centos6.5 搭建hadoop平台
2016-08-26 16:13
369 查看
1、下载hadoop-2.3.0-cdh5.0.0.tar.gz
地址:http://archive.cloudera.com/cdh5/cdh/5/
2、useradd hadoop
3、passwd hadoop
……
4、cp hadoop-2.3.0-cdh5.0.0.tar.gz /home/hadoop
5、su hadoop
6、各节点间建立ssh(可参考http://blog.csdn.net/qq_30831935/article/details/52311726)
7、解压并修改配置文件
tar -zxvf hadoop-2.3.0-cdh5.0.0.tar.gz
cd hadoop-2.3.0-cdh5.0.0/etc/hadoop
vim core-site.xml
vim slaves(节点的主机名)
vim hdfs-site.xml
vim mapred-site.xml(没有就 cp mapred-site.xml.template mapred-site.xml)
vim yarn-site.xml
8、配置环境变量(3台)
文件夹拷贝至节点上
scp -r hadoop-2.3.0-cdh5.0.0 hadoop@m2:~
scp -r hadoop-2.3.0-cdh5.0.0 hadoop@m3:~
9、hadoop namenode -format
10、start-all.sh
如果出现java_home not found
解决办法:vim hadoop-env.sh 将java路径写全
11、stop-all.sh
12、运行自带案例
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.3.0-cdh5.0.0.jar pi 2 2
第一个参数2指用2个map来计算
第二个参数2指每个map执行2次
设的越大,计算时间越长,结果也更精准
13、hdfs的操作
hadoop fs -ls / 查看hdfs里的文件夹
hadoop fs -put 文件 /文件夹
hadoop fs -mkdir /文件夹…
hadoop fs -text /文件 查看文件
14、浏览器打开8088端口

浏览器打开50070端口
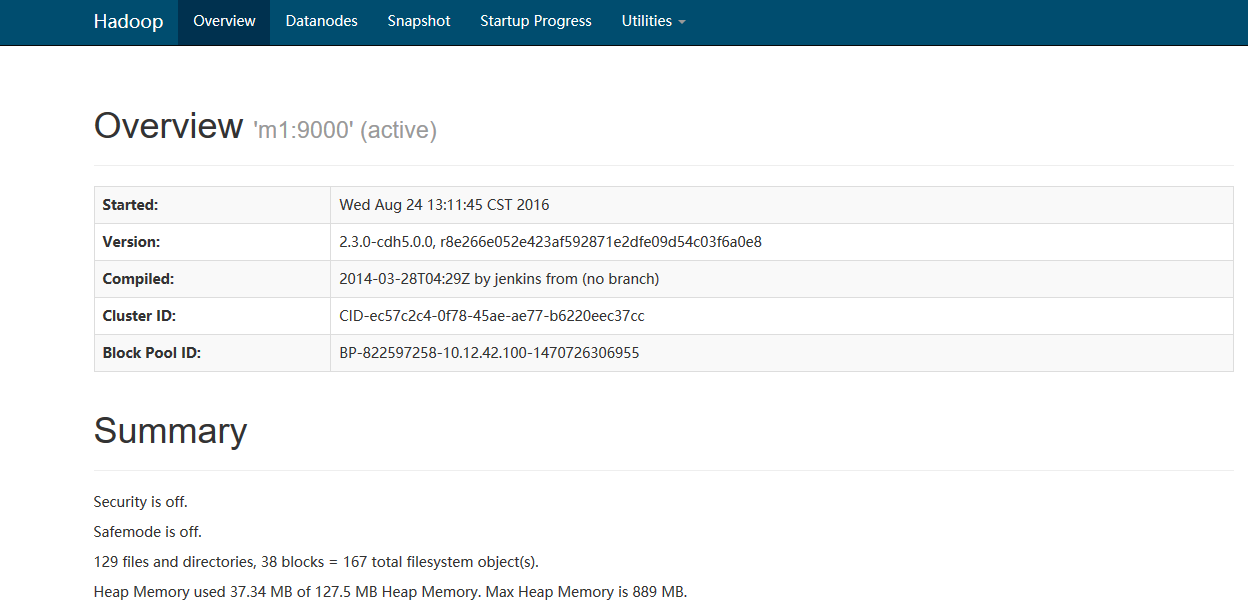
15、hadoop计算
hadoop jar **.jar 完整类名 文件地址 结果存到哪
地址:http://archive.cloudera.com/cdh5/cdh/5/
2、useradd hadoop
3、passwd hadoop
……
4、cp hadoop-2.3.0-cdh5.0.0.tar.gz /home/hadoop
5、su hadoop
6、各节点间建立ssh(可参考http://blog.csdn.net/qq_30831935/article/details/52311726)
7、解压并修改配置文件
tar -zxvf hadoop-2.3.0-cdh5.0.0.tar.gz
cd hadoop-2.3.0-cdh5.0.0/etc/hadoop
vim core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://m1:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/tmp</value> <description>Abasefor other temporary directories.</description> </property> <property> <name>hadoop.proxyuser.spark.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.spark.groups</name> <value>*</value> </property> </configuration>
vim slaves(节点的主机名)
m1 m2 m3
vim hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>m1:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/tmp/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
vim mapred-site.xml(没有就 cp mapred-site.xml.template mapred-site.xml)
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>m1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>m1:19888</value> </property> </configuration>
