分治策略Divide and Conquer
2016-08-21 15:35
357 查看
在计算机科学中,分治法是一种很重要的算法。字面上的解释是“分而治之”,通常是递归算法,就是 把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。这个技巧是很多高效算法的基础,如排序算法(快速排序,归并排序),傅立叶变换。
任何一个可以用计算机求解的问题所需的计算时间都与其规模有关。问题的规模越小,越容易直接求解,解题所需的计算时间也越少。例如,对于n个元素的排序问题,当n=1时,不需任何计算。n=2时,只要作一次比较即可排好序。n=3时只要作3次比较即可…而当n较大时,问题就不那么容易处理了。要想直接解决一个规模较大的问题,有时是相当困难的。
算法 1 binarysearch(T,x)
输入:排好序的数组T;数x
输出:j
1. l⟵1;r⟵n
2. while l≤r do
3. m⟵⌊l+r2⌋
4. if T[m]=x then return m
5. else if T[m]≥x then r⟵m−1
6. else l⟵m+1
7.return 0
分析:
1、该问题的规模缩小到一定的程度就可以容易地解决;
2、该问题可以分解为若干个规模较小的相同问题;
3、分解出的子问题的解可以合并为原问题的解;
4、分解出的各个子问题是相互独立的。
很显然此问题分解出的子问题相互独立,即在a[i]的前面或后面查找x是独立的子问题,因此满足分治法的第四个适用条件。
算法复杂度分析:
⎧⎩⎨⎪⎪W(n)=W(⌊n2⌋)+1W(1)=1
每执行一次算法的while循环, 待搜索数组的大小减少一半。因此,在最坏情况下,while循环被执行了O(logn) 次。循环体内运算需要O(1) 时间,因此整个算法在最坏情况下的计算时间复杂性为O(logn) 。
上述算法就是用分治算法,它们的共同特点是:对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。
算法2: divide−and−conquer(P)
1.if(|P|≤c) S(P) // 解决小规模的问题
2. divide P into smaller subinstances P1,P2,…,Pk //分解问题
3. for i=1 to k do
4. yi←divide−and−conquer(Pi) //递归的解各子问题
5. ReturnMerge(y1,y2,y3,…yk−1,yk) //将各子问题的解合并为原问题的解
人们从大量实践中发现,在用分治法设计算法时,最好使子问题的规模大致相同。即将一个问题分成大小相等的k个子问题的处理方法是行之有效的。这种使子问题规模大致相等的做法是出自一种平衡(balancing)子问题的思想,它几乎总是比子问题规模不等的做法要好。
一个分治法将规模为n的问题分成k个规模为nm的子问题去解。设分解阀值c=1,且S(P)解规模为1的问题耗费1个单位时间。再设将原问题分解为k个子问题以及用Merge将k个子问题的解合并为原问题的解需用f(n)个单位时间。用T(n)表示该分治法解规模为|P|=n的问题所需的计算时间,则有:
⎧⎩⎨⎪⎪W(n)=W(|P1|)+W(|P2|)+...+W(|Pk|)+f(n)W(c)=C
无穷数列1,1,2,3,5,8,13,21,34,55,……,称为Fibonacci数列。它可以递归地定义为:
⎧⎩⎨⎪⎪⎪⎪F(n)=1,F(n)=1,F(n)=F(n−1)+F(n−2),if n=0if n=1if n>1
实现:
分治法所能解决的问题一般具有以下几个特征:
1) 该问题的规模缩小到一定的程度就可以容易地解决
2) 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
3) 利用该问题分解出的子问题的解可以合并为该问题的解;
4) 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
第一条特征是绝大多数问题都可以满足的,因为问题的计算复杂性一般是随着问题规模的增加而增加;
第二条特征是应用分治法的前提它也是大多数问题可以满足的,此特征反映了递归思想的应用;
第三条特征是关键,能否利用分治法完全取决于问题是否具有第三条特征,如果具备了第一条和第二条特征,而不具备第三条特征,则可以考虑用贪心法或动态规划法。
第四条特征涉及到分治法的效率,如果各子问题是不独立的则分治法要做许多不必要的工作,重复地解公共的子问题,此时虽然可用分治法,但一般用动态规划法较好。
解决方法:在递归算法中消除递归调用,使其转化为非递归算法。
1、采用一个用户定义的栈来模拟系统的递归调用工作栈。该方法通用性强,但本质上还是递归,只不过人工做了本来由编译器做的事情,优化效果不明显。
2、用递推来实现递归函数。
3、通过变换能将一些递归转化为尾递归,从而迭代求出结果。
后两种方法在时空复杂度上均有较大改善,但其适用范围有限。
大整数的乘法:请设计一个有效的算法,可以进行两个n位大整数的乘法运算。设X ,Y 是两个n位二进制数,n=2k,求XY。
解:以每为乘1次作为1次基本运算,则普通乘法的时间复杂度是O(n2) .
