java jdk1.7版本的LinkedList底层原理解析
2016-08-22 17:06
435 查看
LinkedList集合与ArrayList集合的区别是底层的实现原理也不一样。LinkedList底层是通过一个双向链表实现(在jdk1.6及以前,是一个循环的双向链表),而ArrayList是通过数组实现的。这里暂且不讨论ArrayList的相关知识,先研究下LinkedList的实现原理,而且是以jdk1.7为基础的。在jdk1.6及之前的版本,LinkedList底层的实现是一个循环的双向链表,并且每个元素是Entry类,而在jdk1.7里每个元素是Node类,这些区别不详细讨论,只需要知道这里讨论的LinkedList是以jdk1.7为基础的。
根据源码里的注释,我们可以知道:
(1)、LinkedList可以进行所有List的操作,因为其实现了List接口,同时LinkedList可以存放任何元素,包括null;
(2)、所有根据索引的查找操作都是按照双向链表的需要执行的,根据索引从前或从后开始搜索,并且从最靠近索引的一端开始。例如一个LindedList有5个元素,如果调用了get(2)方法,LinkedList将会从头开始搜索;如果调用get(4)方法,那么LinkedList将会从后向前搜索。这样做的目的可以提升查找效率。那如何做到这一点呢?在LinkedList内部有一个Node(int index)方法,它会判断从头或者从后开始查找比较快。代码如下:

(3)、LinkedList不是线程安全的,所以在多线程的环境下使用LinedList需要注意LinkedList类型变量的线程同步问题。当然,有一种方式可以创建一个线程安全的LinkedList:
List list = Collections.synchronizedList(new LinkedList(…));
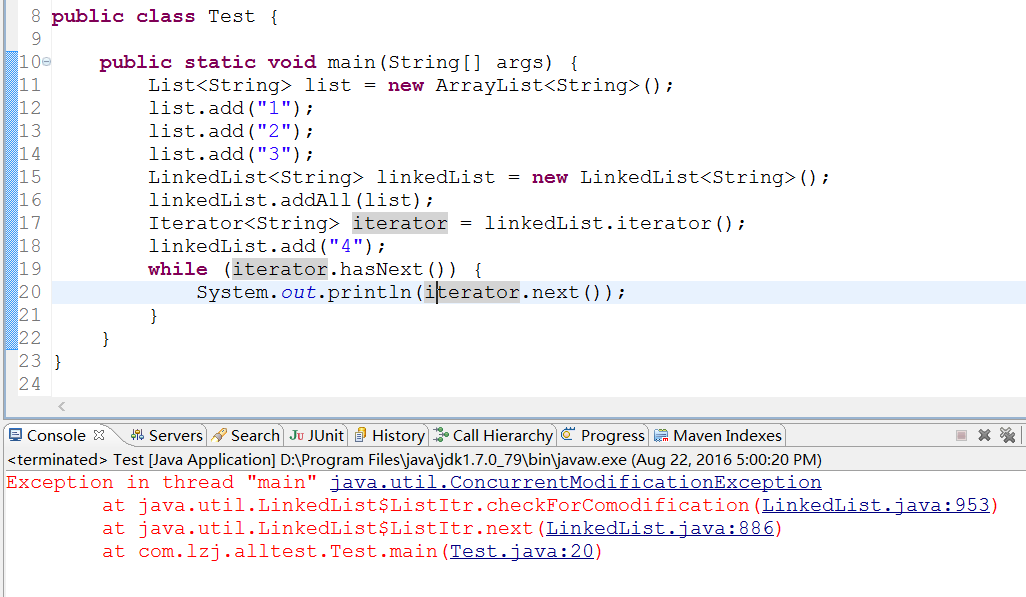
(4)、LinedList的迭代器 iterator 和 listIterator 方法返回的迭代器是快速失败 的。所谓快速失败,意思就是如果在迭代器已经创建了的情况下,任何时刻对LinkedList结构的修改,迭代器将会抛出一个ConcurrentModificationException异常。如下面代码中迭代器已经生成,但是还往LinedList添加数据,那么此后的迭代过程是会抛出ConcurrentModificationException异常的:
下面将研究LinkedList底层的实现原理并了解一些常用方法的实现过程:
在了解LinkedList的实现原理之前,我们首先需要明白LinkedList中的一个节点是什么以及它的具体数据结构。LinkedList每个节点是一个Node类型的实例,每个Node实例除了保存节点的真实值(即真实数据)外,还保存了这个节点的前一个节点的引用和后一个节点的引用,这样就实现了双线链表的数据结构。Node数据结构如下:

从代码中我们可以看到,当创建一个Node节点时,我们需要传入三个参数,第一个参数就是当前节点的前驱节点,第二个就是节点的真实数据,第三个就是节点的后继节点。
了解完一个元素的具体数据结构,那么下面我们看看常用方法的具体实现:
1、add(E e)方法:add(E e)方法实际上调用的是linkLast(E e)方法,意思是把方法加到链表的最后。下面看看linkLast(E e)方法的具体实现:

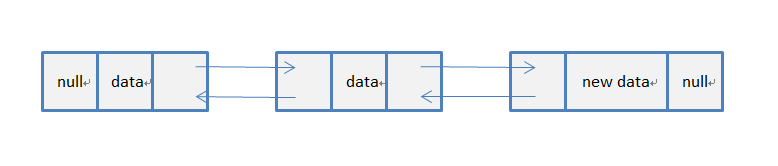
从代码中我们可以看到,代码中使用了变量first和last,这两个变量分别保存了当前链表第一个节点和最后一个节点的引用。在新增一个节点之前,首先把指向最后一个节点的引用(即变量 last)保存起来(即变量 l),然后新建一个节点,指定前驱节点是原来链表的最后一个节点,然后把指向最后一个节点的引用(last)指向新建的节点。紧接着就设置新建节点的前驱节点的后继节点指向新增的节点,最后把整个链表的总数加1,完成了新增一个节点的操作。完成新增后的链表结构类似如下:
2、add(int index, Ee)方法:add(int index, Ee)方法可以指定把某个数据插入指定的位置。我们首先看下源码:

从源码中我们可以看到,方法一开始调用了checkPositionIndex(index)方法,这个方法主要的作用是判断指定的index是否越界,如果越界就抛出IndexOutOfBoundsException异常,从方法的注释我们也能看出来。在LinkedList源码中,很多方法都会调用这个方法去判断指定的index是否越界,比如set(int index, E e)方法。如果指定的index是合法的,那么接下来就判断指定的index是否与LinkedList的size是否相等,如果相等,那么就直接把节点加到后面即可。如果不相等,则调用linkBefore(element, node(index))方法。这里我们可以看到,linkBefore方法的第二个参数是通过调用node(index)的返回值当作参数的,这个方法前面已经讲解过。通过node(index)方法获取指定索引的节点,其实这个方法返回的节点会当作新增节点的后继节点,通过查看linkBefore里的具体源码我们就知道原因:
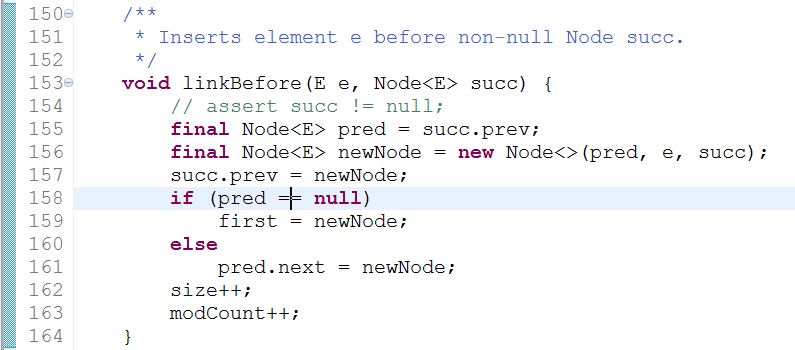
