Spark技术内幕:Executor分配详解
2016-08-25 18:32
531 查看
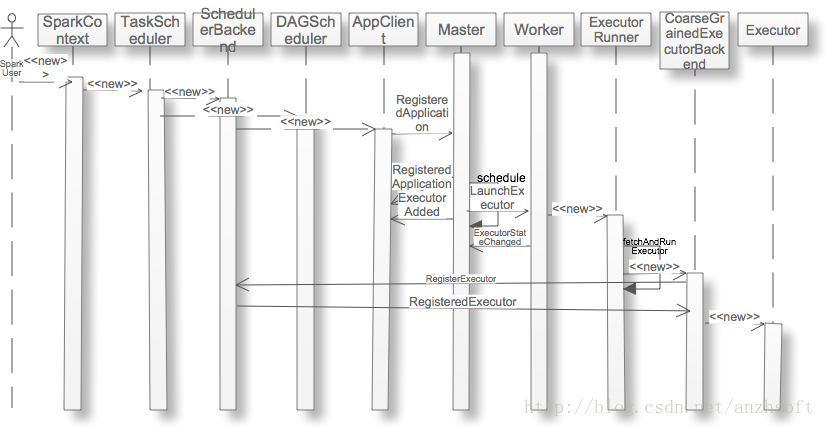
当用户应用new SparkContext后,集群就会为在Worker上分配executor,那么这个过程是什么呢?本文以Standalone的Cluster为例,详细的阐述这个过程。序列图如下:
SparkContext是用户应用和Spark集群的交换的主要接口,用户应用一般首先要创建它。如果你使用SparkShell,你不必自己显式去创建它,系统会自动创建一个名字为sc的SparkContext的实例。创建SparkContext的实例,主要的工作除了设置一些conf,比如executor使用到的memory的大小。如果系统的配置文件有,那么就读取该配置。否则则读取环境变量。如果都没有设置,那么取默认值为512M。当然了这个数值还是很保守的,特别是在内存已经那么昂贵的今天。
[java] view
plain copy
private[spark] val executorMemory = conf.getOption("spark.executor.memory")
.orElse(Option(System.getenv("SPARK_EXECUTOR_MEMORY")))
.orElse(Option(System.getenv("SPARK_MEM")).map(warnSparkMem))
.map(Utils.memoryStringToMb)
.getOrElse(512)
除了加载这些集群的参数,它完成了TaskScheduler和DAGScheduler的创建:
[java] view
plain copy
// Create and start t
4000
he scheduler
private[spark] var taskScheduler = SparkContext.createTaskScheduler(this, master)
private val heartbeatReceiver = env.actorSystem.actorOf(
Props(new HeartbeatReceiver(taskScheduler)), "HeartbeatReceiver")
@volatile private[spark] var dagScheduler: DAGScheduler = _
try {
dagScheduler = new DAGScheduler(this)
} catch {
case e: Exception => throw
new SparkException("DAGScheduler cannot be initialized due to %s".format(e.getMessage))
}
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
taskScheduler.start()
TaskScheduler是通过不同的SchedulerBackend来调度和管理任务。它包含资源分配和任务调度。它实现了FIFO调度和FAIR调度,基于此来决定不同jobs之间的调度顺序。并且管理任务,包括任务的提交和终止,为饥饿任务启动备份任务。
不同的Cluster,包括local模式,都是通过不同的SchedulerBackend的实现其不同的功能。这个模块的类图如下:

SparkDeploySchedulerBackend是Standalone模式的SchedulerBackend。通过创建AppClient,可以向Standalone的Master注册Application,然后Master会通过Application的信息为它分配Worker,包括每个worker上使用CPU core的数目等。
[java] view
plain copy
private[spark] class SparkDeploySchedulerBackend(
scheduler: TaskSchedulerImpl,
sc: SparkContext,
masters: Array[String])
extends CoarseGrainedSchedulerBackend(scheduler, sc.env.actorSystem)
with AppClientListener
with Logging {
15165
var client: AppClient = null <span style="font-family: Arial, Helvetica, sans-serif;">//注:Application与Master的接口</span>
val maxCores = conf.getOption("spark.cores.max").map(_.toInt) <span style="font-family: Arial, Helvetica, sans-serif;">//注:获得每个executor最多的CPU core数目</span>
override def start() {
super.start()
// The endpoint for executors to talk to us
val driverUrl = "akka.tcp://%s@%s:%s/user/%s".format(
SparkEnv.driverActorSystemName,
conf.get("spark.driver.host"),
conf.get("spark.driver.port"),
CoarseGrainedSchedulerBackend.ACTOR_NAME)
//注:现在executor还没有申请,因此关于executor的所有信息都是未知的。
//这些参数将会在org.apache.spark.deploy.worker.ExecutorRunner启动ExecutorBackend的时候替换这些参数
val args = Seq(driverUrl, "{{EXECUTOR_ID}}", "{{HOSTNAME}}", "{{CORES}}", "{{WORKER_URL}}")
