Python实现抓取CSDN热门文章列表
2016-08-23 15:51
746 查看
1、使用工具:
Python3.5
BeautifulSoup
2、抓取网站:
csdn热门文章列表 http://blog.csdn.net/hot.html
3、分析网站代码:
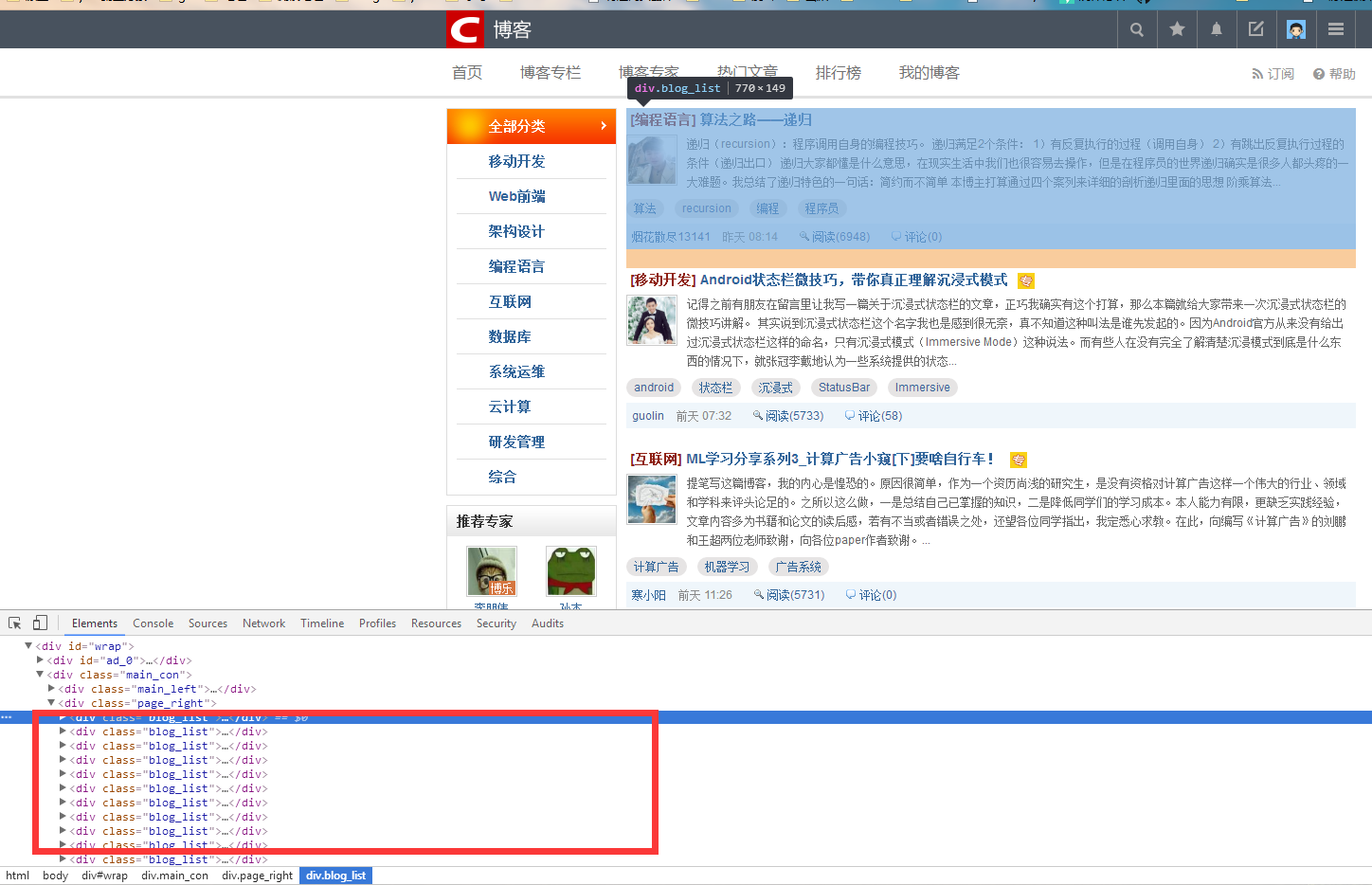
4、实现代码:
5、执行结果:

Python3.5
BeautifulSoup
2、抓取网站:
csdn热门文章列表 http://blog.csdn.net/hot.html
3、分析网站代码:
4、实现代码:
__author__ = 'Administrator'
import urllib.request
import re
from bs4 import BeautifulSoup
########################################################
#
# 抓取csdn首页文章http://blog.csdn.net/?&page=1
#
#
#
########################################################
class CsdnUtils(object):
def __init__(self):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
self.headers = {'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'User-Agent': user_agent,
}
def getPage(self, url=None):
request = urllib.request.Request(url, headers=self.headers)
response = urllib.request.urlopen(request)
soup = BeautifulSoup(response.read(), "html.parser")
#print(soup.prettify())
return soup
def parsePage(self, url=None, page=None):
soup = self.getPage(url)
itemBlog = soup.find_all('div', 'blog_list')
cnArticle = CsdnUtils
print("========================第", page, "页======================================")
for i, itemSingle in enumerate(itemBlog):
cnArticle.num = i
cnArticle.author = itemSingle.find('a', 'user_name').string
cnArticle.postTime = itemSingle.find('span', 'time').string
cnArticle.articleView = itemSingle.find('a', 'view').string
