机器学习之K-近邻算法(Python描述)基础
2016-09-03 20:03
302 查看
Python 2.7
IDE Pycharm 5.0.3
numpy 1.11.0

根据这个伪代码流程,我们就可以使用python进行算法重构了,分三步,一算距离,二排序,三取值
第二部分,主程序部分,只要将主程序和被调函数放在同一工作目录下,直接运行主程序即可
跑出来大概是这样的:
从图形上分析
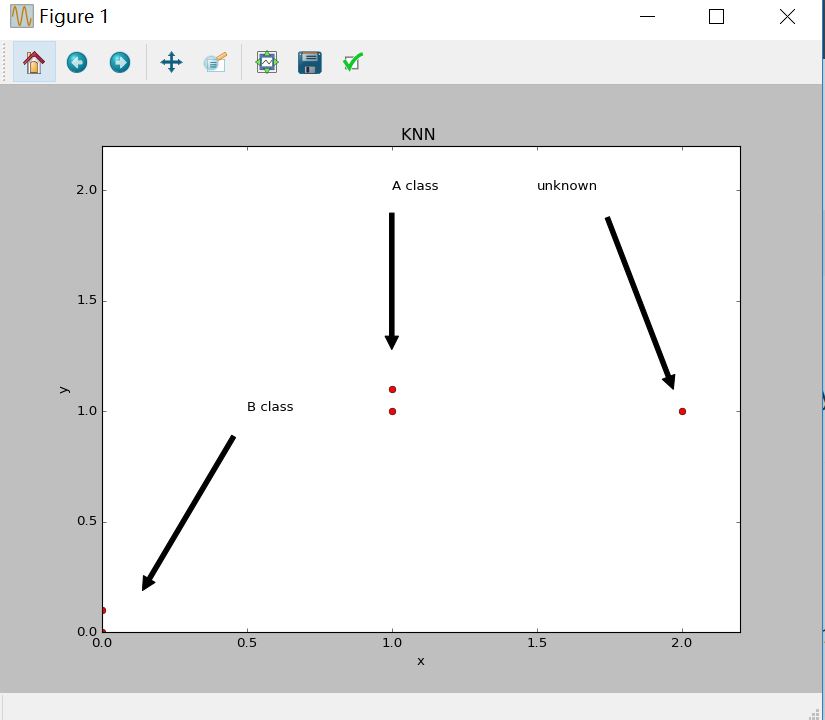
从上图可以看出,我测试的点是(2,1),明显可以看出它是距离A类比较靠近,所以归属于A类没有问题。
再从算法上分析;
计算unknown点到每个点的距离,然后取最小距离的K个点,在K个点中,哪个类出现的概率高就归属于哪一类,应该没什么问题了。
附加:上述代码中出现的方法使用解析
sum(axis= ),行(列)相加形成新的行(列)
tile(a,(n,m)),将数组a的行重复n次,列重复m次
dict.get(k,d)
get相当于一条if…else…语句,参数k在字典中,字典将返回dict[k]也就是k对应的value值;如果参数k不在字典中则返回参数d。
举栗子
.iteritems()迭代器的使用
机器学习实战.Peter Harrington著
@jihite–字典访问的三种方法
@MrLevo520–numpy快速入门
IDE Pycharm 5.0.3
numpy 1.11.0
前言
总算迈入机器学习第一步,总比原地踏步要好。
什么是K-近邻?
