CentOS6.8 + cuda + caffe安装记录 (之二 caffe测试)
2016-09-05 16:05
597 查看
作者默认在读该文之前,已经成功安装了caffe。
若尚未安装并且操作系统为CentOS,请移步http://blog.csdn.net/u011636440/article/details/52440207;
若尚未安装并且操作系统为Ubuntu,请移步http://blog.csdn.net/u011636440/article/details/52438666
在make all,make test和make runtest执行过之后,便认为caffe可以使用了。但是是不是真的可以用呢?这里便需要通过实际的例子来跑一下,看一下caffe跑完以后究竟会产生什么。
Caffe包中有给出的已经写好的脚本,可以直接运行。其实如果只是想看看运行完成后是什么样的,不需要了解内部的原理,只需要三行命令就够了(这三行命令均在caffe-master下执行)。以mnist为例:
下面来解释一下这都是干嘛的。
首先mnist是大牛提出了的最早的神经网络进行图片识别的经典例子,用来识别图片中的手写数字,当然这些图片是都是经过大小归一和中心化的。
get_mnist.sh是用来下载数据的脚本,所以上面第一行命令是用来获取测试数据的。当然也可以自己从官网下载。个人觉得这样比较简便。下载成功会有如下两个数据集:/data/mnist/mnist-train-leveldb和/data/mnist/mnist-test-leveldb
create_mnist.sh是把下载下来的数据转换为caffe可以处理的数据类型的脚本。执行完成后在/example/mnist中会多两个文件mnist_test_lmdb和mnist_train_lmdb。
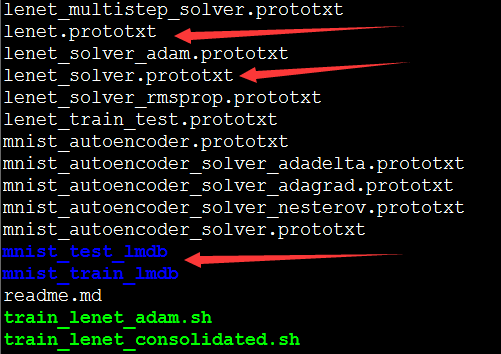
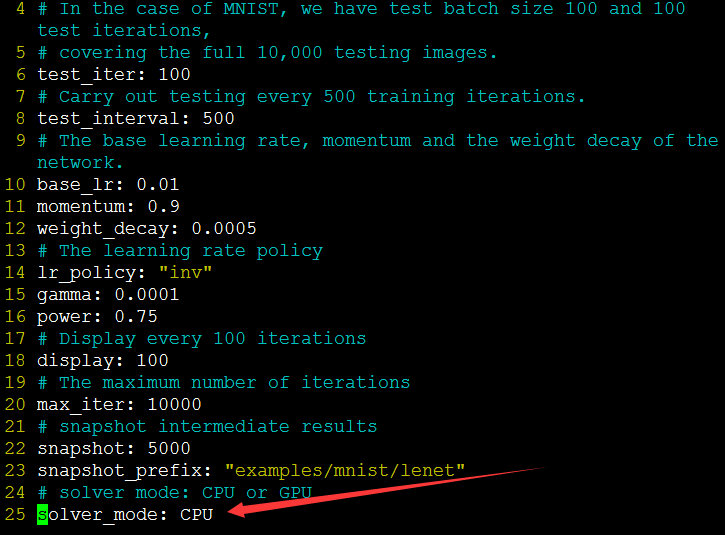
train_mnist.sh是进行训练的脚本,但是在训练之前,需要认识一下两个文件,lenet.prototxt和lenet_solver.prototxt。lenet.prototxt中放了网络的配置信息,包括网络中分了多少层,每一层有多少个节点等;lenet_solver.prototxt是运行时的网络条件,因为我的在安装caffe时只有CPU配置,所以在训练之前要把lenet_solver.prototxt的最后一行处理器配置改为CPU
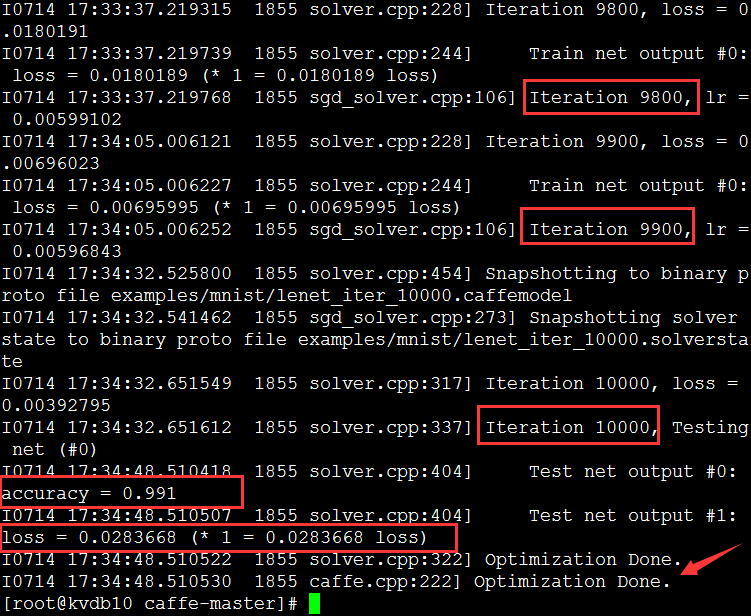
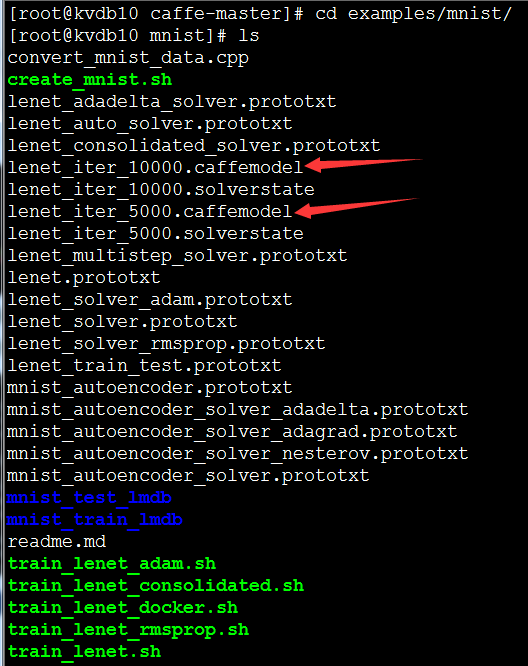
训练时,官方给出的mnist网络,会每迭代100次打印一下损失信息,迭代10000次然后结束。训练结束后文件夹中多了结果文件caffemodel,里边存的是网络中各节点的参数,存的是二进制文件,使用vim编辑器打开是乱码,但是caffemodel就可以使用Python调用了。
若尚未安装并且操作系统为CentOS,请移步http://blog.csdn.net/u011636440/article/details/52440207;
若尚未安装并且操作系统为Ubuntu,请移步http://blog.csdn.net/u011636440/article/details/52438666
在make all,make test和make runtest执行过之后,便认为caffe可以使用了。但是是不是真的可以用呢?这里便需要通过实际的例子来跑一下,看一下caffe跑完以后究竟会产生什么。
Caffe包中有给出的已经写好的脚本,可以直接运行。其实如果只是想看看运行完成后是什么样的,不需要了解内部的原理,只需要三行命令就够了(这三行命令均在caffe-master下执行)。以mnist为例:
./data/mnist/get_mnist.sh ./examples/mnist/create_mnist.sh ./examples/mnist/train_lenet.sh
下面来解释一下这都是干嘛的。
首先mnist是大牛提出了的最早的神经网络进行图片识别的经典例子,用来识别图片中的手写数字,当然这些图片是都是经过大小归一和中心化的。
get_mnist.sh是用来下载数据的脚本,所以上面第一行命令是用来获取测试数据的。当然也可以自己从官网下载。个人觉得这样比较简便。下载成功会有如下两个数据集:/data/mnist/mnist-train-leveldb和/data/mnist/mnist-test-leveldb
create_mnist.sh是把下载下来的数据转换为caffe可以处理的数据类型的脚本。执行完成后在/example/mnist中会多两个文件mnist_test_lmdb和mnist_train_lmdb。
train_mnist.sh是进行训练的脚本,但是在训练之前,需要认识一下两个文件,lenet.prototxt和lenet_solver.prototxt。lenet.prototxt中放了网络的配置信息,包括网络中分了多少层,每一层有多少个节点等;lenet_solver.prototxt是运行时的网络条件,因为我的在安装caffe时只有CPU配置,所以在训练之前要把lenet_solver.prototxt的最后一行处理器配置改为CPU
训练时,官方给出的mnist网络,会每迭代100次打印一下损失信息,迭代10000次然后结束。训练结束后文件夹中多了结果文件caffemodel,里边存的是网络中各节点的参数,存的是二进制文件,使用vim编辑器打开是乱码,但是caffemodel就可以使用Python调用了。

相关文章推荐
- CentOS6.8 + cuda + caffe安装记录 (之四 GPU安装)
- CentOS6.8 + cuda + caffe安装记录 (之五 cuda安装)
- 大数据之Hadoop平台(二)Centos6.5(64bit)Hadoop2.5.1伪分布式安装记录,wordcount运行测试
- Caffe + Ubuntu 15.04/16.04 + CUDA 7.5/8.0 在服务器上安装配置及卸载重新安装(已测试可执行)
- ubuntu16.04+gtx1060+cuda8.0+caffe安装、测试经历
- cuda测试caffe编译安装
- [转]Centos6.5+CUDA6.5+caffe安装配置及可能遇到问题解答
- Caffe+Ubuntu 14.04 + Cuda6.5 新手安装记录
- NVIDIA DIGITS 5.1-dev学习笔记之安装过程记录:Windows10 x64位系统 、 MicroSoft Caffe Master、CUDA 8.0 、Python 2.7
- ubuntu16.04+gtx1070/1060+cuda8.0+caffe安装、测试[亲测]
- 测试环境下将centos6.8升级到centos7的操作记录(转)
- Intel+Nvidia双显卡笔记本Linuxmint18下安装CUDA+OpenCV+Caffe安装记录
- CentOS6.5虚拟机安装Caffe大致记录
- CentOS6.8安装caffe的几点注意事项
- 在CentOS6.5中安装和测试puppet的实践记录
- Caffe安装过程记录(CentOS,无独立显卡,无GPU)
- Intel+Nvidia双显卡笔记本Linuxmint18下安装CUDA+OpenCV+Caffe的安装记录
- cuda7.5+cudnn5.1+opencv3.1(ubuntu14.04上安装caffe并测试)
- [转]CentOS6.5虚拟机安装Caffe大致记录
- [转]Caffe安装过程记录(CentOS,无独立显卡,无GPU)