<<Spark Streaming Programming Guide>> - Part 3 转换操作
2016-08-30 22:47
507 查看
如前所述,DStream其实是内部一系列的不同时间点的RDD构成,因此大部分RDD的转换操作,DStream都支持。其中一些操作在下面会详细解释。
updateStateByKey用于有状态的批处理,在每次批处理时updateStateByKey根据当前批处理产生的该key的value来更新之前保存的全局value,例如要记录从程序开始运行到现在每个word的总体count数,这是我们需要记录每个word跨batch的状态,即需要用每次批处理统计的word count来加上总体的count数。实现有状态的批处理需要两步 -
1. 定义一个全局状态,可以任意类型;
2. 定义一个函数,用来定义如何根据当前批处理统计的值来更新全局状态;
在每次批处理的时候,Spark Streaming都会去更新所有key的全局状态,无论当前批处理是否有不同的值产生;如果新的状态为None,则当前key会被从全局状态表中删除;
刚才说到的总体word count需要定义的函数样例如下,其中,我们将新值和总体值进行相加。
此函数的调用如下,其中pairs是当前批次每个word对用次数的key-value pair RDD.
需要注意的是, updateStateByKey操作需要指定checkpoint 目录用于存储全局状态,后面会介绍。
高度抽象的方法,可以定义任意RDD to RDD的DStream的操作,所以当封装的转换操作不能满足需求需要自己定制时,则用此方法;例如现成的转换操作里不包括DStream去join一个dataset,一个应用场景是将数据数据流的DStream去join一个垃圾信息的数据集,然后进行过滤,示例代码如下
值得注意的是,如上的函数transform会在每次批处理时都比被调用,这使得我们有机会每次批处理时函数的实现方式以及RDD的分区数等是变化的。
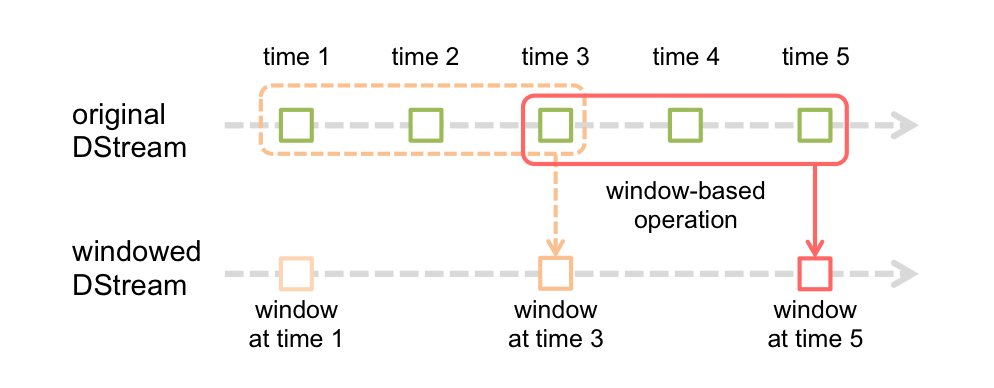
窗口计算操作。对源DStream上放一个滑动窗口,对窗口内的多个RDD(定义为窗口的大小)进行聚合,聚合为目标DStream的一个RDD;下一次迭代窗口大小不变向右平移,平移的步长定义为窗口滑动的间距。例如下图是一个窗口大小为3,步长为2的window操作。
Window操作的一个应用场景,仍然以word count为例,例如想实现每10秒出一个数据 - 计算过去30秒的word count统计结果,在这个例子中,如果原始DStream是每秒的word count统计结果,则窗口操作的窗口大小是30,窗口滑动的间距是10.
代码实现上,假设pair是(word, 1)RDD的DStream
另一种更高效的计算方式是增量方式,即不是每次都重新计算,而是在上一个窗口计算的基础上,加入新滑入窗口的部分,去除滑出窗口的部分,所以这里输入两个函数分别对应对滑入和滑出部分的操作。这种方法虽然高效,但能否使用这种方法取决于问题本身能否使用增量计算的方式,例如统计窗口内数据的标准差,至少我想不到办法通过增量的方式基于上一个窗口的值计算当前窗口的数据离散程度。
附上此函数的signature,附上API文档。
更多的window函数在这里,常用的DStream操作都有支持window操作的版本,所有的操作内都需要指定窗口大小(windowLength)和滑动间距(slideInterval)作为输入参数。
Coming soon...
| Transformation | Meaning |
|---|---|
| map(func) | Return a new DStream by passing each element of the source DStream through a function func. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on which func returns true. |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream and otherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative and commutative so that it can be computed in parallel. |
| countByValue() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| reduceByKey(func, [numTasks]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasksargument to set a different number of tasks. |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| updateStateByKey(func) | Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
UpdateStateByKey 操作
updateStateByKey用于有状态的批处理,在每次批处理时updateStateByKey根据当前批处理产生的该key的value来更新之前保存的全局value,例如要记录从程序开始运行到现在每个word的总体count数,这是我们需要记录每个word跨batch的状态,即需要用每次批处理统计的word count来加上总体的count数。实现有状态的批处理需要两步 -1. 定义一个全局状态,可以任意类型;
2. 定义一个函数,用来定义如何根据当前批处理统计的值来更新全局状态;
在每次批处理的时候,Spark Streaming都会去更新所有key的全局状态,无论当前批处理是否有不同的值产生;如果新的状态为None,则当前key会被从全局状态表中删除;
刚才说到的总体word count需要定义的函数样例如下,其中,我们将新值和总体值进行相加。
def updateFunction(newValues, runningCount): if runningCount is None: runningCount = 0 return sum(newValues, runningCount) # add the new values with the previous running count to get the new count
此函数的调用如下,其中pairs是当前批次每个word对用次数的key-value pair RDD.
