MySQL慢查询优化最佳实践(一)
2016-08-23 11:48
483 查看
慢查询我们知道,一般的应用系统,MySQL的读写比例在10:1左右,而且一般的插入和更新操作很少会出现性能问题,遇到问题最多的,也是最容易出现问题的,还是一些复杂的查询操作,所以查询语句的优化已经成为开发、运维工程师们的必须课,是大部分运维工作之中的重中之重。
索引原理数据库建立索引的目的是为了提高查询效率,索引如同生活中的字典、列车时刻表、图书目录一样,原理都相同,都是通过不断缩小想要获得的数据范围来筛选出最终想要的结果,把本来是随机查询的事件变成有序的事件,如我们在字典里查“mysql”单词,如果不建立索引,得从头翻到尾,想想是不是很恐怖!而我们会先选择查询m开头再查y字母范围内的单词,最后一个个定位到mysql。索引建立的深层原理涉及到磁盘的IO与预读、索引的数据结构b+树、b+树的性质和查找过程等等...
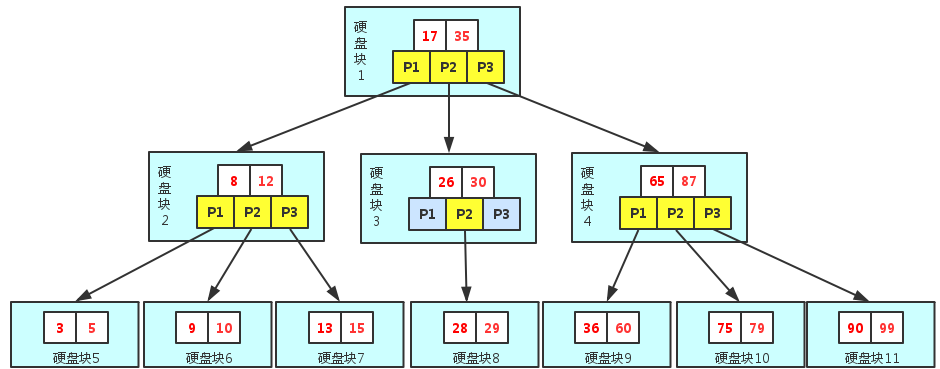
b+查询过程如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高 建立索引的几大原则1)最左前缀匹配原则:mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整;2)索引数量并不是越多越好,索引也要占用空间,且没增加数据都要维护索引,尽量扩展索引,不要新建索引;3)在唯一值多的大表上建立索引,唯一值的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,如select count(distinct user) from mysql.user; 慢查询相关设置1)定义慢查询时间
查询优化神器--explain
explain简单地说就是能够模拟查询过程,分析使用到的和可能使用到的索引列,及最终查询的rows数,通过降低核心指标rows数起到对mysql查询语句优化的结果,当然记得要SQL_NO_CACHE。1)我们模拟插入一组数据
查看一下联合索引效果
索引原理数据库建立索引的目的是为了提高查询效率,索引如同生活中的字典、列车时刻表、图书目录一样,原理都相同,都是通过不断缩小想要获得的数据范围来筛选出最终想要的结果,把本来是随机查询的事件变成有序的事件,如我们在字典里查“mysql”单词,如果不建立索引,得从头翻到尾,想想是不是很恐怖!而我们会先选择查询m开头再查y字母范围内的单词,最后一个个定位到mysql。索引建立的深层原理涉及到磁盘的IO与预读、索引的数据结构b+树、b+树的性质和查找过程等等...