从linkBefore方法我们可以看到,在创建新节点时,同时指定了前驱节点和后继节点,这里后继节点就是我们传进来的第二个参数,所以验证了我们之前所说的第二个参数即为新增节点的后继节点的说法。在创建节点之前,我们把后继节点的前驱节点的引用先保存到一个pred变量中,然后创建一个新的节点,并指定前驱节点和后继节点;接着把后继节点的前驱节点引用指向了新的节点,这样新的节点就可以找到后继节点,接下来根据前驱节点如果为空,则更改first指向新建的节点,否则将前驱节点指向后继节点的引用指向新建的节点,最后把LinkedList的size加1。下面通过图感受一下linkBefore里具体的过程:
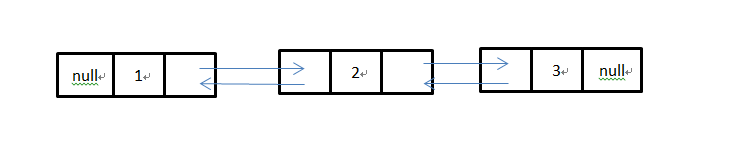
现在有一个有三个节点的LinkedList:
然后我调用add(1,”4”)方法,即新增的节点取代了二号位节点(数据为2)的那个节点的位置,后面的节点将往后移:
当执行了final Node pred = succ.prev; final Node newNode = new Node<>(pred, e, succ);这两句代码,LinkedList的结构变成这样:
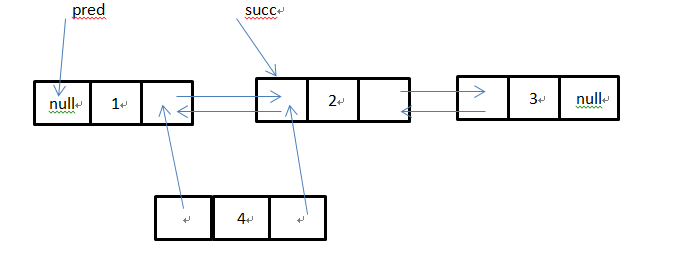
接着执行:succ.prev = newNode;即把三号位的节点指向前驱节点的引用指向新的节点:
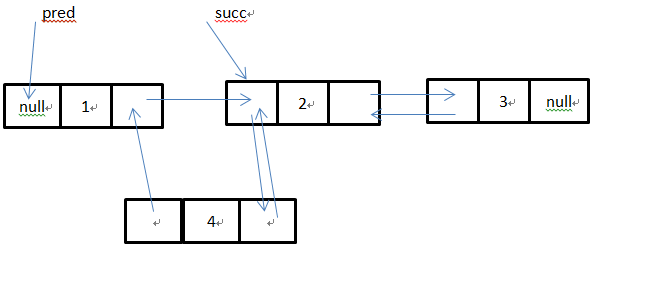
这里pred很明显不为空,所以会执行pred.next = newNode;这时候LinkedList结构:
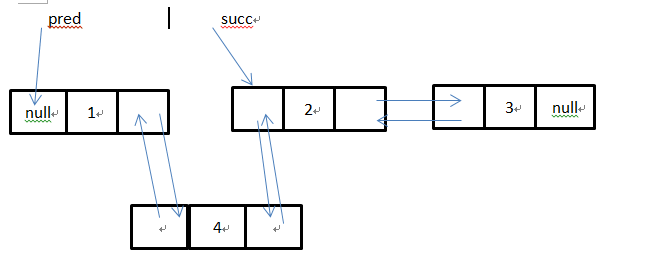
屏蔽掉pred和succ,我们将看得更直观:
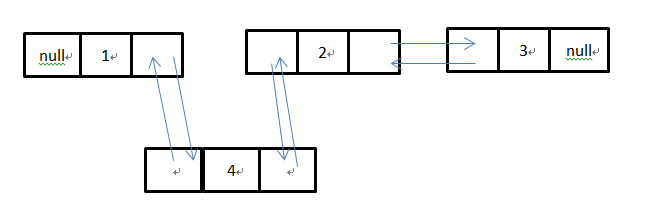
执行到这里,我们发现新增的节点已经正确的插入到了指定的位置,最后只需要把size加1即可。
通过以上两个方法,我们可以知道java中的LinkedList的底层实现原理,底层是用一个双向链表的数据结构来保存数据。链表中一个节点是一个Node类型的数据结构,其保存了一个指向前驱节点的引用、真实数据和一个指向后继节点的引用。对LinkedList的操作实际上是对指向前驱节点和后继节点的引用操作。因为LinkedList采用双线链表作为底层的数据结构,所以其插入和删除效率较高,但是随机访问效率较差,因为要遍历。
下面再看几个方法的实现源码:
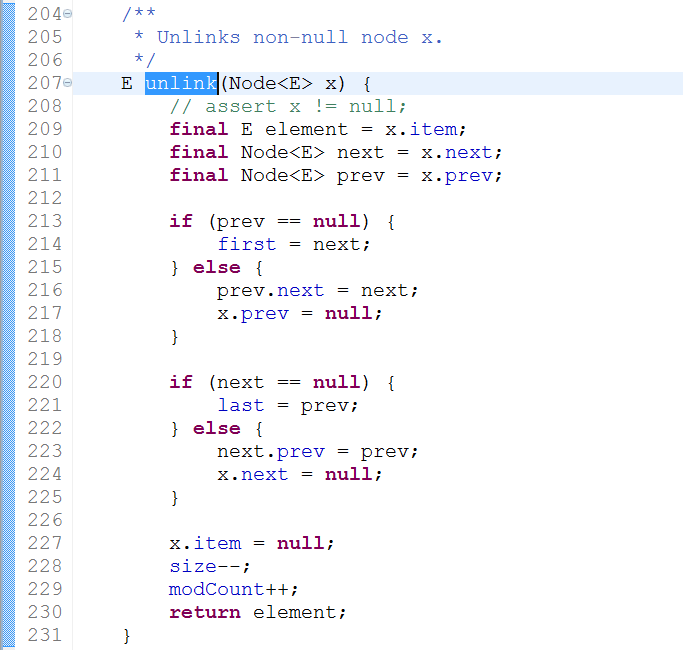
remove(int index):

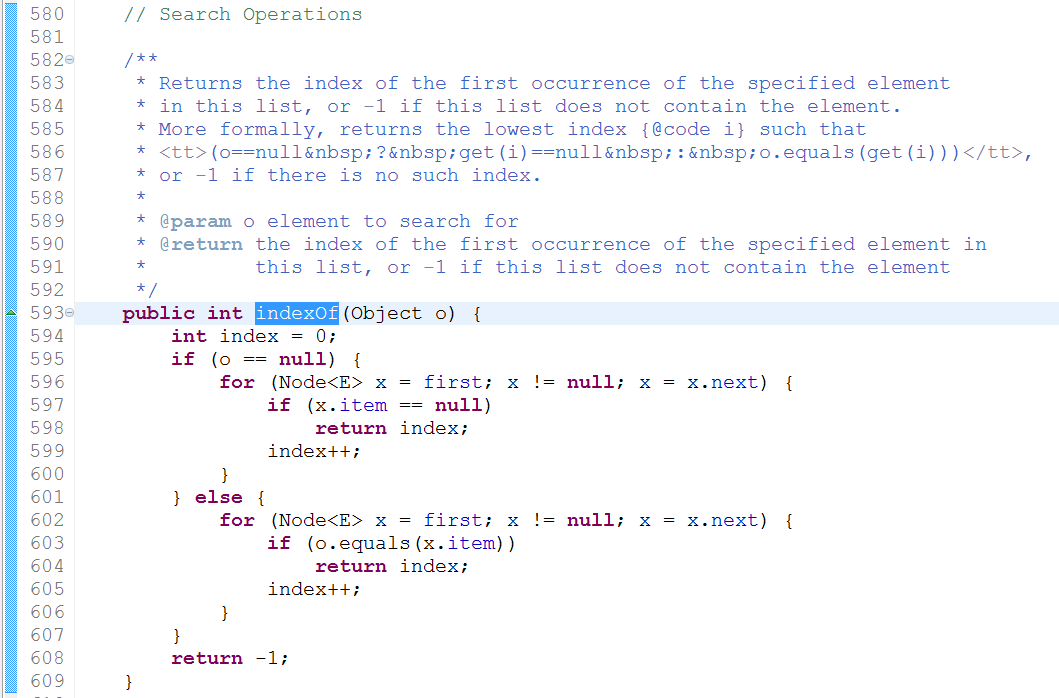
indexOf(Object o):
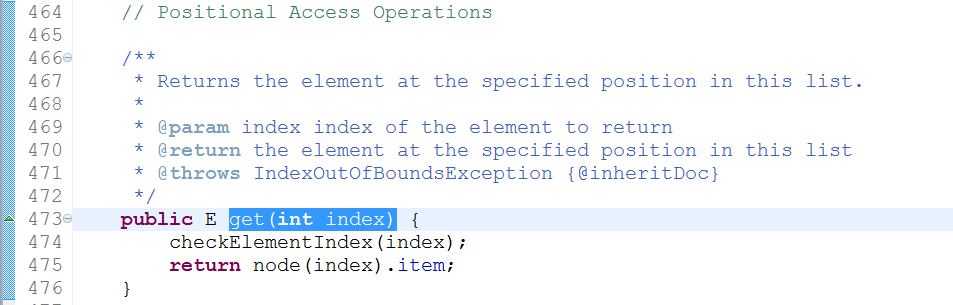