if itemSingle.find('h1').find('a').has_attr('class'):
cnArticle.type = itemSingle.find('h1').find('a', 'category').string
else:
cnArticle.type = "None"
cnArticle.title = itemSingle.find('h1').find('a', attrs={'name': True}).string
cnArticle.url = itemSingle.find('h1').find('a', attrs={'name': True}).get("href")
print("数据:", cnArticle.num + 1, '\t', cnArticle.author, '\t', cnArticle.postTime, '\t',
cnArticle.articleView, '\t', cnArticle.type, '\t', cnArticle.title, '\t', cnArticle.url)
####### 执行入口 ########
if __name__ == "__main__":
#要抓取的网页地址'http://blog.csdn.net/?&page={}'.format(i+1),i+1)
url = "http://blog.csdn.net/hot.html"
cnblog = CsdnUtils()
for i in range(0, 5):
cnblog.parsePage(url, i + 1)5、执行结果:

相关文章推荐
- Python实现抓取CSDN热门文章列表
- Python实现抓取CSDN博客首页文章列表
- Python实现抓取CSDN博客首页文章列表
- python实例-通过cookie实现登录csdn获取自己微博的文章列表
- 我的第一篇CSDN博客文章,Python代码实现矩阵翻转
- php实现的简单的csdn博客文章抓取(续:添加用户名搜索提示)
- 实现app上对csdn的文章列表上拉刷新下拉加载以及加入缓存文章列表的功能 (制作csdn app 四)
- CSDN博客专栏文章批量下载脚本[python实现]
- php实现的简单的csdn博客文章抓取
- python抓取csdn博客文章信息
- 一周stackoverflow热门问题选登:如何用Python for循环实现列表中数据两两循环打印?
- CSDN博客专栏文章批量下载脚本[python实现]
- 实现app上对csdn的文章列表上拉刷新下拉加载以及加入缓存文章列表的功能 (制作csdn app 四)
- 实现app上对csdn的文章列表上拉刷新下拉加载以及加入缓存文章列表的功能 (制作csdn app 四)
- Hello Python!用python写一个抓取CSDN博客文章的简单爬虫
- Python3.X登录模拟CSDN,获取文章列表
- python爬虫CSDN文章抓取
- 使用python抓取CSDN关注人的所有发布的文章
- 使用python抓取CSDN关注人的全部公布的文章
- 批量抓取csdn博客列表文章,简化后转为pdf保存