b+查询过程如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高 建立索引的几大原则1)最左前缀匹配原则:mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整;2)索引数量并不是越多越好,索引也要占用空间,且没增加数据都要维护索引,尽量扩展索引,不要新建索引;3)在唯一值多的大表上建立索引,唯一值的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,如select count(distinct user) from mysql.user; 慢查询相关设置1)定义慢查询时间
mysql> set long_query_time=0.001 #一般看业务系统定义在1秒以上,这里我们方便测试,这是为0.001秒修改配置文件
[mysqld] long_query_time = 0.001 mysql> show variables like '%long_qu%'; +-----------------+----------+ | Variable_name | Value | +-----------------+----------+ | long_query_time | 0.001000 | +-----------------+----------+ 1 row in set (0.00 sec)2)开启慢查询日志
mysql> set GLOBAL slow_query_log=ON; #设置全局变量 mysql> show variables like '%slow%'; +---------------------+-------------------------------+ | Variable_name | Value | +---------------------+-------------------------------+ | log_slow_queries | ON | | slow_launch_time | 2 | | slow_query_log | ON | | slow_query_log_file | /data/3306/data/db02-slow.log | +---------------------+-------------------------------+ 4 rows in set (0.00 sec)
查询优化神器--explain
explain简单地说就是能够模拟查询过程,分析使用到的和可能使用到的索引列,及最终查询的rows数,通过降低核心指标rows数起到对mysql查询语句优化的结果,当然记得要SQL_NO_CACHE。1)我们模拟插入一组数据
mysql> CREATE DATABASE lichengbing; mysql> USE lichengbing; mysql> CREATE TABLE `user_name` ( `id` int(4) NOT NULL AUTO_INCREMENT, `name` char(20) NOT NULL, `age` tinyint(2) NOT NULL DEFAULT '0', `dept` varchar(16) DEFAULT NULL, PRIMARY KEY (`id`) #注意,我们只是创建了一个主键,没有创建任何索引列 ) ENGINE=InnoDB DEFAULT CHARSET=utf8用脚本批量插入数据
#!/bin/sh
for((i=1;i<=100000;i++))
do
dept=\'IT$i\'
age=`echo $RANDOM|cut -c 1-2`
mysql -S /data/3306/mysql.sock -e "insert into lichengbing.user_name(name,age,dept) values('Kobe',$age,$dept);"
done2)我们来看看在没有索引情况下查询速度和explain结果mysql> explain select * from lichengbing.user_name where name='kobe' and age < 20\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: user_name type: ALL possible_keys: NULL #显示没有使用到任何可能的索引 key: NULL key_len: NULL ref: NULL rows: 71761 #MySQL由于没有使用到索引,扫描了全部的71761条数据 Extra: Using where 1 row in set (0.00 sec)此时我们在慢查询日志里面就能查看到刚才执行的慢查询操作语句
[root@db02 data]# cat db02-slow.log /application/mysql-5.5.32/bin/mysqld, Version: 5.5.32-log (Source distribution). started with: Tcp port: 3306 Unix socket: /data/3306/mysql.sock Time Id Command Argument # Time: 160728 8:01:30 # User@Host: root[root] @ localhost [] # Query_time: 0.010430 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0 SET timestamp=1469664090; set GLOBAL slow_query_log=ON; # Time: 160728 8:31:02 # User@Host: root[root] @ localhost [] # Query_time: 0.009233 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0 SET timestamp=1469665862; select * from lichengbing.user_name where name='kobe' and age < 20;或者,在生产环境中,如果有大于1秒的慢查询导致应用程序响应缓慢,我们可以这样查看
[root@db02 ~]# mysql -S /data/3306/mysql.sock -e "show full processlist" +-------+------+-----------+------+---------+------+-------+-----------------------+ | Id | User | Host | db | Command | Time | State | Info | +-------+------+-----------+------+---------+------+-------+-----------------------+ | 68928 | root | localhost | NULL | Sleep | 185 | | NULL | | 69629 | root | localhost | NULL | Query | 0 | NULL | show full processlist | +-------+------+-----------+------+---------+------+-------+-----------------------+3)添加索引,优化查询我们先来看看给age添加索引效果