//注:设置executor运行时需要的环境变量
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath").toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
val libraryPathEntries =
sc.conf.getOption("spark.executor.extraLibraryPath").toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
//注:在Worker上通过org.apache.spark.deploy.worker.ExecutorRunner启动
// org.apache.spark.executor.CoarseGrainedExecutorBackend,这里准备启动它需要的参数
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries, libraryPathEntries, javaOpts)
//注:org.apache.spark.deploy.ApplicationDescription包含了所有注册这个Application的所有信息。
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
sc.ui.appUIAddress, sc.eventLogger.map(_.logDir))
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
client.start()
//注:在Master返回注册Application成功的消息后,AppClient会回调本class的connected,完成了Application的注册。
waitForRegistration()
}
org.apache.spark.deploy.client.AppClientListener是一个trait,主要为了SchedulerBackend和AppClient之间的函数回调,在以下四种情况下,AppClient会回调相关函数以通知SchedulerBackend:
向Master成功注册Application,即成功链接到集群;
断开连接,如果当前SparkDeploySchedulerBackend::stop == false,那么可能原来的Master实效了,待新的Master ready后,会重新恢复原来的连接;
Application由于不可恢复的错误停止了,这个时候需要重新提交出错的TaskSet;
添加一个Executor,在这里的实现仅仅是打印了log,并没有额外的逻辑;
删除一个Executor,可能有两个原因,一个是Executor退出了,这里可以得到Executor的退出码,或者由于Worker的退出导致了运行其上的Executor退出,这两种情况需要不同的逻辑来处理。
[java] view
plain copy
private[spark] trait AppClientListener {
def connected(appId: String): Unit
/** Disconnection may be a temporary state, as we fail over to a new Master. */
def disconnected(): Unit
/** An application death is an unrecoverable failure condition. */
def dead(reason: String): Unit
def executorAdded(fullId: String, workerId: String, hostPort: String, cores: Int, memory: Int)
def executorRemoved(fullId: String, message: String, exitStatus: Option[Int]): Unit
}
小结:SparkDeploySchedulerBackend装备好启动Executor的必要参数后,创建AppClient,并通过一些回调函数来得到Executor和连接等信息;通过org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.DriverActor与ExecutorBackend来进行通信。
[java] view
plain copy
def tryRegisterAllMasters() {
for (masterUrl <- masterUrls) {
logInfo("Connecting to master " + masterUrl + "...")
val actor = context.actorSelection(Master.toAkkaUrl(masterUrl))
actor ! RegisterApplication(appDescription) // 向Master注册
}
}
def registerWithMaster() {
tryRegisterAllMasters()
import context.dispatcher
var retries = 0
registrationRetryTimer = Some { // 如果注册20s内未收到成功的消息,那么再次重复注册
context.system.scheduler.schedule(REGISTRATION_TIMEOUT, REGISTRATION_TIMEOUT) {
Utils.tryOrExit {
retries += 1
if (registered) { // 注册成功,那么取消所有的重试
registrationRetryTimer.foreach(_.cancel())
} else if (retries >= REGISTRATION_RETRIES) { // 重试超过指定次数(3次),则认为当前Cluster不可用,退出
markDead("All masters are unresponsive! Giving up.")