vim yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>m1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>m1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>m1:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>m1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>m1:8088</value> </property> </configuration>
8、配置环境变量(3台)
export HADOOP_HOME=/home/hadoop/hadoop-2.3.0-cdh5.0.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
文件夹拷贝至节点上
scp -r hadoop-2.3.0-cdh5.0.0 hadoop@m2:~
scp -r hadoop-2.3.0-cdh5.0.0 hadoop@m3:~
9、hadoop namenode -format
10、start-all.sh
如果出现java_home not found
解决办法:vim hadoop-env.sh 将java路径写全
Set Hadoop-specific environment variables here. # The only required environment variable is JAVA_HOME. All others are # optional. When running a distributed configuration it is best to # set JAVA_HOME in this file, so that it is correctly defined on # remote nodes. # The java implementation to use. export JAVA_HOME=/usr/java/jdk1.8.0_20
11、stop-all.sh
12、运行自带案例
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.3.0-cdh5.0.0.jar pi 2 2
第一个参数2指用2个map来计算
第二个参数2指每个map执行2次
设的越大,计算时间越长,结果也更精准
13、hdfs的操作
hadoop fs -ls / 查看hdfs里的文件夹
hadoop fs -put 文件 /文件夹
hadoop fs -mkdir /文件夹…
hadoop fs -text /文件 查看文件
14、浏览器打开8088端口
浏览器打开50070端口
15、hadoop计算
hadoop jar **.jar 完整类名 文件地址 结果存到哪

相关文章推荐
- 大数据之Hadoop平台(一)Centos6.5(64bit)编译Hadoop2.5.1源码
- Centos6.5基本环境以及jdk1.7安装配置(hadoop平台)
- CentOS 6.7平台Hadoop 1.2.1环境搭建
- Centos6.5使用ELK(Elasticsearch + Logstash + Kibana) 搭建日志集中分析平台实践
- centos6.5平台下Hadoop集群部署
- 总结之:CentOS 6.5 LAMP分主机平台的搭建及测试 推荐
- CentOS6.5上搭建hadoop 2.5.2 笔记
- CentOS 6.5 搭建Hadoop2.6完全分布式集群
- centos6.5监控平台nagios搭建与配置
- CentOS 6.5 hadoop 2.7.3 集群环境搭建
- 大数据之Hadoop平台(二)Centos6.5(64bit)Hadoop2.5.1伪分布式安装记录,wordcount运行测试
- Centos 6.5版本的Linux系统下关于hadoop2.4.1伪分布式的搭建
- 大数据之Hadoop平台(四)Centos6.5(64bit)Hadoop2.5.1、Zookeeper3.4.6、Hbase0.98.6.1安装使用过程中错误及解决方法
- CentOS6.5虚拟机下搭建Hadoop伪分布式环境
- hadoop前戏配置一:centos6.5平台JDK安装与配置
- Centos 6.5 搭建Openstack平台
- centos 6.5搭建hadoop2.2.0
- centos6.5 源代码方式搭建LNMP平台
- centos下搭建hadoop平台
- [整理]Centos6.5 + hadoop2.6.4环境搭建