使用python爬取豆瓣读书小说标签下的所有图书
2016-08-28 13:13
141 查看
在慕课网学习了python开发简单爬虫,爬取了python百度百科相关1000个词条页面。了解了简单爬虫的基本结构。为了进一步掌握简单爬虫,尝试着爬取豆瓣图书小说标签下的所有图书的书名,作者,评分,简介,并使用网页进行输出。 实现方式如下: 1.编写主调度函数: 豆瓣读书小说标签下,每页共20本图书,总共99页。url格式为“https://book.douban.com/tag/小说?start=(20的倍数)&type=T”,每页可获取到20本图书的url链接并进行爬取小说的具体信息。循环99次,可完成本次爬取目标。中间加入异常处理,防止有些图书的url失效等异常情况。加入time.sleep(),每次爬取后停止一段时间,防止豆瓣的反爬虫识别出程序导致爬虫失败。
#coding=UTF-8
from douban import d_urlmanagement, d_httpdownloader, d_httpparser,\
d_httpoutputer
import time
import sys
reload(sys)
sys.setdefaultencoding('utf8')
class DoubanMain(object):
def __init__(self):
self.durls=d_urlmanagement.Durlmanagement()
self.ddownload=d_httpdownloader.Dhttpdownloader()
self.dparser=d_httpparser.Dhttpparser()
self.doutputer=d_httpoutputer.Dhttpoutputer()
def crow(self):
pag_num=0
while(1):
#https://book.douban.com/tag/小说?start=40&type=T
url='https://book.douban.com/tag/小说'+'?start='+str(pag_num*20)+'&type=T'
print '%d page'%pag_num
time.sleep(0.1)
html_cont=self.ddownload.download(url)
new_urls=self.dparser.parser(html_cont,url)
self.durls.add_new_urls(new_urls)
n=1
while self.durls.has_new_url():
try:
book_url= self.durls.get_new_url()
time.sleep(0.1)
book_cont=self.ddownload.download(book_url)
new_datas=self.dparser.book_parser(book_url,book_cont)
self.doutputer.collectdata(new_datas)
print n
n=n+1
e
4000
xcept:
print 'error'
continue
if pag_num >=51:
break
pag_num = pag_num +1
self.doutputer.ouput()
if __name__=='__main__':
douban=DoubanMain()
douban.crow()2.编写url管理器:
url管理器,用于豆瓣读书小说标签页下每页的20本图书的url保存及提取。
#coding=UTF-8 class Durlmanagement(object): def __init__(self): self.new_urls=set() self.old_urls=set() def add_new_urls(self,urls): if urls is None or len(urls)==0: return for url in urls: if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) return self.new_urls def get_new_url(self): if self.new_urls is None: return new_url=self.new_urls.pop() self.old_urls.add(new_url) return new_url def has_new_url(self): return len(self.new_urls)!=0
3.编写网页下载器:
使用python自带的urllib2模块进行网页下载,加入头信息伪装成mozilla浏览器进行访问,目的也是为了避免豆瓣自身的反爬虫机制。
在爬虫运行过程中,出现爬虫假死状态,分析为爬虫无法打开某一网页,所以设置一个超时时间进行控制。
response=urllib2.urlopen(request,timeout=1)
#coding=UTF-8
import urllib2
class Dhttpdownloader(object):
def download(self,url):
if url is None:
return None
try:
request=urllib2.Request(url)
request.add_header('User-Agent','Mozilla/5.0' )
response=urllib2.urlopen(request)
except urllib2.URLError,e:
if hasattr(e,'code'):
print e.code
if hasattr(e,'reason'):
print e.reason
if response.getcode()!=200:
return None
return response.read()4.编写网页解析器:
网页解析器使用第三方库BeautifulSoup模块进行解析,加入正则表达式进行匹配。parser方法用于解析豆瓣读书小说标签页的具体内容,提取出每本图书的url。book_parser方法用于解析具体图书页面的信息,提取出书名,作者,评分,简介信息,保存至data中。
#coding=UTF-8
from bs4 import BeautifulSoup
import re
class Dhttpparser(object):
def _get_new_urls(self, soup):
new_urls=set()
links=soup.find_all('a',href=re.compile(r'https://book.douban.com/subject/\d+\/'),title=re.compile(r"."))
