分布式文件系统FastDFS实践
2016-08-22 12:01
417 查看
写得太好,忍不住直接转载来自己记录,如果作者看到,还请作者见谅啊.
最近,需要为业务团队提供图片及文件存储服务,早前,接触过的一些存储方案大概有:利用Linux系统级别的NFS文件服务,即在NFS Server和NFS Client之间进行文件同步,但NFS不太容易实现集群,从而避免单点问题,而且维护起来也比较麻烦,需要同步在接收上传的机器上建立NFS Client;也有利用Nginx+Lua+ImageMagick的方案,但在文件备份等需要借助一些其他手段才能达到。当然也有一些专门的分布式文件系统,如HDFS,GlusterFS等,但主要是针对大文件存储。最近接触到一个轻量的分布式文件系统--FastDFS,是由国人开发,比较遗憾的是关于FastDFS的文档都比较零散,在这个站点上要稍微集中一些。本文将对FastDFS进行一番探究实践。FastDFS特性
FastDFS是一款类Google FS的开源分布式文件系统,它用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX系统。它只能通过专有API对文件进行存取访问,不支持POSIX接口方式,不能mount使用。准确地讲,Google FS以及FastDFS、MogileFS、HDFS、TFS等类Google FS都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。轻量级设计
FastDFS中只有两个角色:Tracker和Storage。Tracker作为中心结点,其主要作用是维护Storage信息,负载均衡和调度等。Tracker会在内存和临时文件中记录Storage分组和Storage的状态等信息,不记录文件索引信息,占用的内存量很少。而重要的文件索引信息将附属在Storage生成的文件ID中,这无疑去掉文件索引这一步,也提高了文件检索的性能。分组存储
FastDFS采用了分组存储方式来保存文件的多个备份。存储集群由一个或多个逻辑组构成,集群存储总容量为集群中所有组的存储容量(一个存储组的容量由该组中容量最小的Storage决定)之和。一个组由一台或多台Storage组成,同组内的多台Storage之间是互备关系,同组内的存储服务器上的文件是完全一致的。文件上传、下载、删除等操作可以在组内任意一台Storage上进行。节点对等
FastDFS集群中的Tracker也可以有多台,Tracker和Storage均不存在单点问题。Tracker之间是对等关系,存储组内的Storage之间也是对等关系。传统的Master-Slave架构中的Master是单点,写操作仅针对Master。如果Master失效,需要将Slave提升为Master,实现逻辑会比较复杂。和Master-Slave架构相比,对等结构中所有结点的地位是相同的,每个结点都是Master,不存在单点问题。FastDFS架构
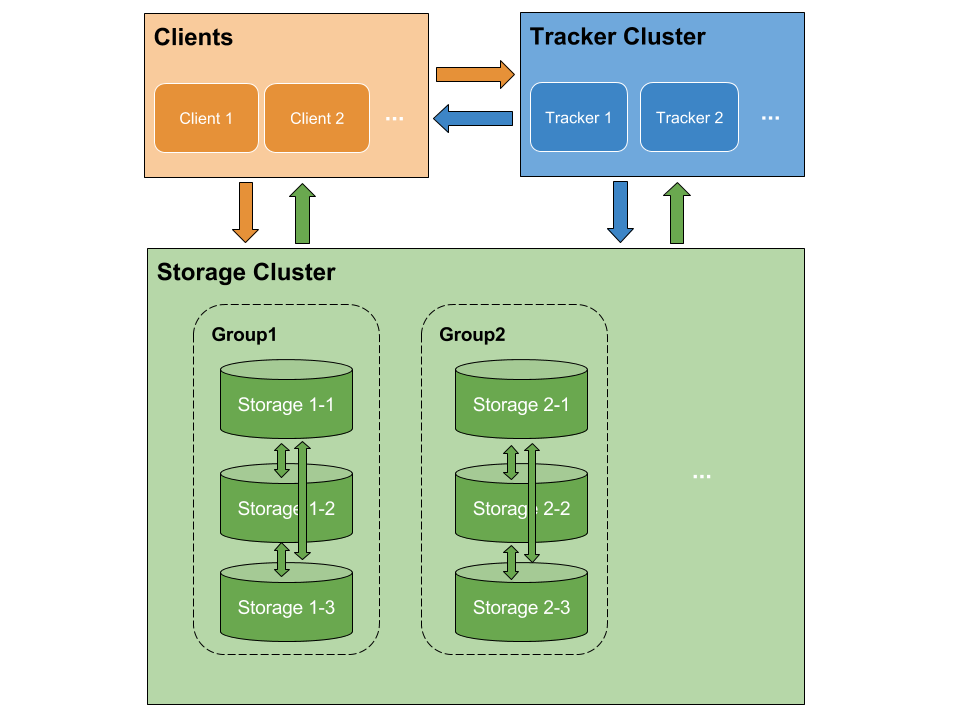
Client和Storage主动连接Tracker。Storage主动向Tracker报告其状态信息,包括磁盘剩余空间、文件同步状况、文件上传下载次数等统计信息。Storage会启动一个单独的线程来完成对一台Tracker的连接和定时报告。需要说明的是,一个组包含的Storage不是通过配置文件设定的,而是通过Tracker获取到的。文件操作。Storage采用binlog文件记录文件上传、删除等更新操作。binlog中只记录时间戳,操作类型,文件路径。文件同步。不同组的Storage相互独立,同组内的Storage之间会相互连接进行文件同步,采用push的方式。FastDFS 集群部署 & 配置 & 基本操作软硬件环境
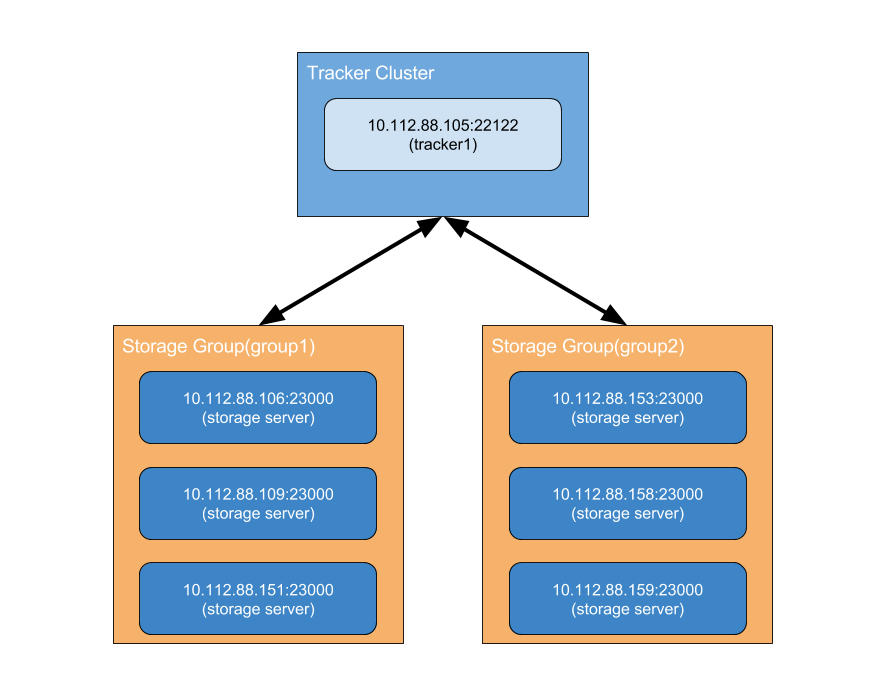
假设现在的开发环境如下:
Tracker安装
安装fastdfs公共库libfastcommon,需要注意fastdfs和fastcommon的安装目录,后面安装fastdfs-nginx-module时需要配置:
安装fastdfs:
配置Tracker(vim /etc/fdfs/tracker.conf):
启动Tracker:
自启动Tracker:
Storage安装
安装同Tracker。
配置Storage(vim /etc/fdfs/storage.conf):
启动Storage:
自启动Storage:
FastDFS基本操作集群监控
Tracker和Storage都启动好后,可以通过fdfs_monitor监控当前集群情况:
文件上传可通过fdfs_test进行测试:
文件下载也可通过fdfs_test进行测试:
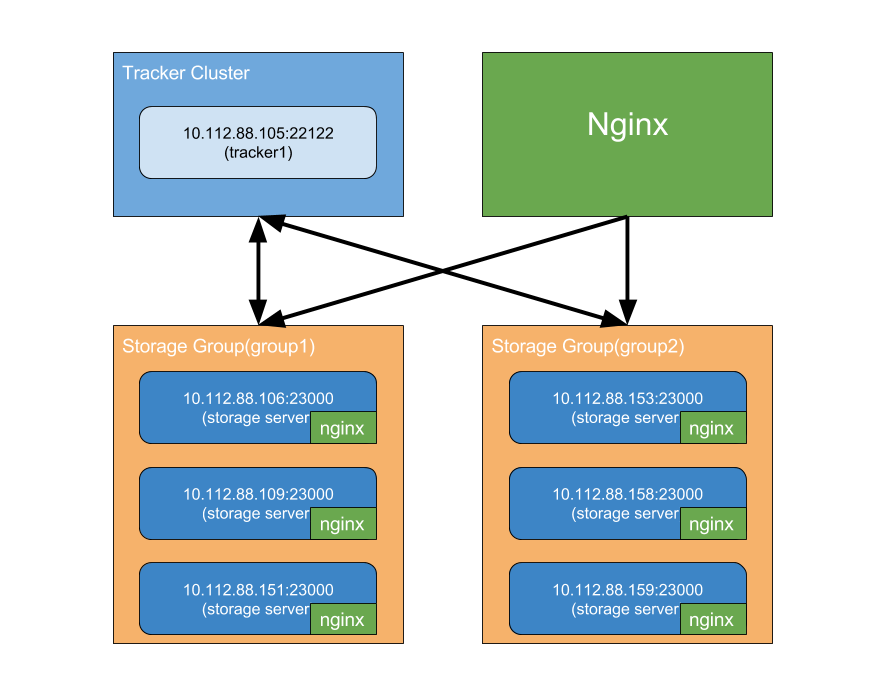
通常,对于图片和文件的访问,是不太可能走TCP,而是通过简单的HTTP访问,这时需要通过一些Web服务器(如nginx,apache)来代理,fastdfs也有了nginx的支持,下面则将通过安装nginx来完成文件访问,之前的开发环境将变为:
在Storage上配置fastdfs-nginx-module所需的配置文件:
FastDFS的一些运行机制Client与Tracker通讯
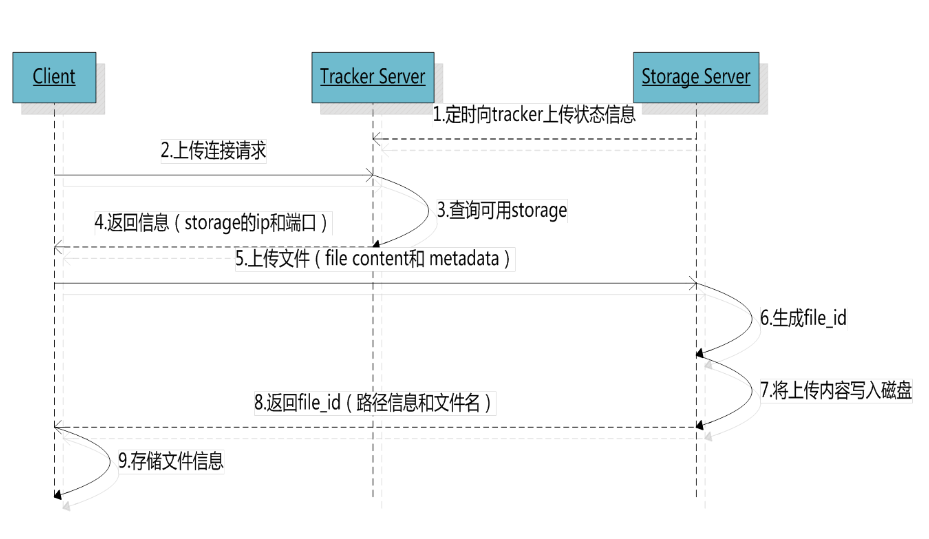
Client大部分的操作过程都是要先查询Tracker,Tracker返回目标Storage IP,然后Client再连接到该Storage,执行具体的操作。上传文件时,如何选择Storage Group,Storage及Storage Path:
Client下载时,需要传入对应的group,因此只需再选择其中一个Storage:
同组Storage之间的文件同步
FastDFS通过在同组内的多个Storage同步文件来保证系统的容错性(Fault Tolerance)。当Storage启动时,会为同组内的其他Storage分别开启一个线程,进行文件同步。文件同步主要通过binlog来实现,该文件被放置在/path/to/storage_data_path/sync下:
还有比较重要mark文件,该文件描述了当前Storage同步源操作到同组内其他Storage的进度:
当用户上传文件后,还未完全同步到同组内其他Storage时,那么用户下载文件时,如何避免文件同步延迟问题呢? 一个最简单的解决办法则是,优先选择源Storage下载文件即可,这可以在Tracker的配置文件中设置,对应的参数名为download_server。另外一种选择Storage的方法是轮询选择(round-robin),当Client询问Tracker时,有哪些Storage可以下载指定文件呢?Tracker将返回满足如下四个条件之一的Storage:1. 该Storage是该文件的源Storage,文件ID中可以解析出其源Storage IP;
2. 文件的创建时间戳 < Storage被同步到的文件时间戳,这意味着该文件已经同步了该Storage上。
3. 文件的创建时间戳 = Storage被同步到的文件时间戳,且(当前时间—文件创建时间戳) > 一个文件同步完成需要的最大时间(可配置storage_sync_file_max_time,如5分钟);
4. (当前时间 — 文件创建时间戳) > 文件同步延迟阈值(可配置storage_sync_file_max_delay,比如把阈值设置为1天,表示文件同步在1天内肯定可以完成)。
那么Tracker如何知道各组内Storage之间的同步进度呢,Storage会为每个Tracker分别开启一个线程,将同步信息报道给Tracker,其中当前Storage被同步的最近时间戳为同组内其他Storage同步的最小时间戳,如一组内有Storage-A、Storage-B、Storage-C三台机器,B最后同步给A的Binlog-timestamp为100,C最后同步给A的Binlog-timestamp为200,那么A机器的被同步最小时间戳就为100。Tracker会将该信息记录到storage_sync_timestamp.dat文件中:
增加Storage Group将直接对集群进行容量扩展。这也是后期维护比较常见的操作,新组添加进来后,若配置了store_lookup=2时,新加入的组将在一段时间内成为文件上传的单点,有可能对性能有所下降,比较建议在新加组时,能添加1个以上的组。增加Storage
在同组内添加Storage后,将会开启一个叫源同步的过程,也就是从组内现有的一台机器(这台机器称为源机器)上同步历史数据到新机器的过程。源机器选择:
当Storage是首次加入组时,会向Tracker集群中的一个发送TRACKER_PROTO_CMD_STORAGE_SYNC_DEST_REQ(87)命令,向Tracker查询,由同组内哪一台Storage作为源机器。当Tracker收到该请求后,根据当前组内的机器状态,若组内没有机器,则告诉新机器不需要进行源同步;若组内有机器但是没有状态为ACTIVE的机器,那么返回一个错误,新机器将睡眠后重试;若组内有机器并且有状态为ACTIVE的机器,那么选择一台作为其源,返回两个值:当前时间作为源同步截止时间与源机器IP,新机器将该信息记录在本地(/mnt/fastdfs/data/.data_init_flag),同时将自己状态设置成WAIT_SYNC:
对于源机器,如10.112.88.106,通过与Tracker通讯,得知有新机器加入,如10.112.88.109,于是启动一个线程与10.112.88.109进行通讯;再通过Tracker查询10.112.88.109的源机器IP和源同步截止时间,发现自己是其源机器,并在本地创建10.112.88.109_23000.mark,并写入need_sync_old=1; sync_old_done=0; util_timestamp = 查询到的源同步截止时间;接着请求Tracker将10.112.88.109的状态设置成SYNING,然后开始读取binlog中的源操作同步给10.112.88.109,直到在某一个时刻,取不到更多的binlog时,请求Tracker将10.112.88.109状态设置成OFFLINE,此时源同步完成;在下一个心跳中,Tracker会将10.112.88.109状态设置成ACTIVE。对于非源机器,如10.112.88.151,也会在本地创建10.112.88.109_23000.mark,并写入need_sync_old=0; sync_old_done=0; util_timestamp = 0;此时,并不会对10.112.88.109进行同步操作,而会等等待10.112.88.109状态为ACTIVE后,才开始同步操作。Tracker-Leader Server
在FastDFS之中,可以配置多个Tracker,在运行过程中会选择其中一个作为Leader,由该Leader执行一些选举操作。在早期版本中Tracker-Leader有两个作用,分别是:为新加入的Storage分配一个源Storage;为开启合并存储的Group选择Trunk-Server。但是在最新的版本中实际上只有第二个作用,也就是选择Trunk-Server。对于新加入Storage分配源Storage其实是任何一个Tracker都可以进行的,为了避免多次分配,在Storage请求Tracker分配源时进行了互斥量同步。Tracker-Leader选择过程
1. 向所有的Tracker(包括自己)发送一个TRACKER_GET_STATUS命令,来获取对方的状态信息,该信息包括:是否为Leader,到目前的运行时间和上次停止时间间隔(也就是最后一次停止到启动的时间间隔),只要获取到至少一个该状态成功,则继续下一步;
2. 对所有返回成功的Tracker-Status进行排序,获得状态值最高的Tracker;
3. 若状态最高的Tracker是自己,那么进入一个两阶段提交协议: 通知除自己之外的所有Tracker,将要变更Tracker-Leader,只要有一个Tracker通知成功,则进入下一步; 通知所有的Tracker(包括自己),将Leader变更成自己,只要有一个Tracker返回成功,则表示整个变更成功(此处通知了自己,那么这个步骤肯定会成功)。
4. 若最高状态的Tracker当前就是Leader,那么就设置本地标志为g_tracker_servers.leader_index为该Tracker。
否则,等待真正的Tracker Leader发起Leader变更消息;
文件合并存储
大多数文件系统,对于海量小文件的存储时,都会面临LOSF问题,比较通用的解决方案则是文件合并,FastDFS也提供了该功能,需要对Tracker作相关配置:
一个Trunk文件默认大小为64MB,因此创建Trunk文件时,很可能会产生空余空间,比如为存储一个10MB文件,创建一个Trunk文件,那么就会剩下接近54MB的空间(忽略其真实文件的一些头信息),下次若再次存储10MB文件时,就不需要创建新的Trunk文件文件,而是存储在现有的Trunk文件。此外当删除一个文件时,也会产生空余空间。在Storage内部会为每个store_path维护一颗以空闲块大小作为关键字的平衡树,相同大小的空闲块保存在链表之中。每当需要存储一个文件时会首先到平衡树中查找一块最相近的空闲内存快,若该内存快有余,则被加入到平衡树中;若此时找不到一块能容纳新文件的空闲内存,则会创建一个新的trunk文件。由Trunk Server分配空闲内存
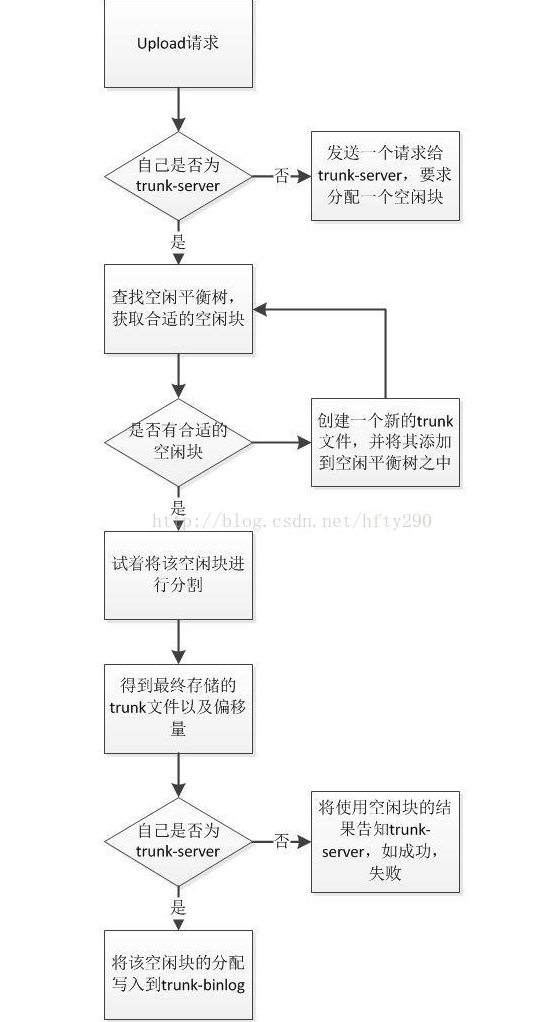
若同组内Storage均能为新上传的文件分配空闲内存,则有可能由于该组Storage文件同步延迟问题,导致数据存储冲突,如文件a上传时,由Storage A将其分配到000001这个trunk文件的起始位置,若还未来得及同步到同组的Storage B,此时文件b上传,由Storage B也将其分配到000001这个trunk文件的起始位置,这时就发生了存储冲突,这其实只要能保证Storage A和Storage B共享同一份空闲内存平衡树数据是可以解决的,但一旦涉及到网络,则有可能发生延迟,因此需要一个专门用于分配空闲内存的角色,即Trunk Server。下图则是空闲内存分配过程:
Trunk文件同步
相对于非trunk文件,trunk文件的同步也是通过binlog文件(TrunkBinlog文件)的方式进行,格式如下:
之前提到过,Trunk Server是由Tracker Leader进行选举,大致过程如下:1. 依次向组内当前状态为ACTIVE的Storage发送TRUNK_GET_BINLOG_SIZE命令,来查询每个Storage当前保存的Trunk-Binlog的文件大小,来找到Trunk-Binlog文件最大的Storage;
2. 若该Group的最后一个Trunk Server与要设置的新的Trunk Server并非同一个,则像该新的Trunk Server发送TRUNK_DELETE_BINLOG_MARKS命令,让其删除从trunk-binlog同步给组内其他Storage的mark文件。(既然这个Trunk Server是新的,那么就要清除trunk-binlog的同步状态,使其从头同步trunk-binlog给组内的其他Storage);
3. 变更该组的Trunk Server,并将修改写入到storage_groups_new.dat文件之中,更新该组的最后Trunk Server设置,设置Trunk Server已经变更标志,该标志使得在与Storage的心跳中通知对方Trunk Server已经变更。
总结
以上,则是关于FastDFS的一些实践,对于一些图片,文件的存储,也算是一种比较轻量的解决方案。转载自: https://t.hao0.me/storage/2016/05/10/fastdfs-practice.html
最近,需要为业务团队提供图片及文件存储服务,早前,接触过的一些存储方案大概有:利用Linux系统级别的NFS文件服务,即在NFS Server和NFS Client之间进行文件同步,但NFS不太容易实现集群,从而避免单点问题,而且维护起来也比较麻烦,需要同步在接收上传的机器上建立NFS Client;也有利用Nginx+Lua+ImageMagick的方案,但在文件备份等需要借助一些其他手段才能达到。当然也有一些专门的分布式文件系统,如HDFS,GlusterFS等,但主要是针对大文件存储。最近接触到一个轻量的分布式文件系统--FastDFS,是由国人开发,比较遗憾的是关于FastDFS的文档都比较零散,在这个站点上要稍微集中一些。本文将对FastDFS进行一番探究实践。FastDFS特性
FastDFS是一款类Google FS的开源分布式文件系统,它用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX系统。它只能通过专有API对文件进行存取访问,不支持POSIX接口方式,不能mount使用。准确地讲,Google FS以及FastDFS、MogileFS、HDFS、TFS等类Google FS都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。轻量级设计
