CUDA学习--CUDA流
2016-09-06 20:59
501 查看
1. CUDA流介绍
CUDA流在加速应用程序方面起着重要的作用。CUDA流表示一个GPU操作队列,并且该队列中的操作将以指定的顺序执行。我们可以在流中添加一些操作,如核函数启动,内存复制等。将这些操作添加到流的顺序也就是他们的执行顺序。你可以将每个流视为GPU上的一个任务,并且这些任务可以并行执行。2. CUDA流的使用
我们先通过在应用程序中使用单个流来说明流的用法。1) 首先,选择一个支持设备重叠功能的设备。支持设备重叠功能的GPU能够在执行一个CUDA C核函数的同时,还能在设备与主机之间执行复制操作。
cudaDeviceProp prop;
int whichDevice;
cudaGetDevice(&whichDevice);
cudaGetDeviceProperties(&prop, whichDevice);
if (!prop.deviceOverlap)
{
printf("Device will not handle overlaps, so no speed up from streams.\n");
return 0;
}2) 接下来,创建在应用程序中使用的流:
<span style="white-space:pre"> </span>cudaStream_t stream; <span style="white-space:pre"> </span>cudaStreamCreate(&stream);3) 然后是数据分配操作。注意,程序将使用主机上的固定内存,即调用cudaHostAlloc()来执行内存分配:
int *host_a, *host_b, *host_c;
int *dev_a, *dev_b, *dev_c;
cudaError_t cudaStatus;
cudaStatus = cudaMalloc((void **)&dev_a, N * sizeof(int));
if (cudaStatus != cudaSuccess)
{
printf("cudaMalloc dev_a failed!\n");
}
cudaStatus = cudaHostAlloc((void **)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault);
if (cudaStatus != cudaSuccess)
{
printf("cudaHostAlloc host_a failed!\n");
}4) 在执行核函数时,首先我们不会将输入缓冲区整体都复制到GPU,而是将输入缓冲区划分为更小的块,并在每个块上执行一个包含三个步骤(复制到GPU--运行核函数--复制回主机)的过程。需要这种方法的一种情形是:GPU的内存远小于主机内存,由于整个缓冲区无法一次性填充到GPU,因此需要分块进行计算:for (int i = 0; i < FULL_DATA_SIZE; i += N)
{
cudaStatus = cudaMemcpyAsync(dev_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);
if (cudaStatus != cudaSuccess)
{
printf("cudaMemcpyAsync a failed!\n");
}
cudaStatus = cudaMemcpyAsync(dev_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);
if (cudaStatus != cudaSuccess)
{
printf("cudaMemcpyAsync b failed!\n");
}
kernel << <N / GPUBLOCKNUM, GPUTHREADNUM, 0, stream >> >(dev_a, dev_b, dev_c);
cudaStatus = cudaMemcpyAsync(dev_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);
if (cudaStatus != cudaSuccess)
{
printf("cudaMemcpyAsync c failed!\n");
}
