Performance of Using Keys in SELECT with FOR ALL ENTRIES
2016-09-08 13:34
579 查看
You would get insight from Performance perspective when not using the Keys in SELECT with FOR ALL ENTRIES. System would spend definitely more time when there mixture of Entries in the ITAB.
Page Contents [hide]
1 Problem
2 Solution
3 Code
Lines
3.1 Report
Z_PERF_FOR_ALL_ENTRIES
4 Statistics
5 More
Performance Tuning tips in ABAP
Once you have selected records from one table and need to get the relevant records from the dependent table, you generally use FOR ALL ENTRIES IN ITAB addition of the SELECT query. This would return you the entries which matched
keys from your ITAB specified after FOR ALL ENTRIES.
Most of the time, people select the data in ITAB and use that ITAB to get the data from another table. Like, you select the Materials from Sales Order items VBAP and use FOR ALL ENTRIES to select description from MAKT for the selected
Materials. At this point, many people just pass all the selected entries from VBAP as FOR ALL ENTRIES FROM LT_SO_ITEMS. This is usually a performance drainage.
While using the FOR ALL ENTRIES, system selects all the records which meets the where condition. Once the data is selected, it removes the duplicate entries. E.g. if you have 1000 entries in your LT_SO_ITEMS and you use it in FOR
ALL ENTRIES, it would select the records from MAKT for all 1000 entries even though there are only few say 50 unique materials. After the data selection, DB removes the duplicate records and present you the description for 50 materials.
Whenever you need to use the FOR ALL ENTRIES, you must always consider getting unique keys first before doing the SELECT. It may appear unnecessary work, but believe me, it would save you lot of time. Refer to the statistics at end
of this post to figure out the performance improvement.
To get the unique keys:
Declare a key table type
Declare a ITAB_KEYS with this type
LOOP AT main ITAB and append entries in the ITAB_KEYS
SORT and DELETE adjacent duplicates
There would be other ways to achieve the Keys – Collect the table, READ the table entries before appending in it.
Check out the code lines and the numbers to see the performance improvement achieved when you use Unique Keys. In the code lines, there are 3 different approach to select the data.
Using the Mix keys. You selected the records, you used it directly in FOR ALL ENTRIES
Getting the Unique keys by doing the DELETE adjacent duplicates and then use in FOR ALL ENTRIES
Getting the Unique keys by READ and then use in FOR ALL ENTRIES
I ran the report for different number of records. The numbers are like this:
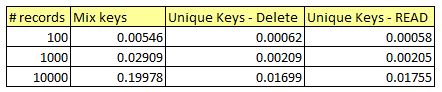
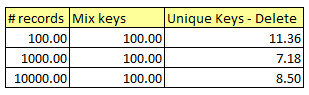
If we make time takes by mix keys as 100%, the time taken by unique keys would look like this:
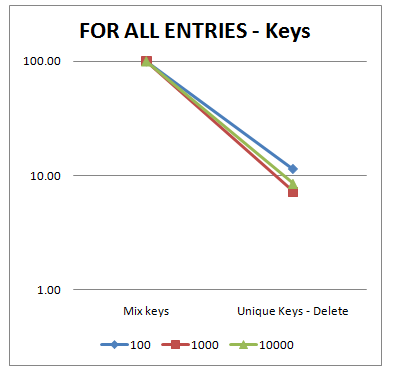
And on graph ..
Check out the other threads to learn more Performance Tuning in ABAP:
Parallel
Cursor – To speed up performance of Nested LOOP
Parallel
Cursor – 2: without using READ
Use
of Field-symbols vs Work area
Measure
the Performance between Break-Points using SE30
READ-ONLY
attribute vs GETTER methods
Performance
of ITAB Copy
Performance
of Using Keys in SELECT with FOR ALL ENTRIES
ABAP
Internal Table Performance for STANDARD, SORTED and HASHED Table
ABAP
Internal Table Secondary Key Performance comparison
ABAP
build a table with Unique Keys – Performance Comparison
ABAP
Parallel Cursor – Things to Remember
Use
of REFERENCE variable vs Workarea vs Field-Symbols
FOR
ALL ENTRIES – Why you need to include KEY fields
ABAP
Performance for DELETE on ITAB
quote: http://zevolving.com/2012/05/performance-of-using-keys-in-select-with-for-all-entries/
Page Contents [hide]
1 Problem
2 Solution
3 Code
Lines
3.1 Report
Z_PERF_FOR_ALL_ENTRIES
4 Statistics
5 More
Performance Tuning tips in ABAP
Problem
Once you have selected records from one table and need to get the relevant records from the dependent table, you generally use FOR ALL ENTRIES IN ITAB addition of the SELECT query. This would return you the entries which matchedkeys from your ITAB specified after FOR ALL ENTRIES.