FastDFS中只有两个角色:Tracker和Storage。Tracker作为中心结点,其主要作用是维护Storage信息,负载均衡和调度等。Tracker会在内存和临时文件中记录Storage分组和Storage的状态等信息,不记录文件索引信息,占用的内存量很少。而重要的文件索引信息将附属在Storage生成的文件ID中,这无疑去掉文件索引这一步,也提高了文件检索的性能。分组存储
FastDFS采用了分组存储方式来保存文件的多个备份。存储集群由一个或多个逻辑组构成,集群存储总容量为集群中所有组的存储容量(一个存储组的容量由该组中容量最小的Storage决定)之和。一个组由一台或多台Storage组成,同组内的多台Storage之间是互备关系,同组内的存储服务器上的文件是完全一致的。文件上传、下载、删除等操作可以在组内任意一台Storage上进行。节点对等
FastDFS集群中的Tracker也可以有多台,Tracker和Storage均不存在单点问题。Tracker之间是对等关系,存储组内的Storage之间也是对等关系。传统的Master-Slave架构中的Master是单点,写操作仅针对Master。如果Master失效,需要将Slave提升为Master,实现逻辑会比较复杂。和Master-Slave架构相比,对等结构中所有结点的地位是相同的,每个结点都是Master,不存在单点问题。FastDFS架构
Client和Storage主动连接Tracker。Storage主动向Tracker报告其状态信息,包括磁盘剩余空间、文件同步状况、文件上传下载次数等统计信息。Storage会启动一个单独的线程来完成对一台Tracker的连接和定时报告。需要说明的是,一个组包含的Storage不是通过配置文件设定的,而是通过Tracker获取到的。文件操作。Storage采用binlog文件记录文件上传、删除等更新操作。binlog中只记录时间戳,操作类型,文件路径。文件同步。不同组的Storage相互独立,同组内的Storage之间会相互连接进行文件同步,采用push的方式。FastDFS 集群部署 & 配置 & 基本操作软硬件环境
| 操作系统 | Centos6.7 Final |
| FastDFS版本 | fastdfs-5.05.tar.gz |
| libfastcommon | https://github.com/happyfish100/libfastcommon |
| nginx | nginx-1.9.9.tar.gz |
| fastdfs-nginx-module | fastdfs-nginx-module_1.16 |
Tracker安装
安装fastdfs公共库libfastcommon,需要注意fastdfs和fastcommon的安装目录,后面安装fastdfs-nginx-module时需要配置:
git clone git@github.com:happyfish100/libfastcommon.git cd libfastcommon ./make.sh ./make.sh install
安装fastdfs:
tar -zxf fastdfs-5.05.tar.gz cd fastdfs-5.05 ./make.sh ./make.sh install
配置Tracker(vim /etc/fdfs/tracker.conf):
# 是否禁用该配置文件 # false:开启 # true:禁用 disabled=false # 绑定地址 # 空字符表示绑定所有地址 bind_addr= # 端口设置 port=22122 # 连接超时设置 connect_timeout=30 # 网络超时设置 network_timeout=30 # 存储数据和日志的目录 base_path=/mnt/fastdfs # 最大并发连接数 max_connections=256 # 接受请求的线程数 accept_threads=1 # 执行请求的线程数 <= max_connections work_threads=4 # 如何选择上传文件的存储group # 0: 轮询 # 1: 制定group名称 # 2: 负载均衡, 选择空闲空间最大的存储group store_lookup=2 # 选择哪一个存储group,当store_lookup=1时,须指定存储group的名称 store_group=group2 # 如何选择上传文件的存储server # 0: 轮询 # 1: 以ip地址排序的第一个地址 # 2: 以优先级排序 store_server=0 # 选择存储server的哪一个路径(磁盘或挂载点)上传文件 # 0: 轮询 # 2: 负载均衡, 选择空闲空间最大的路径来存储文件 store_path=0 # 选择哪一个存储server下载文件 # 0: 轮询 # 1: 选择该文件上传时的那个存储server download_server=0 # 预留的存储空间 G(GB) M(MB) K(KB) 默认byte(B),% 表示比例,如下,预留的存储空间为10%,即只占用90% reserved_storage_space = 10% # log级别:alert error notice info debug log_level=info # 运行用户组,默认当前用户组 run_by_group= # 运行用户,默认当前用户 run_by_user= # 允许的host,例子如下 # "*" 表示所有 # 10.0.1.[1-15,20] # host[01-08,20-25].domain.com: # allow_hosts=10.0.1.[1-15,20] # allow_hosts=host[01-08,20-25].domain.com allow_hosts=* # 同步内存日志到磁盘的间隔时间,默认10s sync_log_buff_interval = 10 # 检查存储server存活的间隔时间,默认120s check_active_interval = 120 # 线程栈大小 >= 64KB thread_stack_size = 64KB # 当存储server变化时,是否自动调整存储server的ip storage_ip_changed_auto_adjust = true # 存储server同步文件的最大延时,默认86400s(1天) storage_sync_file_max_delay = 86400 # 存储server同步一个文件的最大时间 storage_sync_file_max_time = 300 # 是否用一个主文件存储多个小文件 use_trunk_file = false # 最小的slot大小(多个小文件之间的空隙大小),小于4k slot_min_size = 256 # 最大的slot大小(多个小文件之间的空隙大小) > slot_min_size # 当上传的文件大小 < slot_max_size时,那么该文件将合并到一个主文件 slot_max_size = 16MB # 主文件大小 >= 4MB trunk_file_size = 64MB # 是否提前创建trunk文件 trunk_create_file_advance = false # 创建trunk文件的基准时间 trunk_create_file_time_base = 02:00 # 创建trunk文件的间隔时间,默认86400s(1天) trunk_create_file_interval = 86400 # 创建trunk文件的阈值空间 trunk_create_file_space_threshold = 20G # 当加载trunk空间空间时,是否检查trunk空间占用情况,设置为true,启动会变慢 trunk_init_check_occupying = false # 是否忽略storage_trunk.dat trunk_init_reload_from_binlog = false # 压缩trunk binlog文件的间隔时间 # 0表示不压缩 trunk_compress_binlog_min_interval = 0 # 是否使用storage ID,而不是ip地址 use_storage_id = false # 定义storage ids文件,相对或绝对路径 storage_ids_filename = storage_ids.conf # 存储id类型,当use_storage_id=true时有效 ## ip: 存储server的IP ## id: 存储server的ID