}注意,这段代码中并没有使用cudaMemcpy(),而是通过cudaMemcpyAsync()在GPU与主机之间复制数据。函数差异虽小,但却很重要。cudaMemcpy()的行为类似于C库函数memcpy()。尤其是,这个函数将以同步方式执行,也就是说,当函数返回时,复制操作已经完成。异步函数的行为与同步函数相反,在调用cudaMemcpyAsync()时,只是放置一个请求,表示在流中执行一次内存复制操作,这个流是通过参数stream来指定的。当函数返回时,我们无法确保复制操作是否已经启动或完成。我们能够保证的是复制操作肯定会在下一个被放入流中的操作启动之前执行。任何传递给cudaMemcpyAsync()的主机内存指针都必须已经通过cudaHostAlloc()分配好内存,也就是,只能以异步方式对页锁定内存进行复制操作。
注意,在核函数调用的尖括号中有一个流参数stream,此时核函数调用将是异步的。从技术上来说,当循环迭代完一次时,有可能不会启动任何内存复制或核函数执行。但能够确保的是,第一次放入流中的复制操作将在第二次复制操作之前执行,第二个复制操作将在核函数启动之前执行完成。这意味着,代码中for循环的完成不保证流的完成,每个流中的任务都可能处于等待状态。
5) 当for循环结束时,队列中应该包含了许多等待GPU执行的工作。如果想要确保GPU执行完了计算与内存复制等操作,那么就需要将GPU与主机同步。也就是说,主机在继续执行之前,要首先等待GPU执行完成。可以调用cudaStreamSynchronize()并指定想要等待的流:
cudaStatus = cudaStreamSynchronize(stream);6) 当程序执行到stream与主机同步之后的代码时,所用计算与复制操作都已完成。此时需要释放缓冲区,并销毁对GPU操作进行排队的流:
cudaFreeHost(host_a); cudaFreeHost(host_b); cudaFreeHost(host_c); cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c); cudaStreamDestroy(stream);至此,单个流的使用已经讲完。
3. 多个流的使用
1) GPU的工作调度机制程序员可以将流视为有序的操作序列,其中即包含内存复制操作,又包含核函数调用。然而,在硬件中没有流的概念,而是包含一个或多个引擎来执行内存复制操作,以及一个引擎来执行核函数。这些引擎彼此独立地对操作进行排队,因此将导致如下图所示的任务调度情形。
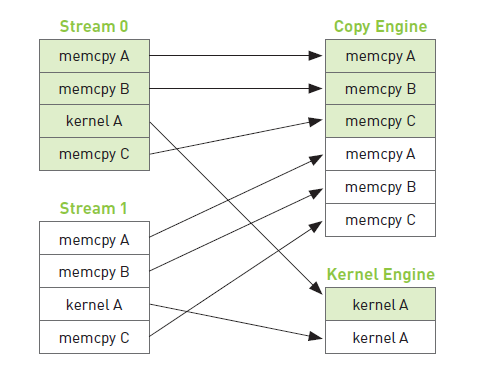
因此,在某种程度上,用户与硬件关于GPU工作的排队方式有着完全不同的理解,而CUDA驱动程序则负责对用户和硬件进行协调。首先,在操作被添加到流的顺序中包含了重要的依赖性。例如上图,第0个流对A的内存复制需要在对B的内存复制之前完成。然而,一旦这些操作放入到硬件的内存复制引擎和核函数执行引擎的队列中时,这些依赖性将丢失,因此CUDA驱动程序需要确保硬件的执行单元不破坏流内部的依赖性。也就是说,CUDA驱动程序负责安装这些操作的顺序把它们调度到硬件上执行,这就维持了流内部的依赖性。下图说明了这些依赖性。
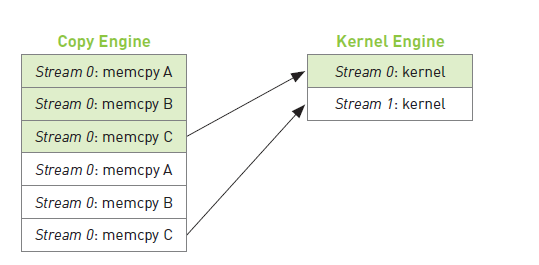
4000
理解了GPU的工作调度原理之后,我们可以得到关于这些操作在硬件上执行的时间线,如下图所示。
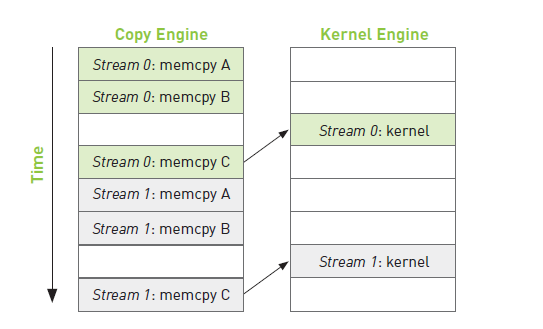
记住,硬件在处理内存复制和核函数执行时分别采用了不同的引擎。因此,将操作放入流中队列中的顺序将影响着CUDA驱动程序调用这些操作以及执行的方式。
2) 高效的运用多个CUDA流
将操作放入流的队列时应采用宽度优先方式而非深度优先。也就是说,不是首先添加第0个流的所有四个操作,然后再添加第1个流的所有四个操作,而是将两个流交叉添加。实际代码如下:
for (int i = 0; i < FULL_DATA_SIZE; i += N * 2)
{
cudaStatus = cudaMemcpyAsync(dev0_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0);
if (cudaStatus != cudaSuccess)
{
printf("cudaMemcpyAsync0 a failed!\n");
