿亿字节 泽字节)= 1024 EB,
1YB (Jottabyte 一亿亿亿字节 尧字节)= 1024 ZB,
1BB (Brontobyte 一千亿亿亿字节)= 1024 YB.
注:“兆”为百万级数量单位。
附:进制单位全称及译音
yotta, [尧]它 Y. 10^21,
zetta, [泽]它 Z. 10^18,
exa, [艾]可萨 E. 10^15,
peta, [拍]它 P. 10^12,
tera, [太]拉 T. 10^9,
giga, [吉]咖 G. 10^6,
mega, [兆] M. 10^3
用以下python脚本测试结果如下:
# 测试2的64次方和32次方的大小 def maths_test(): print "32位系统内存:",(2 ** 32) / 1024 / 1024 / 1024, "GB" print "64位系统内存:",(2 ** 64) / 1024 / 1024 / 1024, "GB"
下面是各整数类型分别在32位机器和64位机器的字长情况:
| C声明 | 32位机器 | 64位机器 | 备注 |
|---|---|---|---|
| char | 1 | 1 | |
| short | 2 | 2 | |
| int | 4 | 4 | int不定长,最大是32位。 |
| long | 4 | 8 | Linux64位系统下,是8字节;Windows64系统下,为兼容32位程序,还是4字节。 |
| long long | 8 | 8 | 64位系统下,是全字长;32位系统下,编译器会将其编译成执行一系列32位操作的代码。 |
| float | 4 | 4 | |
| double | 8 | 8 | |
| char* | 4 | 8 | 指针的值是虚拟地址,因此是全字长。 |
在《C++ Primer Plus》中,提到可用
climits.h(ANSI C头文件
limits.h的C++版)来获取整形的限制。
| 符号常量 | climits的符号表示 |
|---|---|
| CHAR_BIT | char 的位数 |
| CHAR_MAX | char 的最大值 |
| CHAR_MIN | char 的最小值 |
| SCHAR_MAX | signed char 的最大值 |
| SCHAR_MIN | signed char 的最小值 |
| UCHAR_MAX | unsigned char 的最大值 |
| SHRT_MAX | short 的最大值 |
| SHRT_MIN | short 的最小值 |
| USHRT_MAX | unsigned short 的最大值 |
| INT_MAX | int 的最大值 |
| INT_MIN | int 的最小值 |
| UINT_MAX | unsigned int 的最大值 |
| LONG_MAX | long 的最大值 |
| LONG_MIN | long 的最小值 |
| ULONG_MAX | unsigned long 的最大值 |
C 语言标准对不同数据类型的数字范围设置了下界,但是却没有上界。
比如:在32位机器上,可用一个int类型对象存储一个指针的值,因为它们都是4字节。但64位机器上会出问题,因指针是8字节。
2.1 信息存储
在实际使用中,二进制过长,十进制与位模式互相转换有很麻烦。因此引入十六进制(hexadecimal,简称hex)来表示位模式。
在 C 语言中,以0x或0X开头的数字常量被认为是十六进制的值。字符’A’~’F’即可是大写,也可以是小写,甚至是大小写混合。
十进制to十六机制:
#!/usr/local/bin/perl
#Convert list of decimal numbers into hex
for ($i = 0; $i < @ARGV; $i++){
printf("%d\t= 0x%x\n", $ARGV[$i], $ARGV[$i]);
}十六机制to十进制:
#!/usr/local/bin/perl
#Convert list of decimal numbers into hex
for ($i = 0; $i < @ARGV; $i++){
$var = hex($ARGV[$i]);
printf("0x%x = %d\n", $var, $var);
}题外话
所有章节内容:
第 01 章:计算机系统漫游第 02 章:信息的表示和处理
第 03 章:程序的机器级表示
第 04 章:处理器体系结构
第 05 章:优化程序性能
第 06 章:存储器层次结构
第 07 章:链接
第 08 章:异常控制流
第 09 章:虚拟存储器
第 10 章:系统级I/O
第 11 章:网络编程
第 12 章:并发编程
参考资料:
C++那些细节–32位64位数据类型的区别
相关文章推荐
- 深入理解计算机系统--第二章(信息的表示和处理)
- 深入理解计算机系统 第2章 信息的表示和处理
- 深入理解计算机系统--信息表示和处理
- 深入理解计算机系统之旅(二)信息在计算机中的表示和处理
- 深入理解计算机系统----->信息的表示和处理笔记
- 深入理解计算机系统--信息的表示和处理
- 深入理解计算机系统(第二版)----之二:(一:程序的结构和执行)信息的表示和处理
- 深入理解计算机系统学习之信息的表示和处理
- 深入理解计算机系统读书笔记之第二章信息的表示和处理
- 深入理解计算机系统:信息的处理与表示(一)基础
- 深入理解计算机系统--信息的表示和处理
- 深入理解计算机系统:信息的处理和表示(二)整数四则运算
- [深入理解计算机系统]第二章-信息的表示与处理
- Learning by doing 二 深入理解计算机系统(CS:APP)一信息表示
- 深入理解计算机系统 第二章 表示和操作信息
- 深入理解计算机系统(2.1)------信息的存储和表示
- 【深入理解计算机系统】_2_计算机系统中的信息表示
- 深入理解计算机系统(2.1)------信息的存储和表示
- 2、深入理解计算机系统笔记:信息表示
- 【深入理解计算机系统】_2_计算机系统中的信息表示