id_type_in_filename = ip # 是否使用链接文件存储slave文件 store_slave_file_use_link = false # 是否滚动错误日志文件 rotate_error_log = false # 滚动错误日志文件的时间点 error_log_rotate_time=00:00 # 当错误日志文件超出该值时,滚动错误日志文件 rotate_error_log_size = 0 # 保存日志文件的天数 # 0表示不删除日志文件 log_file_keep_days = 0 # 是否使用连接池 use_connection_pool = false # 连接最大空闲时间 connection_pool_max_idle_time = 3600 # tracker的http端口 http.server_port=8080 # 检查http server存活的时间间隔 http.check_alive_interval=30 # 检查http sever存活的类型 # tcp : 仅连接http端口,不发请求 # http: 发http请求,并需返回200 # default value is tcp http.check_alive_type=tcp # 检查http server的uri http.check_alive_uri=/status.html
启动Tracker:
/usr/bin/fdfs_trackerd /etc/fdfs/tracker.conf
自启动Tracker:
echo '/usr/bin/fdfs_trackerd /etc/fdfs/tracker.conf' >> /etc/rc.d/rc.local
Storage安装
安装同Tracker。
配置Storage(vim /etc/fdfs/storage.conf):
## 是否禁用该配置文件# false:开启 # true:禁用 disabled=false # 组名称 group_name=group1 # 绑定地址 # 空字符表示绑定所有地址 bind_addr= # 当连接其他存储server时,是否绑定地址 client_bind=true # 存储server端口 port=23000 # 连接超时 connect_timeout=30 # 网络超时 network_timeout=60 # 心跳 heart_beat_interval=30 # 磁盘使用报道的时间间隔 stat_report_interval=60 # 数据和日志目录 base_path=/mnt/fastdfs # 最大并发连接数 max_connections=256 # 接收和发送数据的缓冲区大小 buff_size = 256KB # 接受请求的线程数 accept_threads=1 # 执行请求的线程数 work_threads=4 # 磁盘读写是否分开 disk_rw_separated = true # 每个存储基路径的读线程数 disk_reader_threads = 1 # 每个存储基路径的写线程数 disk_writer_threads = 1 # 当没有进行同步时, 多少毫秒后读取binlog sync_wait_msec=50 # 当同步完一个文件后, 暂停多少毫秒 # 0 表示不调用usleep sync_interval=0 # 每天存储同步的开始时间 sync_start_time=00:00 # 每天存储同步的结束时间 sync_end_time=23:59 # 同步多少个文件后,写入mark文件 write_mark_file_freq=500 # 路径(磁盘或挂载点)数 store_path_count=1 # 存储路径 store_path0=/mnt/fastdfs # 子目录数 subdir_count_per_path=256 # tracker地址,可以配置多个tracker_server tracker_server=10.112.88.105:22122 # tracker_server=10.112.88.104:22122 # 日志级别:alert error notice info debug log_level=debug # 运行进程的用户组,默认当前用户组 run_by_group= # 运行进程的用户,默认当前用户 run_by_user= # 允许的host,例子如下# "*" 表示所有 # 10.0.1.[1-15,20] # host[01-08,20-25].domain.com: # allow_hosts=10.0.1.[1-15,20] # allow_hosts=host[01-08,20-25].domain.com allow_hosts=* # 文件分布模式 # 0: 轮询 # 1: 随机 file_distribute_path_mode=0 # 写多少个文件后,轮到下一个路径 file_distribute_rotate_count=100 # 当写入多大文件时,调用fsync # 0: 不调用 # other: 文件大小(byte) fsync_after_written_bytes=0 # 同步内存日志到磁盘的间隔时间,默认10s sync_log_buff_interval=10 # 同步binlog到磁盘的间隔时间,默认10s sync_binlog_buff_interval=10 # 同步存储状态信息到磁盘的间隔时间,默认300s sync_stat_file_interval=300 # 线程栈大小 >= 512KB thread_stack_size=512KB # 上传文件的优先级,tracker中使用 upload_priority=10 # the NIC alias prefix, such as eth in Linux, you can see it by ifconfig -a # multi aliases split by comma. empty value means auto set by OS type # default values is empty if_alias_prefix= # 是否检查文件重复 check_file_duplicate=0 # 文件签名方法 ## hash: hash ## md5: MD5 file_signature_method=hash # 存储文件索引的命名空间,check_file_duplicate=true时 key_namespace=FastDFS # 设置与FastDHT保持长连接的数目,0表示使用短连接 keep_alive=0 # FastDHT server列表,需要安装FastDHT ##include /home/yuqing/fastdht/conf/fdht_servers.conf # 是否记录访问日志 use_access_log = true # 是否每天滚动访问日志文件 rotate_access_log = true # 访问日志滚动时间点 access_log_rotate_time=00:00 # 是否每天滚动错误日志文件 rotate_error_log = true # 错误日志滚动时间点 error_log_rotate_time=00:00 # 访问日志滚动大小 rotate_access_log_size = 0 # 错误日志滚动大小 rotate_error_log_size = 0 # 日志保留天数 log_file_keep_days = 7 # 同步文件时是否跳过无效的文件 file_sync_skip_invalid_record=false # 是否使用连接池 use_connection_pool = false # 连接最大空间时间 connection_pool_max_idle_time = 3600 # 域名 http.domain_name= # http端口 http.server_port=8888
启动Storage:
/usr/bin/fdfs_storaged /etc/fdfs/storage.conf
自启动Storage:
echo '/usr/bin/fdfs_storaged /etc/fdfs/storage.conf' >> /etc/rc.d/rc.local
FastDFS基本操作集群监控
Tracker和Storage都启动好后,可以通过fdfs_monitor监控当前集群情况:
# vim /etc/fdfs/client.conf connect_timeout=30 network_timeout=60 base_path=/mnt/fastdfs_client tracker_server=10.112.88.105:22122 log_level=debug use_connection_pool = false connection_pool_max_idle_time = 3600 load_fdfs_parameters_from_tracker=false use_storage_id = false storage_ids_filename = storage_ids.conf
/usr/bin/fdfs_monitor /etc/fdfs/client.conf
server_count=1, server_index=0 Tracker is 10.112.88.105:22122 group count: 2 Group 1: group name = group1 disk total space = 184022 MB disk free space = 183969 MB trunk free space = 0 MB Storage count = 3 active server count = 3 ... Storage 1: id = 10.112.88.106 ip_addr = 10.112.88.106 ACTIVE ... Storage 2: id = 10.112.88.109 ip_addr = 10.112.88.109 (vm-10-112-88-109) ACTIVE ... Storage 3: id = 10.112.88.151 ip_addr = 10.112.88.151 ACTIVE ... Group 2: group name = group2 disk total space = 184022 MB disk free space = 183695 MB trunk free space = 0 MB Storage count = 2 active server count = 2 ... Storage 1: id = 10.112.88.153 ip_addr = 10.112.88.153 ACTIVE ... Storage 2: id = 10.112.88.158 ip_addr = 10.112.88.158 ACTIVE ...文件上传
文件上传可通过fdfs_test进行测试:
/usr/bin/fdfs_test /etc/fdfs/client.conf upload /var/log/yum.log
tracker_query_storage_store_list_without_group: server 1. group_name=, ip_addr=10.112.88.106, port=23000 server 2. group_name=, ip_addr=10.112.88.109, port=23000 server 3. group_name=, ip_addr=10.112.88.151, port=23000group_name=group1, ip_addr=10.112.88.109, port=23000 storage_upload_by_filenamegroup_name=group1, remote_filename=M00/00/00/CnBYbVc8AaOAL78UAAADvvLPPRA782.logsource ip address: 10.112.88.109 file timestamp=2016-05-09 13:46:11 file size=958 file crc32=4073667856 example file url: http://10.112.88.109/group1/M00/00/00/CnBYbVc8AaOAL78UAAADvvLPPRA782.log storage_upload_slave_by_filenamegroup_name=group1, remote_filename=M00/00/00/CnBYbVc8AaOAL78UAAADvvLPPRA782_big.logsource ip address: 10.112.88.109 file timestamp=2016-05-09 13:46:11 file size=958文件下载
文件下载也可通过fdfs_test进行测试:
/usr/bin/fdfs_test /etc/fdfs/client.conf download group1 M00/00/00/CnBYbVc8AaOAL78UAAADvvLPPRA782_big.log
storage=10.112.88.109:23000 download file success, file size=958, file save to CnBYbVc8AaOAL78UAAADvvLPPRA782_big.log文件访问
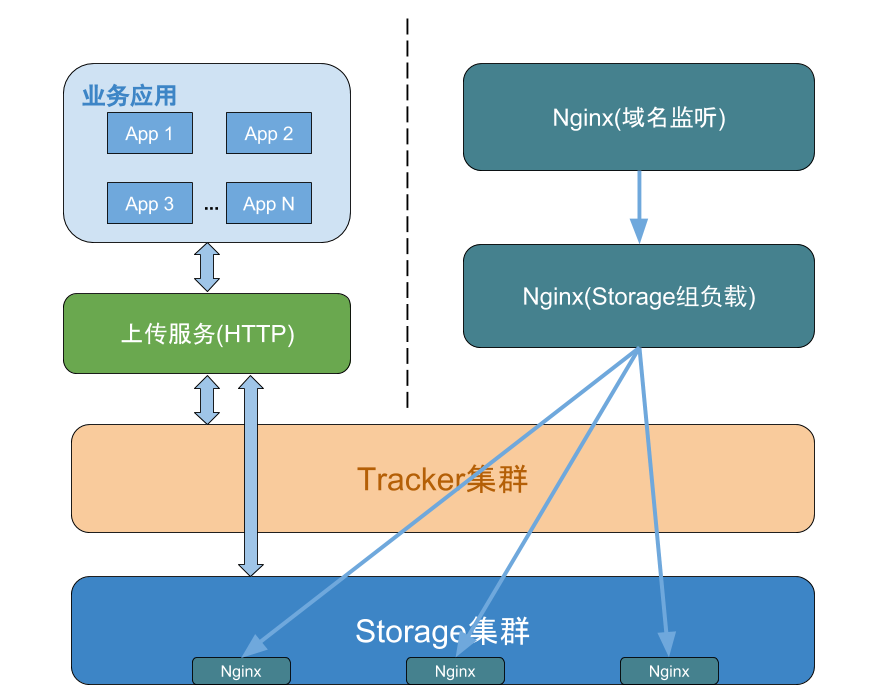
通常,对于图片和文件的访问,是不太可能走TCP,而是通过简单的HTTP访问,这时需要通过一些Web服务器(如nginx,apache)来代理,fastdfs也有了nginx的支持,下面则将通过安装nginx来完成文件访问,之前的开发环境将变为:
在Storage上配置fastdfs-nginx-module所需的配置文件:
# 配置fastdfs-nginx-module所需的配置文件mod_fastdfs.conf,http.conf,mime.types # vim /etc/fdfs/mod_fastdfs.conf connect_timeout=5 network_timeout=30 base_path=/mnt/fastdfs/logs load_fdfs_parameters_from_tracker=true storage_sync_file_max_delay = 86400 use_storage_id = false storage_ids_filename = storage_ids.conf tracker_server=10.112.88.105:22122 storage_server_port=23000 group_name=group1 # 与该Storage的配置一致 url_have_group_name = true store_path_count=1 # 与该Storage的配置一致 store_path0=/mnt/fastdfs # 与该Storage的配置一致 log_level=debug log_filename=/usr/local/nginx/logs/mod_fastdfs.log response_mode=proxy if_alias_prefix= #include http.conf flv_support = true flv_extension = flv group_count = 0 # vim /etc/fdfs/http.conf http.default_content_type = application/octet-stream http.mime_types_filename=mime.types http.anti_steal.check_token=false http.anti_steal.token_ttl=900 http.anti_steal.secret_key=FastDFS1234567890 http.anti_steal.token_check_fail=/etc/fdfs/check_failed.jpg # 配置mime.types cp /path/to/fastdfs/conf/mime.types /etc/fdfs/mime.types cp /path/to/fastdfs/conf/check_failed.jpg /etc/fdfs/check_failed.jpg
# 解压缩fastdfs-nginx-module_v1.16.tar.gz tar -zxf fastdfs-nginx-module_v1.16.tar.gz # 配置fastdfs-nginx-module/src/config # vim fastdfs-nginx-module/src/config # CORE_INCS 和 CFLAGS ngx_addon_name=ngx_http_fastdfs_module HTTP_MODULES="$HTTP_MODULES ngx_http_fastdfs_module" NGX_ADDON_SRCS="$NGX_ADDON_SRCS $ngx_addon_dir/ngx_http_fastdfs_module.c" CORE_INCS="$CORE_INCS /path/to/fastdfs /path/to/fastcommon/" CORE_LIBS="$CORE_LIBS -L/usr/local/lib -lfastcommon -lfdfsclient" CFLAGS="$CFLAGS -D_FILE_OFFSET_BITS=64 -DFDFS_OUTPUT_CHUNK_SIZE='256*1024' -DFDFS_MOD_CONF_FILENAME='\"/path/to/mod_fastdfs.conf\"'"在Storage上安装nginx:
# 安装nginx依赖包 yum -y install gcc gcc-c++ make zlib-devel pcre-devel openssl-devel # 建立nginx用户 groupadd nginx useradd -g nginx nginx --shell=/sbin/nologin # 配置,编译,安装nginx tar -zxf nginx-1.9.9.tar.gz cd nginx-1.9.9 ./configure --prefix=/usr/local/nginx --add-module=/path/to/fastdfs-nginx-module/src --group=nginx --user=nginx make && make install # 更改nginx目录权限 chown -R nginx:nginx /usr/local/nginx
# 最简配置/usr/local/nginx/conf/nginx.conf
user nginx;
worker_processes 1;
events {
worker_connections 1024;
}
http {
server {
listen 80;
server_name localhost;
# group1为该Storage所在的group
location /group1/M00 {
# 该Storage的data目录
root /mnt/fastdfs/data;
# 由于fastdfs保存的文件名已经编码,源文件名将丢失,应用可通过在请求url后加oname参数指定源文件名
if ($arg_oname != ''){
add_header Content-Disposition "attachment;filename=$arg_oname";
}
# 调用nginx-fastdfs-module模块
ngx_fastdfs_module;
}
}
}# 启动nginx,logs/error.log没有错误,即启动成功 /usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf在其他服务器上安装用于图片文件负载的nginx:
# 安装过程同上,只是不需要配置和安装fastdfs-nginx-module模块
# 最简配置/usr/local/nginx/conf/nginx.conf
user nginx;
worker_processes 1;
events {
worker_connections 1024;}
http {
# group1的Storage集群
upstream group1_cluster {
server 10.112.88.106;
server 10.112.88.109;
server 10.112.88.151;
}
# group2的Storage集群
upstream group2_cluster {
server 10.112.88.153;
server 10.112.88.158;
}
server {
listen 80;
server_name 10.112.88.105;
location /group1 {
proxy_pass http://group1_cluster; proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
}
location /group2 {
proxy_pass http://group2_cluster; proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
}
}
}下面是一种可供参考的图片文件服务器部署策略:FastDFS的一些运行机制Client与Tracker通讯
Client大部分的操作过程都是要先查询Tracker,Tracker返回目标Storage IP,然后Client再连接到该Storage,执行具体的操作。上传文件时,如何选择Storage Group,Storage及Storage Path:
# 上传时如何选择 Storage Group # 0: 轮询,这对于后期扩展group时,会有存储容量不均匀等问题, # 1: 制定group名称, # 2: 负载均衡, 选择空闲空间(group内空闲存储空间最小的Storage)最大的存储group,这比较适合后期扩展group,但扩展时最好能多于1个组,避免单个组的负载太大 store_lookup=2 # 选择哪一个存储group,当store_lookup=1时,须指定存储group的名称 store_group=group2
# 上传时如何选择 Storage # 0: 轮询,这是比较常用的策略 # 1: 以ip地址排序的第一个地址 # 2: 以优先级排序,优先级可在storage.conf中配置 store_server=0
# 上传时如何选择 Storage Path # 0: 轮询 # 2: 负载均衡, 选择空闲空间最大的路径来存储文件 store_path=0除上述策略外,Storage需满足两个条件,才能最终被选择:Storage的状态为ACTIVE,及Storage的空闲空间大于配置的预留空间。下载文件时,如何选择Storage:
Client下载时,需要传入对应的group,因此只需再选择其中一个Storage:
# 下载时如何选择 Storage # 0: 轮询# 1: 选择该文件上传时的源Storage,从文件ID中可以反解析出 download_server=0删除文件时,策略同下载文件。
同组Storage之间的文件同步
FastDFS通过在同组内的多个Storage同步文件来保证系统的容错性(Fault Tolerance)。当Storage启动时,会为同组内的其他Storage分别开启一个线程,进行文件同步。文件同步主要通过binlog来实现,该文件被放置在/path/to/storage_data_path/sync下:
# Storage(10.112.88.106) ll /mnt/fastdfs/data/sync total 24 -rw-r--r-- 1 root root 130 May 10 18:15 10.112.88.109_23000.mark -rw-r--r-- 1 root root 130 May 10 18:15 10.112.88.151_23000.mark -rw-r--r-- 1 root root 9722 May 10 18:15 binlog.000 -rw-r--r-- 1 root root 1 May 06 17:50 binlog.index
cat binlog.index 0binlog.index中记录了当前binlog文件的索引号,如0表示binlog.000,1表示binlog.001。
cat binlog.000 1462789147 C M00/00/00/CnBYalc5npuANWf2AAAALHr0pq04296.sh 1462799147 c M00/00/00/CnBYbVc7ygaAWBVsAAxRqMiPPm805.docx 1462789147 c M00/00/00/CnBYl1c7ywuAJmkjAAxRqMiPPm827.docx 1462789147 C M00/00/00/CnBYalc757uAQmahAAAAK4C4i08968.png 1462789147 c M00/00/00/CnBYbVc8AaOAL78UAAADvvLPPRA782.log ...binlog.000中则记录了各项操作,如第一行:
| 1462789147 | 操作的时间戳。 |