}
cudaStatus = cudaMemcpyAsync(dev1_a, host_a + N + i, N * sizeof(int), cudaMemcpyHostToDevice, stream1);
if (cudaStatus != cudaSuccess)
{
printf("cudaMemcpyAsync1 a failed!\n");
}
cudaStatus = cudaMemcpyAsync(dev0_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0);
if (cudaStatus != cudaSuccess)
{
printf("cudaMemcpyAsync0 b failed!\n");
}
cudaStatus = cudaMemcpyAsync(dev1_b, host_b + N + i, N * sizeof(int), cudaMemcpyHostToDevice, stream1);
if (cudaStatus != cudaSuccess)
{
printf("cudaMemcpyAsync1 b failed!\n");
}
kernel << <N / GPUBLOCKNUM, GPUTHREADNUM, 0, stream0 >> >(dev0_a, dev0_b, dev0_c);
kernel << <N / GPUBLOCKNUM, GPUTHREADNUM, 0, stream1 >> >(dev1_a, dev1_b, dev1_c);
cudaStatus = cudaMemcpyAsync(host_c + i, dev0_c, N * sizeof(int), cudaMemcpyDeviceToHost, stream0);
if (cudaStatus != cudaSuccess)
{
printf("cudaMemcpyAsync0 c failed!\n");
}
cudaStatus = cudaMemcpyAsync(host_c + N + i, dev1_c, N * sizeof(int), cudaMemcpyDeviceToHost, stream1);
if (cudaStatus != cudaSuccess)
{
printf("cudaMemcpyAsync1 c failed!\n");
}
}此时,如果内存复制操作的时间与核函数执行的时间大致相当,那么新的执行时间线如下图所示。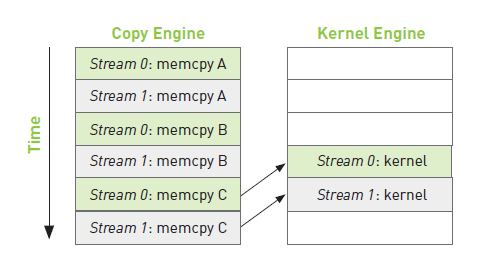
假设复制操作需要时间a,核函数执行需要时间b,则有
当a ≈ b时,时间线长度约为6a。
当a > b时,时间线为6a。
当a < b时,时间线长度为4a + 2b。此时,修改放入流的任务的顺序,将获得更好的时间效率5a + 1b。
具体程序源码:https://github.com/ZYMing/CUDA_Samples/tree/master/stream

相关文章推荐
- CUDA搭建
- 一个程序来比较cuda/c在GPU/CPU的运行效率
- cuda之二维数组的高效内存管理(cudaMallocPitch/cudaMemcpy2D)
- Some Notes of Caffe Installation
- 用python做GPU计算(1)——安装以及配置
- Nvidia硬解码总结
- GPU(CUDA)学习日记(三)------ CUDA基本架构介绍以及编程入门!
- vs2008--CUDA环境配置
- window 下 pycuda 安装运行
- CUDA技术帖: 3D texture linear data VS 3D cudaArray
- 一个你可能不知道的cuda细节
- py-faster-rcnn训练笔记(ubuntu14.04+cuda7.5+cuDNNv3+Python2.7)
- ubuntu14.04安装cuda7.5 cudnn
- CUDA编程之树状加法
- NVIDIA CUDA统一计算设备架构编程手册(1)
- Ubuntu14.04 安装 cuda 7.5
- CUDA中文教程01之心得体会
- CUDA中文教程03之心得体会
- 【GPU开发笔记】二:CUDA初探——查询设备
- cuda一些小问题(不断更新)