} else { // 进行新一轮的重试<span
style="margin: 0px; padding: 0px; border: non
1. SparkContext创建TaskScheduler和DAG Scheduler
SparkContext是用户应用和Spark集群的交换的主要接口,用户应用一般首先要创建它。如果你使用SparkShell,你不必自己显式去创建它,系统会自动创建一个名字为sc的SparkContext的实例。创建SparkContext的实例,主要的工作除了设置一些conf,比如executor使用到的memory的大小。如果系统的配置文件有,那么就读取该配置。否则则读取环境变量。如果都没有设置,那么取默认值为512M。当然了这个数值还是很保守的,特别是在内存已经那么昂贵的今天。[java] view
plain copy
private[spark] val executorMemory = conf.getOption("spark.executor.memory")
.orElse(Option(System.getenv("SPARK_EXECUTOR_MEMORY")))
.orElse(Option(System.getenv("SPARK_MEM")).map(warnSparkMem))
.map(Utils.memoryStringToMb)
.getOrElse(512)
除了加载这些集群的参数,它完成了TaskScheduler和DAGScheduler的创建:
[java] view
plain copy
// Create and start t
4000
he scheduler
private[spark] var taskScheduler = SparkContext.createTaskScheduler(this, master)
private val heartbeatReceiver = env.actorSystem.actorOf(
Props(new HeartbeatReceiver(taskScheduler)), "HeartbeatReceiver")
@volatile private[spark] var dagScheduler: DAGScheduler = _
try {
dagScheduler = new DAGScheduler(this)
} catch {
case e: Exception => throw
new SparkException("DAGScheduler cannot be initialized due to %s".format(e.getMessage))
}
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
taskScheduler.start()
TaskScheduler是通过不同的SchedulerBackend来调度和管理任务。它包含资源分配和任务调度。它实现了FIFO调度和FAIR调度,基于此来决定不同jobs之间的调度顺序。并且管理任务,包括任务的提交和终止,为饥饿任务启动备份任务。
不同的Cluster,包括local模式,都是通过不同的SchedulerBackend的实现其不同的功能。这个模块的类图如下:
2. TaskScheduler通过SchedulerBackend创建AppClient
SparkDeploySchedulerBackend是Standalone模式的SchedulerBackend。通过创建AppClient,可以向Standalone的Master注册Application,然后Master会通过Application的信息为它分配Worker,包括每个worker上使用CPU core的数目等。[java] view
plain copy
private[spark] class SparkDeploySchedulerBackend(
scheduler: TaskSchedulerImpl,
sc: SparkContext,
masters: Array[String])
extends CoarseGrainedSchedulerBackend(scheduler, sc.env.actorSystem)
with AppClientListener
with Logging {
15165
var client: AppClient = null <span style="font-family: Arial, Helvetica, sans-serif;">//注:Application与Master的接口</span>
val maxCores = conf.getOption("spark.cores.max").map(_.toInt) <span style="font-family: Arial, Helvetica, sans-serif;">//注:获得每个executor最多的CPU core数目</span>
override def start() {
super.start()
// The endpoint for executors to talk to us
val driverUrl = "akka.tcp://%s@%s:%s/user/%s".format(
SparkEnv.driverActorSystemName,
conf.get("spark.driver.host"),
conf.get("spark.driver.port"),
CoarseGrainedSchedulerBackend.ACTOR_NAME)
//注:现在executor还没有申请,因此关于executor的所有信息都是未知的。
//这些参数将会在org.apache.spark.deploy.worker.ExecutorRunner启动ExecutorBackend的时候替换这些参数
val args = Seq(driverUrl, "{{EXECUTOR_ID}}", "{{HOSTNAME}}", "{{CORES}}", "{{WORKER_URL}}")
//注:设置executor运行时需要的环境变量
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath").toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
val libraryPathEntries =
sc.conf.getOption("spark.executor.extraLibraryPath").toSeq.flatMap { cp =>
cp.split(java.io.File.pathSeparator)
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
//注:在Worker上通过org.apache.spark.deploy.worker.ExecutorRunner启动
// org.apache.spark.executor.CoarseGrainedExecutorBackend,这里准备启动它需要的参数
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries, libraryPathEntries, javaOpts)