| C | 操作类型。其中大写字母的操作表示为源操作,小写字母的操作表示为备份操作(由同组其他Storage同步的操作),如:C表示源创建、c表示备份创建; A表示源追加、a表示备份追加; D表示源删除、d表示备份删除; U表示源更新(如元数据)、u表示备份更新; M表示源修改(部分修改)、m表示备份修改; T表示源截取、t表示备份截取; L表示源创建符号链接、l表示备份创建符号链接; |
| M00/00/00/CnBYalc5npuANW f2AAAALHr0pq04296.sh | 文件ID。文件ID由以下几部分组成:M00:Storage配置的虚拟路径,与选项store_path*对应; /00/00:Storage在每个虚拟磁盘路径下创建的两级目录; CnBYalc5npuANWf2AAAALHr0pq04296.sh:由Storage生成,其中包括源Storage IP,文件创建时间戳,文件大小,crc32码及文件扩展名。 |
cat 10.112.88.109_23000.mark binlog_index=0 # 同步的binlog文件索引号 binlog_offset=9722 # 同步完的binlog文件位置 need_sync_old=1 # 本机器曾作为10.112.88.109的源机器 sync_old_done=1 # 源同步已完成 until_timestamp=1463393441 scan_row_count=167 sync_row_count=56从该文件中可以知道,当前同步给10.112.88.109这台Storage的binlog文件为binlog.000,已同步到偏移量为9722的位置,恰好为binlog.000的文件大小,说明已经完全同步。need_sync_old表示是否需要同步旧文件给对方,sync_old_done表示若需要同步旧文件,那么旧文件是否同步完成,until_timestamp表示源主机同步的操作截止时间,scan_row_count表示扫描过的操作记录行数,sync_row_count表示同步完的操作记录行数,文件同步延迟问题
当用户上传文件后,还未完全同步到同组内其他Storage时,那么用户下载文件时,如何避免文件同步延迟问题呢? 一个最简单的解决办法则是,优先选择源Storage下载文件即可,这可以在Tracker的配置文件中设置,对应的参数名为download_server。另外一种选择Storage的方法是轮询选择(round-robin),当Client询问Tracker时,有哪些Storage可以下载指定文件呢?Tracker将返回满足如下四个条件之一的Storage:1. 该Storage是该文件的源Storage,文件ID中可以解析出其源Storage IP;
2. 文件的创建时间戳 < Storage被同步到的文件时间戳,这意味着该文件已经同步了该Storage上。
3. 文件的创建时间戳 = Storage被同步到的文件时间戳,且(当前时间—文件创建时间戳) > 一个文件同步完成需要的最大时间(可配置storage_sync_file_max_time,如5分钟);
4. (当前时间 — 文件创建时间戳) > 文件同步延迟阈值(可配置storage_sync_file_max_delay,比如把阈值设置为1天,表示文件同步在1天内肯定可以完成)。
那么Tracker如何知道各组内Storage之间的同步进度呢,Storage会为每个Tracker分别开启一个线程,将同步信息报道给Tracker,其中当前Storage被同步的最近时间戳为同组内其他Storage同步的最小时间戳,如一组内有Storage-A、Storage-B、Storage-C三台机器,B最后同步给A的Binlog-timestamp为100,C最后同步给A的Binlog-timestamp为200,那么A机器的被同步最小时间戳就为100。Tracker会将该信息记录到storage_sync_timestamp.dat文件中:
# cat /mnt/fastdfs/data/storage_sync_timestamp.dat group1,10.112.88.106,0,1463739193,1463739193 group1,10.112.88.109,1463739283,0,1463739283 group1,10.112.88.151,1463739079,1463739079,0 group2,10.112.88.158,0,1463815913 group2,10.112.88.153,1463815051,0如第一行,在组group1内,10.112.88.106这台Storage同步给10.112.88.109的最后时间戳为1463739193,同步给10.112.88.151的最后时间戳为1463739193,而第一个0表示自己同步自己。那么从第三列可以看出,10.112.88.106被同步的最小时间戳为1463739079。上述文件storage_sync_timestamp.dat,并不会被实时更新(当Tracker重启时会更新),Storage同步信息会实时在Tracker内存中,可通过fdfs_monitor查看。集群扩展增加Storage Group
增加Storage Group将直接对集群进行容量扩展。这也是后期维护比较常见的操作,新组添加进来后,若配置了store_lookup=2时,新加入的组将在一段时间内成为文件上传的单点,有可能对性能有所下降,比较建议在新加组时,能添加1个以上的组。增加Storage
在同组内添加Storage后,将会开启一个叫源同步的过程,也就是从组内现有的一台机器(这台机器称为源机器)上同步历史数据到新机器的过程。源机器选择:
当Storage是首次加入组时,会向Tracker集群中的一个发送TRACKER_PROTO_CMD_STORAGE_SYNC_DEST_REQ(87)命令,向Tracker查询,由同组内哪一台Storage作为源机器。当Tracker收到该请求后,根据当前组内的机器状态,若组内没有机器,则告诉新机器不需要进行源同步;若组内有机器但是没有状态为ACTIVE的机器,那么返回一个错误,新机器将睡眠后重试;若组内有机器并且有状态为ACTIVE的机器,那么选择一台作为其源,返回两个值:当前时间作为源同步截止时间与源机器IP,新机器将该信息记录在本地(/mnt/fastdfs/data/.data_init_flag),同时将自己状态设置成WAIT_SYNC:
# cat /mnt/fastdfs/data/.data_init_flag storage_join_time=1463393440 # 加入集群的时间戳 sync_old_done=1 # 已完成获取源主机的操作 sync_src_server=10.112.88.106 # 源机器IP sync_until_timestamp=1463393441 # 源同步截止时间 last_ip_addr=10.112.88.109last_server_port=23000 last_http_port=8888 current_trunk_file_id=0 trunk_last_compress_time=0源同步过程:
对于源机器,如10.112.88.106,通过与Tracker通讯,得知有新机器加入,如10.112.88.109,于是启动一个线程与10.112.88.109进行通讯;再通过Tracker查询10.112.88.109的源机器IP和源同步截止时间,发现自己是其源机器,并在本地创建10.112.88.109_23000.mark,并写入need_sync_old=1; sync_old_done=0; util_timestamp = 查询到的源同步截止时间;接着请求Tracker将10.112.88.109的状态设置成SYNING,然后开始读取binlog中的源操作同步给10.112.88.109,直到在某一个时刻,取不到更多的binlog时,请求Tracker将10.112.88.109状态设置成OFFLINE,此时源同步完成;在下一个心跳中,Tracker会将10.112.88.109状态设置成ACTIVE。对于非源机器,如10.112.88.151,也会在本地创建10.112.88.109_23000.mark,并写入need_sync_old=0; sync_old_done=0; util_timestamp = 0;此时,并不会对10.112.88.109进行同步操作,而会等等待10.112.88.109状态为ACTIVE后,才开始同步操作。Tracker-Leader Server