get(int index):
根据源码里的注释,我们可以知道:
(1)、LinkedList可以进行所有List的操作,因为其实现了List接口,同时LinkedList可以存放任何元素,包括null;
(2)、所有根据索引的查找操作都是按照双向链表的需要执行的,根据索引从前或从后开始搜索,并且从最靠近索引的一端开始。例如一个LindedList有5个元素,如果调用了get(2)方法,LinkedList将会从头开始搜索;如果调用get(4)方法,那么LinkedList将会从后向前搜索。这样做的目的可以提升查找效率。那如何做到这一点呢?在LinkedList内部有一个Node(int index)方法,它会判断从头或者从后开始查找比较快。代码如下:
(3)、LinkedList不是线程安全的,所以在多线程的环境下使用LinedList需要注意LinkedList类型变量的线程同步问题。当然,有一种方式可以创建一个线程安全的LinkedList:
List list = Collections.synchronizedList(new LinkedList(…));
(4)、LinedList的迭代器 iterator 和 listIterator 方法返回的迭代器是快速失败 的。所谓快速失败,意思就是如果在迭代器已经创建了的情况下,任何时刻对LinkedList结构的修改,迭代器将会抛出一个ConcurrentModificationException异常。如下面代码中迭代器已经生成,但是还往LinedList添加数据,那么此后的迭代过程是会抛出ConcurrentModificationException异常的:
下面将研究LinkedList底层的实现原理并了解一些常用方法的实现过程:
在了解LinkedList的实现原理之前,我们首先需要明白LinkedList中的一个节点是什么以及它的具体数据结构。LinkedList每个节点是一个Node类型的实例,每个Node实例除了保存节点的真实值(即真实数据)外,还保存了这个节点的前一个节点的引用和后一个节点的引用,这样就实现了双线链表的数据结构。Node数据结构如下:
从代码中我们可以看到,当创建一个Node节点时,我们需要传入三个参数,第一个参数就是当前节点的前驱节点,第二个就是节点的真实数据,第三个就是节点的后继节点。
了解完一个元素的具体数据结构,那么下面我们看看常用方法的具体实现:
1、add(E e)方法:add(E e)方法实际上调用的是linkLast(E e)方法,意思是把方法加到链表的最后。下面看看linkLast(E e)方法的具体实现:
从代码中我们可以看到,代码中使用了变量first和last,这两个变量分别保存了当前链表第一个节点和最后一个节点的引用。在新增一个节点之前,首先把指向最后一个节点的引用(即变量 last)保存起来(即变量 l),然后新建一个节点,指定前驱节点是原来链表的最后一个节点,然后把指向最后一个节点的引用(last)指向新建的节点。紧接着就设置新建节点的前驱节点的后继节点指向新增的节点,最后把整个链表的总数加1,完成了新增一个节点的操作。完成新增后的链表结构类似如下:
2、add(int index, Ee)方法:add(int index, Ee)方法可以指定把某个数据插入指定的位置。我们首先看下源码:
从源码中我们可以看到,方法一开始调用了checkPositionIndex(index)方法,这个方法主要的作用是判断指定的index是否越界,如果越界就抛出IndexOutOfBoundsException异常,从方法的注释我们也能看出来。在LinkedList源码中,很多方法都会调用这个方法去判断指定的index是否越界,比如set(int index, E e)方法。如果指定的index是合法的,那么接下来就判断指定的index是否与LinkedList的size是否相等,如果相等,那么就直接把节点加到后面即可。如果不相等,则调用linkBefore(element, node(index))方法。这里我们可以看到,linkBefore方法的第二个参数是通过调用node(index)的返回值当作参数的,这个方法前面已经讲解过。通过node(index)方法获取指定索引的节点,其实这个方法返回的节点会当作新增节点的后继节点,通过查看linkBefore里的具体源码我们就知道原因:
从linkBefore方法我们可以看到,在创建新节点时,同时指定了前驱节点和后继节点,这里后继节点就是我们传进来的第二个参数,所以验证了我们之前所说的第二个参数即为新增节点的后继节点的说法。在创建节点之前,我们把后继节点的前驱节点的引用先保存到一个pred变量中,然后创建一个新的节点,并指定前驱节点和后继节点;接着把后继节点的前驱节点引用指向了新的节点,这样新的节点就可以找到后继节点,接下来根据前驱节点如果为空,则更改first指向新建的节点,否则将前驱节点指向后继节点的引用指向新建的节点,最后把LinkedList的size加1。下面通过图感受一下linkBefore里具体的过程:
现在有一个有三个节点的LinkedList:
然后我调用add(1,”4”)方法,即新增的节点取代了二号位节点(数据为2)的那个节点的位置,后面的节点将往后移:
当执行了final Node pred = succ.prev; final Node newNode = new Node<>(pred, e, succ);这两句代码,LinkedList的结构变成这样:
接着执行:succ.prev = newNode;即把三号位的节点指向前驱节点的引用指向新的节点:
这里pred很明显不为空,所以会执行pred.next = newNode;这时候LinkedList结构:
屏蔽掉pred和succ,我们将看得更直观:
执行到这里,我们发现新增的节点已经正确的插入到了指定的位置,最后只需要把size加1即可。
通过以上两个方法,我们可以知道java中的LinkedList的底层实现原理,底层是用一个双向链表的数据结构来保存数据。链表中一个节点是一个Node类型的数据结构,其保存了一个指向前驱节点的引用、真实数据和一个指向后继节点的引用。对LinkedList的操作实际上是对指向前驱节点和后继节点的引用操作。因为LinkedList采用双线链表作为底层的数据结构,所以其插入和删除效率较高,但是随机访问效率较差,因为要遍历。
下面再看几个方法的实现源码:
remove(int index):
indexOf(Object o):
get(int index):

相关文章推荐
- java jdk1.7版本的ArrayList原理解析
- java jdk1.7版本的HashMap原理解析
- Java集合---LinkedList底层原理
- Java 集合 JDK1.7的LinkedList
- java源码解读之LinkedList------jdk 1.7
- Java中LinkedList原理代码解析
- Java集合,LinkedList底层实现和原理
- LinkedList源码解析(基于JDK1.7)
- Java中LinkedList原理解析
- Java集合框架--LinkedList源码解析(JDK1.7)
- java 中的JDK封装的数据结构和算法解析(集合类)----顺序表 List 之 ArrayList
- java LinkedList原码分析(基于JDK1.6)
- 修改maven项目jdk版本,并解决Dynamic Web Module 3.1 requires Java 1.7 or newer错误
- Eclipse移植项目时JDK版本不匹配Project facet Java version 1.7 is not supported
- JDK 1.7源码阅读笔记(三)集合类之LinkedList
- Java 集合系列05之 LinkedList详细介绍(源码解析)和使用示例
- java linkedlist 原理
- Java 集合系列05之 LinkedList详细介绍(源码解析)和使用示例
- (8) Java源码分析 ---- LinkedList (对应数据结构中线性表中的双向循环链表,JDK1.6)
- java JDK JRE 1.6,1.7,1.8各个版本版本下载链接