浅读HDFS文件上传部分的过程源码
2016-08-30 09:39
316 查看
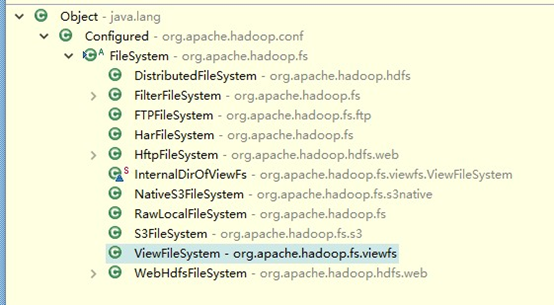
FileSystem类的继承结构
FileSystem的文件注释:
An abstract base class for a fairly generic filesystem. It may be implemented as a distributed filesystem, or as a "local" one that reflects the locally-connected disk.
The local version exists for small Hadoop instances and for testing. All user code that may potentially use the Hadoop Distributed File System should be written to use a FileSystem object.
The Hadoop DFS is a multi-machine system that appears as a single disk. It's useful because of its fault tolerance and potentially very large capacity. The local implementation is LocalFileSystem and distributed implementation is DistributedFileSystem.
FileSystem的文件译文:
一个通用文件系统的抽象基类。可以被分布式文件系统或者本地文件系统实现;如果分布式文件系统实现连接到分布式文件系统。本地文件系统实现的话,将会连接本地磁盘。
本地版本的存在是为了小规模hadoop实例或者测试用。所有的用户代码如果需要使用hdfs的都需要使用FileSystem对象。hdfs是将多个机器组成近视看做是一块磁盘。它的高容错和强大的存储能力是非常有用的。FileSystem的本地实现是LocalFileSystem,分布式实现是DistributedFileSystem。
上传文件源码过程:
第一步:创建配置实例,然后获取FileSystem实例。

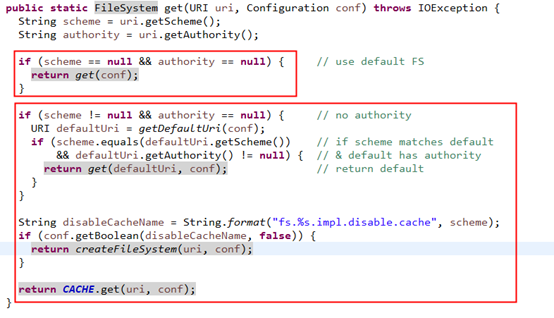
第一个红色框:如果scheme和authority都为空的话,在if条件语句中get函数中最终调用

返回本地文件系统实例,即为:LocalFileSystem实例。(DEFAULT_FS = file:///可以看出是本地文件系统)
第二个红色框:如果scheme的值为hdfs,则根据authority的值来进行创建DistributedFileSystem实例。
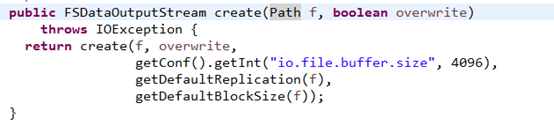
第二步:FSDataOutputStream是hdfs文件系统的输出流。

底层调用:
f是hdfs文件系统的文件路径,overwrite文件存在是否覆盖重写。
第三步:创建本地文件输入流,将本地文件输入流复制到hdfs文件的输出流中。IOUtils是hadoop的一个I/O工具类(自行查看文档,不再介绍)。

第四步:关闭文件流即可。
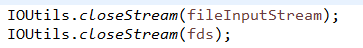
FileSystem的文件注释:
An abstract base class for a fairly generic filesystem. It may be implemented as a distributed filesystem, or as a "local" one that reflects the locally-connected disk.
The local version exists for small Hadoop instances and for testing. All user code that may potentially use the Hadoop Distributed File System should be written to use a FileSystem object.
The Hadoop DFS is a multi-machine system that appears as a single disk. It's useful because of its fault tolerance and potentially very large capacity. The local implementation is LocalFileSystem and distributed implementation is DistributedFileSystem.
FileSystem的文件译文:
一个通用文件系统的抽象基类。可以被分布式文件系统或者本地文件系统实现;如果分布式文件系统实现连接到分布式文件系统。本地文件系统实现的话,将会连接本地磁盘。
本地版本的存在是为了小规模hadoop实例或者测试用。所有的用户代码如果需要使用hdfs的都需要使用FileSystem对象。hdfs是将多个机器组成近视看做是一块磁盘。它的高容错和强大的存储能力是非常有用的。FileSystem的本地实现是LocalFileSystem,分布式实现是DistributedFileSystem。
上传文件源码过程:
第一步:创建配置实例,然后获取FileSystem实例。
第一个红色框:如果scheme和authority都为空的话,在if条件语句中get函数中最终调用
返回本地文件系统实例,即为:LocalFileSystem实例。(DEFAULT_FS = file:///可以看出是本地文件系统)
第二个红色框:如果scheme的值为hdfs,则根据authority的值来进行创建DistributedFileSystem实例。
第二步:FSDataOutputStream是hdfs文件系统的输出流。
底层调用:
f是hdfs文件系统的文件路径,overwrite文件存在是否覆盖重写。
第三步:创建本地文件输入流,将本地文件输入流复制到hdfs文件的输出流中。IOUtils是hadoop的一个I/O工具类(自行查看文档,不再介绍)。
第四步:关闭文件流即可。

相关文章推荐
- HDFS dfsclient读文件过程 源码分析
- struts2 文件上传和下载,以及部分源码解析
- curl查看网页源码/自动跳转/显示头信息/显示通信过程/发送表单信息/文件上传/Referer字段/User Agent
- HDFS dfsclient写文件过程 源码分析
- Hadoop之HDFS原理及文件上传下载源码分析(下)
- HDFS dfsclient读文件过程 源码分析
- Hadoop之HDFS原理及文件上传下载源码分析(上)
- HDFS dfsclient写文件过程 源码分析
- struts2 文件上传和下载,以及部分源码解析
- HDFS dfsclient写文件过程 源码分析
- 使用curl查看网页源码/自动跳转/显示头信息/显示通信过程/发送表单信息/文件上传/Referer字段/User Agent
- RPC和HDFS文件读写(下载上传)过程
- hdfs源码剖析文件写入过程时序图
- struts2 文件上传 和部分源码解析,以及一般上传原理
- python 实现自动上传文件到百度网盘(附程序源码及实现过程)
- hdfs上传文件的源码分析
- HDFS dfsclient写文件过程 源码分析
- #舍得Share#php开发笔记-使用curl查看网页源码/自动跳转/显示头信息/显示通信过程/发送表单信息/文件上传/Referer字段/User Agent
- Hadoop之HDFS原理及文件上传下载源码分析(下)