在FastDFS之中,可以配置多个Tracker,在运行过程中会选择其中一个作为Leader,由该Leader执行一些选举操作。在早期版本中Tracker-Leader有两个作用,分别是:为新加入的Storage分配一个源Storage;为开启合并存储的Group选择Trunk-Server。但是在最新的版本中实际上只有第二个作用,也就是选择Trunk-Server。对于新加入Storage分配源Storage其实是任何一个Tracker都可以进行的,为了避免多次分配,在Storage请求Tracker分配源时进行了互斥量同步。Tracker-Leader选择过程
1. 向所有的Tracker(包括自己)发送一个TRACKER_GET_STATUS命令,来获取对方的状态信息,该信息包括:是否为Leader,到目前的运行时间和上次停止时间间隔(也就是最后一次停止到启动的时间间隔),只要获取到至少一个该状态成功,则继续下一步;
2. 对所有返回成功的Tracker-Status进行排序,获得状态值最高的Tracker;
3. 若状态最高的Tracker是自己,那么进入一个两阶段提交协议: 通知除自己之外的所有Tracker,将要变更Tracker-Leader,只要有一个Tracker通知成功,则进入下一步; 通知所有的Tracker(包括自己),将Leader变更成自己,只要有一个Tracker返回成功,则表示整个变更成功(此处通知了自己,那么这个步骤肯定会成功)。
4. 若最高状态的Tracker当前就是Leader,那么就设置本地标志为g_tracker_servers.leader_index为该Tracker。
否则,等待真正的Tracker Leader发起Leader变更消息;
文件合并存储
大多数文件系统,对于海量小文件的存储时,都会面临LOSF问题,比较通用的解决方案则是文件合并,FastDFS也提供了该功能,需要对Tracker作相关配置:
use_trunk_file = false # 是否启用trunk存储 slot_min_size = 256 # trunk文件最小分配单元,不足该大小,也会占用这么大 slot_max_size = 16MB # trunk内部存储的最大文件,超过该值会被独立存储trunk_file_size = 64MB # trunk文件本身大小 trunk_create_file_advance = false # 是否提前创建trunk文件 trunk_create_file_time_base = 02:00 # 提前创建trunk文件的基准时间 trunk_create_file_interval = 86400 # 提前创建trunk文件的时间间隔 trunk_create_file_space_threshold = 20G # trunk创建文件的最大空闲空间 trunk_init_check_occupying = false # 启动时是否检查每个空闲空间列表项已经被使用 trunk_init_reload_from_binlog = false # 是否纯粹从trunk-binlog重建空闲空间列表 trunk_compress_binlog_min_interval = 0 # 对trunk-binlog进行压缩的时间间隔当启用文件合并后,上传文件返回的文件ID将不能与Storage中存储路径上的文件一一对应了,而是多个文件会合并存在在一个trunk文件中,不难想到,返回的文件ID中包含trunk文件,源文件所在trunk文件的offset等信息:
file_size: 占用大文件的空间 (注意按照最小slot-256字节进行对齐) mtime: 文件修改时间 crc32: 文件内容的crc32码 formatted_ext_name: 文件扩展名 alloc_size: 文件大小与size相等 id: trunk文件ID如000001 offset: 文件内容在trunk文件中的偏移量 size: 文件大小如何管理合并存储中的空闲内存
一个Trunk文件默认大小为64MB,因此创建Trunk文件时,很可能会产生空余空间,比如为存储一个10MB文件,创建一个Trunk文件,那么就会剩下接近54MB的空间(忽略其真实文件的一些头信息),下次若再次存储10MB文件时,就不需要创建新的Trunk文件文件,而是存储在现有的Trunk文件。此外当删除一个文件时,也会产生空余空间。在Storage内部会为每个store_path维护一颗以空闲块大小作为关键字的平衡树,相同大小的空闲块保存在链表之中。每当需要存储一个文件时会首先到平衡树中查找一块最相近的空闲内存快,若该内存快有余,则被加入到平衡树中;若此时找不到一块能容纳新文件的空闲内存,则会创建一个新的trunk文件。由Trunk Server分配空闲内存
若同组内Storage均能为新上传的文件分配空闲内存,则有可能由于该组Storage文件同步延迟问题,导致数据存储冲突,如文件a上传时,由Storage A将其分配到000001这个trunk文件的起始位置,若还未来得及同步到同组的Storage B,此时文件b上传,由Storage B也将其分配到000001这个trunk文件的起始位置,这时就发生了存储冲突,这其实只要能保证Storage A和Storage B共享同一份空闲内存平衡树数据是可以解决的,但一旦涉及到网络,则有可能发生延迟,因此需要一个专门用于分配空闲内存的角色,即Trunk Server。下图则是空闲内存分配过程:
Trunk文件同步
相对于非trunk文件,trunk文件的同步也是通过binlog文件(TrunkBinlog文件)的方式进行,格式如下:
1410750754 A 0 0 0 1 0 67108864 1410750754 D 0 0 0 1 0 67108864 # 字段说明1410750754: 时间戳 A/D: 创建/删除 0: store_path_index 0: sub_path_high 0: sub_path_low 1: fileId 0: offset 67108864: size 文件大小,按照slot对齐Trunk Server选择
之前提到过,Trunk Server是由Tracker Leader进行选举,大致过程如下:1. 依次向组内当前状态为ACTIVE的Storage发送TRUNK_GET_BINLOG_SIZE命令,来查询每个Storage当前保存的Trunk-Binlog的文件大小,来找到Trunk-Binlog文件最大的Storage;
2. 若该Group的最后一个Trunk Server与要设置的新的Trunk Server并非同一个,则像该新的Trunk Server发送TRUNK_DELETE_BINLOG_MARKS命令,让其删除从trunk-binlog同步给组内其他Storage的mark文件。(既然这个Trunk Server是新的,那么就要清除trunk-binlog的同步状态,使其从头同步trunk-binlog给组内的其他Storage);
3. 变更该组的Trunk Server,并将修改写入到storage_groups_new.dat文件之中,更新该组的最后Trunk Server设置,设置Trunk Server已经变更标志,该标志使得在与Storage的心跳中通知对方Trunk Server已经变更。
总结
以上,则是关于FastDFS的一些实践,对于一些图片,文件的存储,也算是一种比较轻量的解决方案。转载自: https://t.hao0.me/storage/2016/05/10/fastdfs-practice.html

相关文章推荐
- 高可用高性能分布式文件系统FastDFS实践Java程序
- 高可用高性能分布式文件系统FastDFS实践Java程序
- 高可用高性能分布式文件系统FastDFS实践Java程序
- 分布式文件系统FastDFS最佳部署实践
- FastDFS 4.02 发布,分布式文件系统
- 分布式文件系统FastDFS原理介绍
- FastDFS分布式文件系统
- Linux下分布式文件系统FastDFS安装与配置
- CentOS 7配置FastDFS与Ngnix实践
- 分布式文件系统FastDFS设计原理
- FastDFS分布式文件系统集群安装与配置
- 分布式文件系统 - FastDFS 简单了解一下
- 分布式文件系统 FastDFS 5.0.5 & Linux CentOS 7 安装配置
- FastDFS分布式文件系统集群安装与配置
- linux上安装分布式文件系统FastDFS(单节点)
- 分布式文件系统FastDFS介绍安装配置
- 分布式文件系统FastDFS
- 【C#|.NET】利用FastDFS打造分布式文件系统
- JavaWeb项目架构之FastDFS分布式文件系统
- ChinaUnix中fastdfs论坛资料之FastDFS一个高效的分布式文件系统