if links is None:
return
for link in links:
new_url=link['href']
new_urls.add(new_url)
return new_urls
def _get_new_datas(self, soup, book_url):
new_datas={}
#<span property="v:itemreviewed">人生的枷锁</span>
#书名
new_datas['book_name']=soup.find('span',property='v:itemreviewed').string
#<strong class="ll rating_num " property="v:average"> 9.0 </strong>
#评分
new_datas['book_score']=soup.find('strong',class_='ll rating_num ').string
#<span>
#<span class="pl"> 作者</span>:
# <a href="/search/%E6%AF%9B%E5%A7%86">[英] 毛姆</a>
#</span>
#作者
info = soup.find('div', id='info')
new_datas['book_author'] = info.find(text=' 作者').next_element.next_element.string
#书籍简介
intro_datas=soup.find('div',class_='intro').strings
new_datas['book_introduction']=''
for string in intro_datas:
new_datas['book_introduction']=new_datas['book_introduction']+str(string)
#书籍url
new_datas['book_url']=book_url
return new_datas
def parser(self,html_cont,url):
if html_cont is None:
return
soup=BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8')
new_urls=self._get_new_urls(soup)
return new_urls
def book_parser(self,book_url,book_cont):
if book_url is None or book_cont is None:
return
soup=BeautifulSoup(book_cont,'html.parser',from_encoding='utf-8')
new_datas=self._get_new_datas(soup,book_url)
return new_datas5-1.编写网页输出器:
收集提取出的图书具体信息,使用网页进行输出。网页前加入fount.write(‘’)
,用于告诉浏览器为utf-8编码,防止输出中文为乱码。
#coding=UTF-8
class Dhttpoutputer(object):
def __init__(self):
self.datas=[]
def ouput(self):
fount=open('douban.html','w')
fount.write('<html>')
fount.write('<meta http_equiv="Content-Type" content="text/html" charset="utf-8">')
fount.write('<body>')
fount.write('<table>')
for data in self.datas:
fount.write('<tr>')
fount.write('<td>%s</td>'%data['book_name'].encode('utf8'))
fount.write('<td>%s</td>'%data['book_score'])
fount.write('<td>%s</td>'%data['book_author'].encode('utf8'))