Most of the time, people select the data in ITAB and use that ITAB to get the data from another table. Like, you select the Materials from Sales Order items VBAP and use FOR ALL ENTRIES to select description from MAKT for the selected
Materials. At this point, many people just pass all the selected entries from VBAP as FOR ALL ENTRIES FROM LT_SO_ITEMS. This is usually a performance drainage.
While using the FOR ALL ENTRIES, system selects all the records which meets the where condition. Once the data is selected, it removes the duplicate entries. E.g. if you have 1000 entries in your LT_SO_ITEMS and you use it in FOR
ALL ENTRIES, it would select the records from MAKT for all 1000 entries even though there are only few say 50 unique materials. After the data selection, DB removes the duplicate records and present you the description for 50 materials.
Solution
Whenever you need to use the FOR ALL ENTRIES, you must always consider getting unique keys first before doing the SELECT. It may appear unnecessary work, but believe me, it would save you lot of time. Refer to the statistics at endof this post to figure out the performance improvement.
To get the unique keys:
Declare a key table type
Declare a ITAB_KEYS with this type
LOOP AT main ITAB and append entries in the ITAB_KEYS
SORT and DELETE adjacent duplicates
There would be other ways to achieve the Keys – Collect the table, READ the table entries before appending in it.
Code Lines
Check out the code lines and the numbers to see the performance improvement achieved when you use Unique Keys. In the code lines, there are 3 different approach to select the data.Using the Mix keys. You selected the records, you used it directly in FOR ALL ENTRIES
Getting the Unique keys by doing the DELETE adjacent duplicates and then use in FOR ALL ENTRIES
Getting the Unique keys by READ and then use in FOR ALL ENTRIES
Report Z_PERF_FOR_ALL_ENTRIES
REPORT Z_PERF_FOR_ALL_ENTRIES. TYPES: BEGIN OF lty_matnr, matnr TYPE mara-matnr, END OF lty_matnr. DATA: lt_matnr TYPE STANDARD TABLE OF lty_matnr. DATA: lt_makt TYPE STANDARD TABLE OF makt. DATA: lv_sta_time TYPE timestampl, lv_end_time TYPE timestampl, lv_diff_w TYPE p DECIMALS 5, lv_diff_f LIKE lv_diff_w, lv_save LIKE lv_diff_w. DATA: lt_mix_matnrs TYPE STANDARD TABLE OF lty_matnr. DATA: lwa_mix_matnrs LIKE LINE OF lt_mix_matnrs. DATA: lt_unique_matnrs TYPE STANDARD TABLE OF lty_matnr. DATA: lwa_unique_matnrs LIKE LINE OF lt_unique_matnrs. * Prepare data SELECT matnr INTO TABLE lt_matnr FROM mara UP TO 10 ROWS. " Change the number to get different numbers DO 1000 TIMES. APPEND LINES OF lt_matnr TO lt_mix_matnrs. ENDDO. *------- * 1. Mix keys *------- GET TIME STAMP FIELD lv_sta_time. SELECT * FROM makt INTO TABLE lt_makt FOR ALL ENTRIES IN lt_mix_matnrs WHERE matnr = lt_mix_matnrs-matnr. GET TIME STAMP FIELD lv_end_time. lv_diff_w = lv_end_time - lv_sta_time. WRITE: /(30) 'Mix Keys', lv_diff_w. *------- * 2. Unique Keys - DELETE *------- GET TIME STAMP FIELD lv_sta_time. LOOP AT lt_mix_matnrs INTO lwa_mix_matnrs. lwa_unique_matnrs-matnr = lwa_mix_matnrs-matnr. APPEND lwa_mix_matnrs TO lt_unique_matnrs. ENDLOOP. SORT lt_unique_matnrs BY matnr. DELETE ADJACENT DUPLICATES FROM lt_unique_matnrs