runningCounts = pairs.updateStateByKey(updateFunction)
需要注意的是, updateStateByKey操作需要指定checkpoint 目录用于存储全局状态,后面会介绍。
Transform 操作
高度抽象的方法,可以定义任意RDD to RDD的DStream的操作,所以当封装的转换操作不能满足需求需要自己定制时,则用此方法;例如现成的转换操作里不包括DStream去join一个dataset,一个应用场景是将数据数据流的DStream去join一个垃圾信息的数据集,然后进行过滤,示例代码如下spamInfoRDD = sc.pickleFile(...) # RDD containing spam information # join data stream with spam information to do data cleaning cleanedDStream = wordCounts.transform(lambda rdd: rdd.join(spamInfoRDD).filter(...))
值得注意的是,如上的函数transform会在每次批处理时都比被调用,这使得我们有机会每次批处理时函数的实现方式以及RDD的分区数等是变化的。
Window 操作
窗口计算操作。对源DStream上放一个滑动窗口,对窗口内的多个RDD(定义为窗口的大小)进行聚合,聚合为目标DStream的一个RDD;下一次迭代窗口大小不变向右平移,平移的步长定义为窗口滑动的间距。例如下图是一个窗口大小为3,步长为2的window操作。Window操作的一个应用场景,仍然以word count为例,例如想实现每10秒出一个数据 - 计算过去30秒的word count统计结果,在这个例子中,如果原始DStream是每秒的word count统计结果,则窗口操作的窗口大小是30,窗口滑动的间距是10.
代码实现上,假设pair是(word, 1)RDD的DStream
# Reduce last 30 seconds of data, every 10 seconds windowedWordCounts = pairs.reduceByKeyAndWindow(lambda x, y: x + y, 30, 10)
另一种更高效的计算方式是增量方式,即不是每次都重新计算,而是在上一个窗口计算的基础上,加入新滑入窗口的部分,去除滑出窗口的部分,所以这里输入两个函数分别对应对滑入和滑出部分的操作。这种方法虽然高效,但能否使用这种方法取决于问题本身能否使用增量计算的方式,例如统计窗口内数据的标准差,至少我想不到办法通过增量的方式基于上一个窗口的值计算当前窗口的数据离散程度。
# Reduce last 30 seconds of data, every 10 seconds windowedWordCounts = pairs.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)
附上此函数的signature,附上API文档。
| reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks]) | A more efficient version of the above reduceByKeyAndWindow()where the reduce value of each window is calculated incrementally using the reduce values of the previous window. This is done by reducing the new data that enters the sliding window, and “inverse reducing” the old data that leaves the window. An example would be that of “adding” and “subtracting” counts of keys as the window slides. However, it is applicable only to “invertible reduce functions”, that is, those reduce functions which have a corresponding “inverse reduce” function (taken as parameter invFunc). Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. Note that checkpointing must be enabled for using this operation. |
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | Return a new DStream which is computed based on windowed batches of the source DStream. |
| countByWindow(windowLength,slideInterval) | Return a sliding window count of elements in the stream. |
| reduceByWindow(func, windowLength,slideInterval) | Return a new single-element stream, created by aggregating elements in the stream over a sliding interval using func. The function should be associative and commutative so that it can be computed correctly in parallel. |
| reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function func over batches in a sliding window. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasksargument to set a different number of tasks. |
| reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks]) | A more efficient version of the above reduceByKeyAndWindow()where the reduce value of each window is calculated incrementally using the reduce values of the previous window. This is done by reducing the new data that enters the sliding window, and “inverse reducing” the old data that leaves the window. An example would be that of “adding” and “subtracting” counts of keys as the window slides. However, it is applicable only to “invertible reduce functions”, that is, those reduce functions which have a corresponding “inverse reduce” function (taken as parameter invFunc). Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. Note that checkpointing must be enabled for using this operation. |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window. Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. |
Join 操作
Coming soon...

相关文章推荐
- <<Spark Streaming Programming Guide>> - Part 2 基本概念
- <<Spark Streaming Programming Guide>> - Part 1 综述
- <转>Spark Streaming中的操作函数分析
- 用char*实现的一个完整的类,包含类的基本操作:一般构造、拷贝构造、赋值转换、重载 > >,< <
- “无法更新EntitySet“*****”,因为它有一个DefiningQuery,而<ModificationFunctionMapping>元素中没有支持当前操作的<InsertFunction>元素”问题的解决方法
- spark streaming programming guide 快速开始(二)
- Spark Streaming 3:转换操作
- <<、>>、>>>移位操作
- Spark1.1.0 Spark Streaming Programming Guide
- Java移位操作>>,>>>与<<
- <转>Sparkstreaming reduceByKeyAndWindow(_+_, _-_, Duration, Duration) 的源码/原理解析
- spark文档学习1 Spark Streaming Programming Guide
- spark streaming programming guide 基础概念之初始化StreamingContext(三b)
- 关于JavaScript针对<ul><li>的一些操作
- <转>Spark Streaming:大规模流式数据处理的新贵
- <转>Spark Streaming实时计算框架介绍
- 智能dom4操作xml<->转换
- <转>Npoi导入导出Excel操作<载>
- 用char*实现的一个完整的类,包含类的基本操作:一般构造、拷贝构造、赋值转换、重载 > >,< <
- spark streaming programming guide 基础概念之linking(三a)