mysql> desc user_name; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int(4) | NO | PRI | NULL | auto_increment | | name | char(20) | NO | | NULL | | | age | tinyint(2) | NO | | 0 | | #此时没有任何索引 | dept | varchar(16) | YES | | NULL | | +-------+-------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) mysql> alter table user_name add index index_age(age); #以表age列创建索引 mysql> desc user_name; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int(4) | NO | PRI | NULL | auto_increment | | name | char(20) | NO | | NULL | | | age | tinyint(2) | NO | MUL | 0 | |#索引创建成功 | dept | varchar(16) | YES | | NULL | | +-------+-------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) mysql> explain select SQL_NO_CACHE * from lichengbing.user_name where age='20'\G; *************************** 1. row *************************** id: 1 #jSQL_NO_CACHE select_type: SIMPLE table: user_name type: ref possible_keys: index_age key: index_age key_len: 1 ref: const rows: 2417 #添加索引后只扫描了2417行,大大减少了查询时间 Extra: 1 row in set (0.00 sec)4)我们再来看看创建联合索引
mysql> alter table user_name drop index index_name; #删除掉之前创建的索引 mysql> alter table user_name drop index index_age; mysql> create index index_name_age on lichengbing.uer_name(name,age); #创建联合索引 mysql> desc lichengbing.user_name; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int(4) | NO | PRI | NULL | auto_increment | | name | char(20) | NO | MUL | NULL | | | age | tinyint(2) | NO | | 0 | | | dept | varchar(16) | YES | | NULL | | +-------+-------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) mysql> show index from lichengbing.user_name\G; *************************** 1. row *************************** Table: user_name Non_unique: 0 Key_name: PRIMARY #主键 Seq_in_index: 1 Column_name: id Collation: A Cardinality: 71761 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: *************************** 2. row *************************** Table: user_name Non_unique: 1 Key_name: index_name_age #索引age Seq_in_index: 1 Column_name: name Collation: A Cardinality: 199 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: *************************** 3. row *************************** Table: user_name Non_unique: 1 Key_name: index_name_age #索引name Seq_in_index: 2 Column_name: age Collation: A Cardinality: 199 Sub_part: NULL Packed: NULL Null: Index_type: BTREE Comment: Index_comment: 3 rows in set (0.00 sec)
查看一下联合索引效果
mysql> explain select SQL_NO_CACHE * from lichengbing.user_name where age='20' and name='Anthony'\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: user_name type: ref possible_keys: index_name_age key: index_name_age key_len: 61 ref: const,const rows: 87 #扫描了81条正确数据,done! Extra: Using where 1 row in set (0.00 sec)索引列的选择和生效条件1)并不是建立的索引越多越好,索引也要占用空间,且没增加数据都要维护索引2)索引尽量在唯一值多的大表上建立索引查看索引唯一值方法
mysql> select count(distinct id)from lichengbing.user_name; +--------------------+ | count(distinct id) | +--------------------+ | 71388 | #ID列我们不需要select +--------------------+ 1 row in set (0.08 sec) mysql> select count(distinct name)from lichengbing.user_name; +----------------------+ | count(distinct name) | +----------------------+ | 7 | +----------------------+ 1 row in set (0.00 sec) mysql> select count(distinct age)from lichengbing.user_name; +---------------------+ | count(distinct age) | +---------------------+ | 97 | #相比其他列,在age列创建索引较好 +---------------------+ 1 row in set (0.02 sec)

相关文章推荐
- mysql:21个性能优化最佳实践之1[为查询缓存优化你的查询]
- MySQL慢查询优化最佳实践(一)
- mysql:21个性能优化最佳实践之2[EXPLAIN 你的 SELECT 查询]
- MySQL大数据量查询优化最佳方案
- MySQL性能优化的21个最佳实践
- MySQL性能优化的21个最佳实践
- mysql:21个性能优化最佳实践之14[把IP地址存成UNSIGNED INT]
- mysql:21个性能优化最佳实践之4[为搜索字段建索引]
- mysql:21个性能优化最佳实践之6[不要使用ORDER BY RAND()]
- MySQL性能优化的21个最佳实践
- MySQL性能优化的21个最佳实践
- MySQL性能优化的21个最佳实践
- MySQL性能优化的21个最佳实践
- MySQL性能优化的21个最佳实践
- MySQL性能优化的21个最佳实践(转载)
- MySQL性能优化的21个最佳实践 和 mysql使用索引(转)
- MySQL性能优化的21个最佳实践 和 mysql使用索引(转)
- mysql:21个性能优化最佳实践之5[在Join表的时候使用相当类型的列,并将其索引]
- mysql:21个性能优化最佳实践之3[当只要一行数据时使用 LIMIT 1]
- MySQL性能优化的21个最佳实践