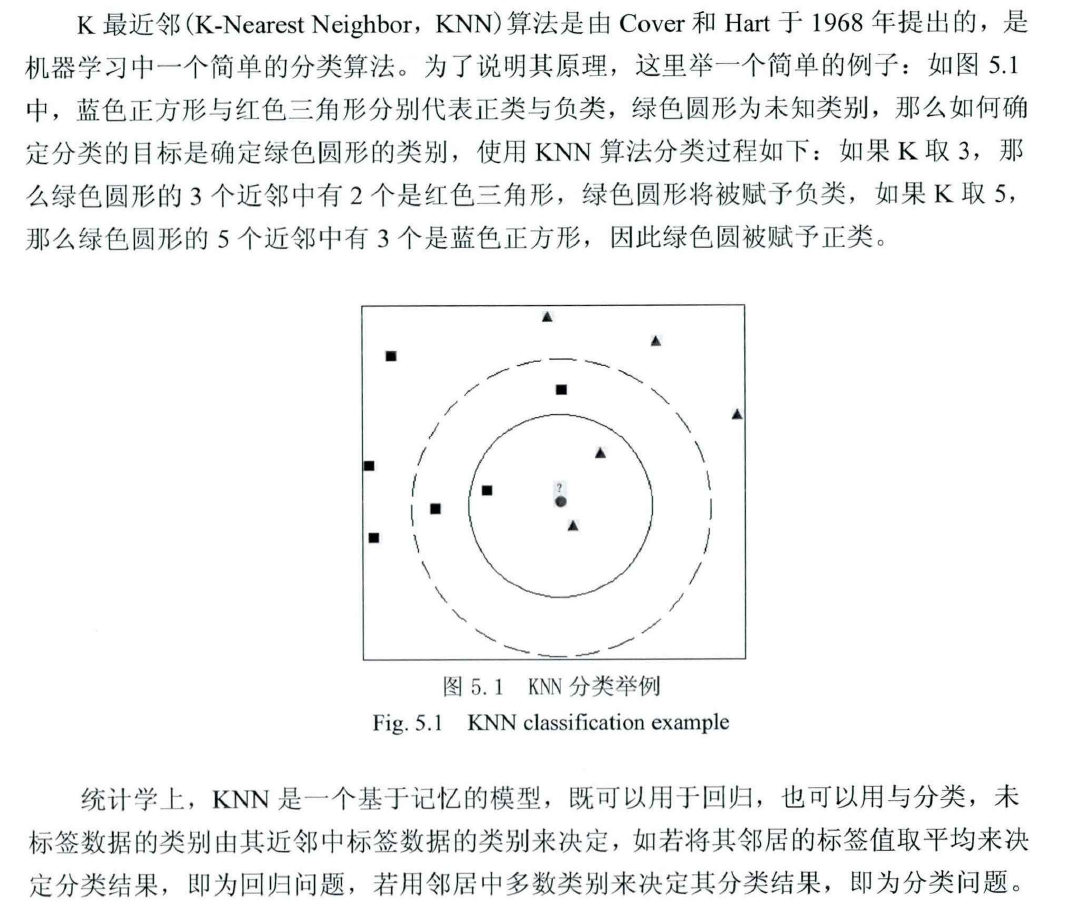
一句话总结,物以类聚,人以群分,更‘靠近’哪一个点,就认为它属于那一个点。以一篇硕士论文截图说明Knn算法思想
根据这个伪代码流程,我们就可以使用python进行算法重构了,分三步,一算距离,二排序,三取值
实现Knn基础代码
第一部分,被调函数,在主程序中需要导入# -*- coding: utf-8 -*-
from numpy import *
import operator
def creatDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
def classify0(inX,dataSet,labels,k): # inX用于需要分类的数据,dataSet输入训练集
######输入与训练样本之间的距离计算######
dataSetSize = dataSet.shape[0] # 读取行数,shape[1]则为列数
diffMat = tile(inX,(dataSetSize,1))-dataSet # tile,重复inX数组的行(dataSize)次,列重复1
sqDiffMat = diffMat**2 #平方操作
sqDistances = sqDiffMat.sum(axis=1) # 每一个列向量相加,axis=0为行相加
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort() # argsort函数返回的是数组值从小到大的索引值
#print sortedDistIndicies #产生的是一个排序号组成的矩阵
classCount={}
######累计次数构成字典######
for i in range(k):
#print sortedDistIndicies[i]
voteIlabel = labels[sortedDistIndicies[i]] #排名前k个贴标签
#print voteIlabel
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1 # 不断累加计数的过程,体现在字典的更新中
#print classCount.get(voteIlabel,0)
#print classCount
#get(key,default=None),就是造字典
######找到出现次数最大的点######
sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse=True)
#以value值大小进行排序,reverse=True降序
#print classCount.iteritems()
#print sortedClassCount
#key = operator.itemgetter(1),operator.itemgetter函数获取的不是值,而是定义了一个函数,通过该函数作用到对象上才能获取值
return sortedClassCount[0][0]
#返回出现次数最多的value的key第二部分,主程序部分,只要将主程序和被调函数放在同一工作目录下,直接运行主程序即可
# -*- coding: utf-8 -*-
import Knn_bymyself
group,labels = Knn_bymyself.creatDataSet() # 调用Knn_bymyself中的creatDataSet()方法
while 1:
try:
a=input('please input x:')
b=input('please input y:')
#classify0(inX,dataSet,labels,k)对应起来看
print 'belong to :'+Knn_bymyself.classify0([a,b],group,labels,3)+' class'
except:
break跑出来大概是这样的:
please input x:2 please input y:1 belong to :A class
分析一下
group也就是输入训练集,label就是训练集代表的标签从图形上分析
从上图可以看出,我测试的点是(2,1),明显可以看出它是距离A类比较靠近,所以归属于A类没有问题。
再从算法上分析;
计算unknown点到每个点的距离,然后取最小距离的K个点,在K个点中,哪个类出现的概率高就归属于哪一类,应该没什么问题了。
你可能需要的知道
先过一眼NumPy快速入门→点击这里快速学习NumPy附加:上述代码中出现的方法使用解析
In[138]: marray Out[138]: array([[1, 2, 3], [4, 5, 6]])
sum(axis= ),行(列)相加形成新的行(列)