COMPARING matnr. SELECT * FROM makt INTO TABLE lt_makt FOR ALL ENTRIES IN lt_unique_matnrs WHERE matnr = lt_unique_matnrs-matnr. GET TIME STAMP FIELD lv_end_time. lv_diff_f = lv_end_time - lv_sta_time. WRITE: /(30) 'Uniqe Keys - delete', lv_diff_f. *------- * 3. Unique Keys - READ *------- CLEAR: lt_unique_matnrs. GET TIME STAMP FIELD lv_sta_time. SORT lt_mix_matnrs BY matnr. LOOP AT lt_mix_matnrs INTO lwa_mix_matnrs. READ TABLE lt_unique_matnrs TRANSPORTING NO FIELDS WITH KEY matnr = lwa_mix_matnrs-matnr BINARY SEARCH. IF sy-subrc NE 0. lwa_unique_matnrs-matnr = lwa_mix_matnrs-matnr. APPEND lwa_unique_matnrs TO lt_unique_matnrs. ENDIF. ENDLOOP. SELECT * FROM makt INTO TABLE lt_makt FOR ALL ENTRIES IN lt_unique_matnrs WHERE matnr = lt_unique_matnrs-matnr. GET TIME STAMP FIELD lv_end_time. lv_diff_f = lv_end_time - lv_sta_time. WRITE: /(30) 'Uniqe Keys - Read', lv_diff_f.
Statistics
I ran the report for different number of records. The numbers are like this:If we make time takes by mix keys as 100%, the time taken by unique keys would look like this:
And on graph ..
More Performance Tuning tips in ABAP
Check out the other threads to learn more Performance Tuning in ABAP:Parallel
Cursor – To speed up performance of Nested LOOP
Parallel
Cursor – 2: without using READ
Use
of Field-symbols vs Work area
Measure
the Performance between Break-Points using SE30
READ-ONLY
attribute vs GETTER methods
Performance
of ITAB Copy
Performance
of Using Keys in SELECT with FOR ALL ENTRIES
ABAP
Internal Table Performance for STANDARD, SORTED and HASHED Table
ABAP
Internal Table Secondary Key Performance comparison
ABAP
build a table with Unique Keys – Performance Comparison
ABAP
Parallel Cursor – Things to Remember
Use
of REFERENCE variable vs Workarea vs Field-Symbols
FOR
ALL ENTRIES – Why you need to include KEY fields
ABAP
Performance for DELETE on ITAB
quote: http://zevolving.com/2012/05/performance-of-using-keys-in-select-with-for-all-entries/

相关文章推荐
- Along with all the above benefits, you cannot overlook the space efficiency and performance gains in using DataFrames and Dataset APIs for two reasons.
- Improving Performance of FOR ALL ENTRIES QUERY
- Improving Performance of FOR ALL ENTRIES QUERY
- Improving Performance of FOR ALL ENTRIES QUERY
- Improving Performance of FOR ALL ENTRIES QUERY
- Improving Performance of FOR ALL ENTRIES QUERY
- 转【FOR ALL ENTRIES IN】 总结
- Use For all entries in abap sql need attention...
- abap 中 for all entries in 中的 distinct 功能
- ABAP FOR ALL ENTRIES IN 使用指南
- Select n numbers from 1 to m with all of array 'all' and none of array 'none'
- The name or security ID (SID) of the domain specified is inconsistent with the trust information for that domain.
- The name or security ID (SID) of the domain specified is inconsistent with the trust information for that domain(转)
- ABAP "FOR ALL ENTRIES IN" 使用指南
- Problems with System.OutOfMemoryException At System.String.GetStringForStringBuilder in 32-Bit Managed Solutions
- ABAP中FOR ALL ENTRIES IN 运用
- FOR ALL ENTRIES IN itab WHERE cond使用注意事项:
- The name or security ID (SID) of the domain specified is inconsistent with the trust information for that domain
- ABAP "FOR ALL ENTRIES IN" 使用指南
- ABAP "FOR ALL ENTRIES IN"