//注:org.apache.spark.deploy.ApplicationDescription包含了所有注册这个Application的所有信息。
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
sc.ui.appUIAddress, sc.eventLogger.map(_.logDir))
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
client.start()
//注:在Master返回注册Application成功的消息后,AppClient会回调本class的connected,完成了Application的注册。
waitForRegistration()
}
org.apache.spark.deploy.client.AppClientListener是一个trait,主要为了SchedulerBackend和AppClient之间的函数回调,在以下四种情况下,AppClient会回调相关函数以通知SchedulerBackend:
向Master成功注册Application,即成功链接到集群;
断开连接,如果当前SparkDeploySchedulerBackend::stop == false,那么可能原来的Master实效了,待新的Master ready后,会重新恢复原来的连接;
Application由于不可恢复的错误停止了,这个时候需要重新提交出错的TaskSet;
添加一个Executor,在这里的实现仅仅是打印了log,并没有额外的逻辑;
删除一个Executor,可能有两个原因,一个是Executor退出了,这里可以得到Executor的退出码,或者由于Worker的退出导致了运行其上的Executor退出,这两种情况需要不同的逻辑来处理。
[java] view
plain copy
private[spark] trait AppClientListener {
def connected(appId: String): Unit
/** Disconnection may be a temporary state, as we fail over to a new Master. */
def disconnected(): Unit
/** An application death is an unrecoverable failure condition. */
def dead(reason: String): Unit
def executorAdded(fullId: String, workerId: String, hostPort: String, cores: Int, memory: Int)
def executorRemoved(fullId: String, message: String, exitStatus: Option[Int]): Unit
}
小结:SparkDeploySchedulerBackend装备好启动Executor的必要参数后,创建AppClient,并通过一些回调函数来得到Executor和连接等信息;通过org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.DriverActor与ExecutorBackend来进行通信。
3. AppClient向Master提交Application
AppClient是Application和Master交互的接口。它的包含一个类型为org.apache.spark.deploy.client.AppClient.ClientActor的成员变量actor。它负责了所有的与Master的交互。actor首先向Master注册Application。如果超过20s没有接收到注册成功的消息,那么会重新注册;如果重试超过3次仍未成功,那么本次提交就以失败结束了。[java] view
plain copy
def tryRegisterAllMasters() {
for (masterUrl <- masterUrls) {
logInfo("Connecting to master " + masterUrl + "...")
val actor = context.actorSelection(Master.toAkkaUrl(masterUrl))
actor ! RegisterApplication(appDescription) // 向Master注册
}
}
def registerWithMaster() {
tryRegisterAllMasters()
import context.dispatcher
var retries = 0
registrationRetryTimer = Some { // 如果注册20s内未收到成功的消息,那么再次重复注册
context.system.scheduler.schedule(REGISTRATION_TIMEOUT, REGISTRATION_TIMEOUT) {
Utils.tryOrExit {
retries += 1
if (registered) { // 注册成功,那么取消所有的重试
registrationRetryTimer.foreach(_.cancel())
} else if (retries >= REGISTRATION_RETRIES) { // 重试超过指定次数(3次),则认为当前Cluster不可用,退出
markDead("All masters are unresponsive! Giving up.")
} else { // 进行新一轮的重试<span
style="margin: 0px; padding: 0px; border: non

相关文章推荐
- Spark技术内幕:Executor分配详解
- Spark技术内幕:Executor分配详解
- Spark技术内幕: Task向Executor提交的源码解析
- 解析Spark Executor内幕,详解CoarseGrainedExecutorBackend
- Spark技术内幕: Shuffle详解(二)
- Spark技术内幕: Task向Executor提交的源代码解析
- Spark技术内幕: Task向Executor提交的源码解析
- Spark技术内幕: Shuffle详解(二)
- Spark技术内幕: Shuffle详解(三)
- Spark技术内幕: Task向Executor提交的源码解析
- Spark技术内幕:Shuffle Pluggable框架详解,你怎么开发自己的Shuffle Service?
- Spark技术内幕:Shuffle Pluggable框架详解,你怎么开发自己的Shuffle Service?
- Spark技术内幕: Shuffle详解(一)
- Spark技术内幕: Shuffle详解(三)
- Spark技术内幕: Shuffle详解(一)
- Spark技术内幕:Stage划分及提交源码分析
- Spark技术内幕:究竟什么是RDD
- Spark技术内幕:Client,Master和Worker 通信源码解析
- Spark技术内幕:究竟什么是RDD