In[135]: marray.sum(axis=0) Out[135]: array([5, 7, 9])
tile(a,(n,m)),将数组a的行重复n次,列重复m次
In[136]: b = tile(marray,(2,3)) In[137]: b Out[137]: array([[1, 2, 3, 1, 2, 3, 1, 2, 3], [4, 5, 6, 4, 5, 6, 4, 5, 6], [1, 2, 3, 1, 2, 3, 1, 2, 3], [4, 5, 6, 4, 5, 6, 4, 5, 6]])
dict.get(k,d)
get相当于一条if…else…语句,参数k在字典中,字典将返回dict[k]也就是k对应的value值;如果参数k不在字典中则返回参数d。
举栗子
In[149]: dict = {'A':1,'B':2}
In[150]: dict.get('A',0)
Out[150]: 1
In[151]: dict.get('C',1)
Out[151]: 1.iteritems()迭代器的使用
#使用next()
In[165]: dict.iteritems().next()
Out[164]: ('A', 1)
#使用for循环
In[169]: for i in dict.iteritems():
... print i
...
('A', 1)
('B', 2)
#转化成list之后检索
In[170]: list_dict = list(dict.iteritems())
In[171]: list_dict[0]
Out[170]: ('A', 1)最后
这里只是解释了如何使用最基本的KNN的方法,代码也是最简单的,配合图的讲解,应该会更加清楚一些,代码我抄自机器学习,但是它的解释比较少,算是加上了自己的备注,也算是自己的一个学习过程吧,希望对你也有帮助
附录
如果你对那副点阵图感兴趣,也是用python写的代码如下,可作参考。# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
plt.title("KNN ")
plt.xlim(xmax=2.2,xmin=0)
plt.ylim(ymax=2.2,ymin=0)
#标识箭头
plt.annotate("unknown", xy = (2, 1), xytext = (1.5, 2), arrowprops = dict(facecolor = 'black', shrink = 0.1))
plt.annotate("A class", xy = (1, 1.2), xytext = (1, 2), arrowprops = dict(facecolor = 'black', shrink = 0.1))
plt.annotate("B class", xy = (0.1,0.1), xytext = (0.5,1), arrowprops = dict(facecolor = 'black', shrink = 0.1))
plt.xlabel("x")
plt.ylabel("y")
plt.plot([1,1,0,0],[1.1,1,0,0.1],'ro') # A.B类的点阵
plt.plot([2],[1],'ro') # unknown点
plt.show()致谢
利用python进行数据分析.Wes McKinney著机器学习实战.Peter Harrington著
@jihite–字典访问的三种方法
@MrLevo520–numpy快速入门

相关文章推荐
- 机器学习之K-近邻算法(Python描述)实战百维万组数据
- 机器学习之K-means算法(Python描述)基础
- 机器学习(K-近邻算法)Python的基础知识
- 机器学习之k-近邻(kNN)算法与Python实现
- ZH奶酪:【数据结构与算法】基础排序算法总结与Python实现
- Python语言实现机器学习的K-近邻算法
- 数论基础算法总结(python版)
- 零基础Python教程:如何实现PCA算法
- 机器学习之K-近邻算法
- python机器学习之 K-近邻算法
- <Python><有监督>kNN--近邻分类算法
- K近邻分类算法实现 in Python
- 学点PYTHON基础的东东--数据结构,算法,设计模式---访问者模式
- K近邻分类算法实现 in Python
- K-近邻算法之Python实现
- Python语言实现机器学习的K-近邻算法
- K-近邻算法python实现
- [Python脚本]——基础算法篇之查找
- 机器学习经典算法详解及Python实现--K近邻(KNN)算法
- 机器学习 & python 使用k-近邻算法改进约会网站的配对效果