fount.write('<td>%s</td>'%data['book_introduction'].encode('utf8'))
fount.write('<td>%s</td>'%data['book_url'].encode('utf8'))
fount.write('</tr>')
fount.write('</table>')
fount.write('</body>')
fount.write('</html>')
fount.close()
def collectdata(self,data):
if data is None:
return
self.datas.append(data)5-2.编写输出器输出到excel文本中:
对excel文本文件的操作,使用python第三方库xlwt,
import xlwt
class Dhttpoutputer(object):
def __init__(self):
self.datas=[]
def ouput(self):
work=xlwt.Workbook(encoding='utf-8')
sheet=work.add_sheet(u'sheet')
sheet.write(0,0,'书名')
sheet.write(0,1,'作者')
sheet.write(0,2,'评分')
sheet.write(0,3,'简介')
sheet.write(0,4,'url')
n=1
for data in self.datas:
sheet.write(n,0,data['book_name'].encode('utf8'))
sheet.write(n,1,data['book_author'].encode('utf8'))
sheet.write(n,2,data['book_score'])
sheet.write(n,3,data['book_introduction'].encode('utf8'))
sheet.write(n,4,data['book_url'].encode('utf8'))
n=n+1
work.save(u'douban.xls'.encode('utf8'))
def collectdata(self,data):
if data is None:
return
self.datas.append(data)爬取的结果:
html格式:
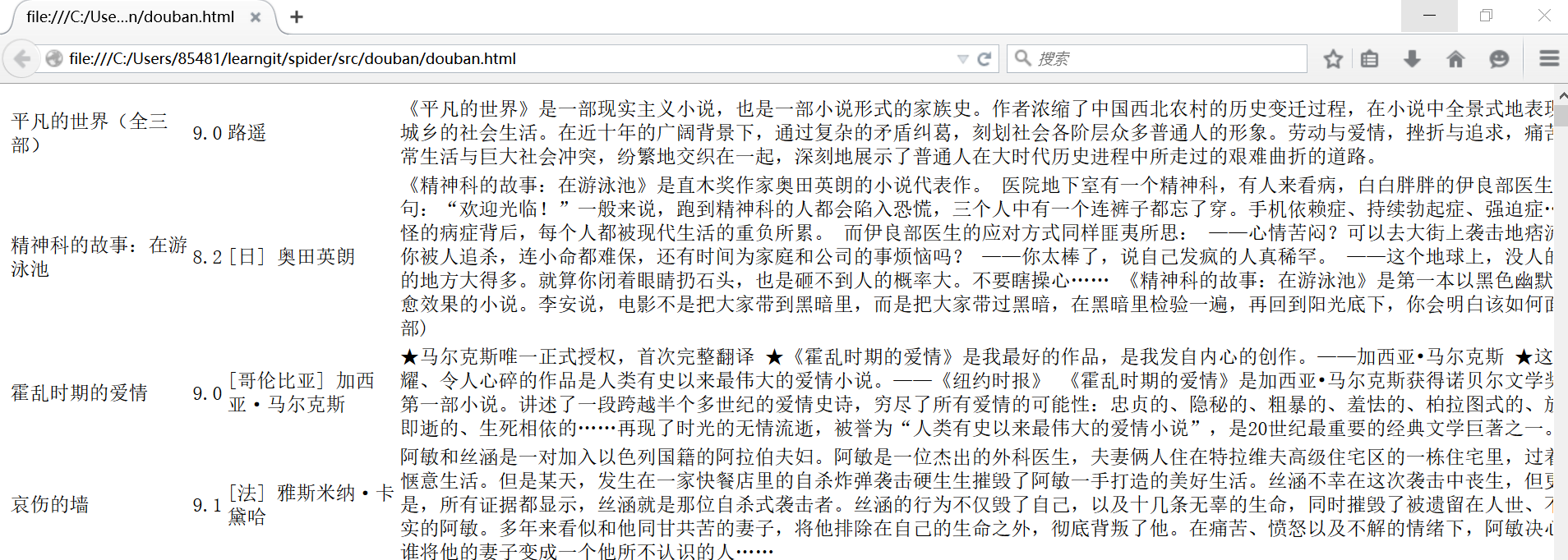
excel格式:
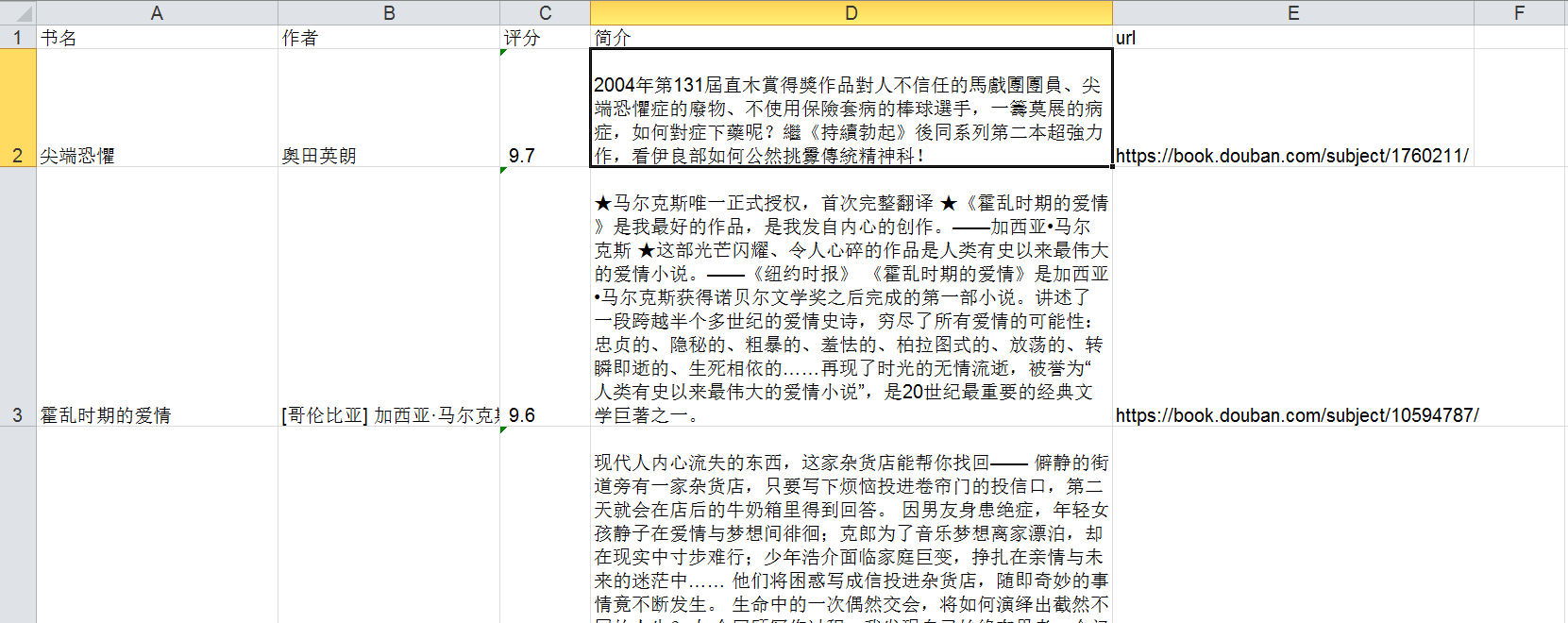
以上,就是爬取豆瓣读书小说标签页面下的所有图书信息的程序,刚开始学习python爬虫,路漫漫而修远兮,吾将上下而求索。

相关文章推荐
- 使用Python正则表达式从文章中取出所有图片路径
- 使用Python去除C/C++源程序中的所有注释和空行
- 使用Python获取所有非偶数尺寸图片资源信息
- 如何使用Python获取某个路径下面所有文件的绝对路径以及其他操作
- 使用python抓取CSDN关注人的所有发布的文章
- 使用Python调用工作目录下所有快捷方式
- Python怎么使用beautifulsoup来从HTML片段中删除标签
- 如何使用 base 标签使页面中的所有标签在新窗口中打开
- python使用正则表达式提取html标签
- Python中使用glob和rmtree删除目录子目录及所有文件的例子
- 使用某个文件夹下的所有文件去替换另一个文件夹下及其子文件夹下存在的同名文件(Python实现)
- 使用python过滤html标签
- 使用Python去除C/C++源程序中的所有注释和空行
- 使用python抓取有路网图书信息(原创)
- 使用python过滤html标签
- 如何使用dw的查找功能,删除所有的链接即标签?
- 如何使用jQuery去掉指定标签里所有文字内容对应的链接,即去掉<a>标签
- 【Flex】使用ASDocs文档查看Label标签的所有可用样式
- [python]使用xml.etree.ElementTree遍历xml所有节点
- Python中使用glob和rmtree删除目录子目录及所有文件的例子