下面考虑分治算法将X 和Y都分成相等的两段,每段n/2 位,X的上半段(高位部分)记作A,下半段(低位部分)记作B;类似地,Y的上半段(高位部分)记作C,下半段(低位部分)记作D,那么有:
X=A2n/2+B
Y=C2n/2+D
XY=AC∗2n+(AD+BC)∗2n2+BD
时间复杂度的递推方程如下:
⎧⎩⎨⎪⎪T(n)=O(1),T(n)=4T(n2)+cn,if n = 1if n > 1
W(n)=O(nlog4)=O(n2) 这个分治算法与普通乘法的时间复杂度一样。根据代数知识,不难发现:
AD+BC=(A-B)(D-C)+AC+BD
为了降低时间复杂度,必须减少乘法的次数
XY=AC∗2n+(AD+BC)∗2n2+BD
⟹XY=AC∗2n+((A−B)(D−C)+AC+BD)∗2n2+BD
细节问题:两个XY的复杂度都是O(nlog3),但考虑到A+B,C+D可能得到n+1位的结果,使问题的规模变大.于是递推方程:
⎧⎩⎨⎪⎪T(n)=O(1),T(n)=3T(n2)+cn,if n = 1if n > 1
解得:
W(n)=O(nlog3)=O(n1.59)
较大的改进.更快的方法?? 如果将大整数分成更多段,用更复杂的方式把它们组合起来,将有可能得到更优的算法。Strassen矩阵乘法.矩阵乘法问题
对于两个n*n的矩阵A,B,求其乘积.传统方法:O(n3).A和B的乘积矩阵C中的元素C[i,j].若依此定义来计算A和B的乘积矩阵C,则每计算C的一个元素C[i][j],需要做n次乘法和n-1次加法。因此,算出矩阵C的个元素所需的计算时间为O(n3)
算法复杂度分析
⎧⎩⎨⎪⎪W(n)=8W(n2)+cn2W(1)=1
W(n)=O(nlog8)=O(n3)这个分治算法与普通乘法的时间复杂度一样.
为了降低时间复杂度,必须减少乘法的次数。
算法复杂度分析
⎧⎩⎨⎪⎪W(n)=7W(n2)+18(n2)2W(1)=1
由主定理得:
W(n)=O(nlog27)=O(n2.8075) 较大的改进
更快的方法??
Hopcroft和Kerr已经证明(1971),计算2个2×2矩阵的乘积,7次乘法是必要的。因此,要想进一步改进矩阵乘法的时间复杂性,就不能再基于计算2×2矩阵的7次乘法这样的方法了。或许应当研究3×3或5×5矩阵的更好算法。
在Strassen之后又有许多算法改进了矩阵乘法的计算时间复杂性。目前最好的计算时间上界是 O(n^2.376)
是否能找到O(n^2)的算法?
伪码如下
完成测试代码
Strassen.h
Strassen.cpp
实现
例如:正整数6有如下11种不同的划分,所以p(6) = 11:
前面的几个例子中,问题本身都具有比较明显的递归关系,因而容易用递归函数直接求解。
在本例中,如果设p(n)为正整数n的划分数,则难以找到递归关系,因此考虑增加一个自变量:在正整数n的所有不同划分中,将最大加数n1不大于m的划分个数记作q(n,m)。可以建立q(n,m)的如下递归关系。
(1) q(n,1)=1,n >= 1;当最大加数n1不大于1时,任何正整数n只有一种划分形式,即n = 1 + 1 + 1 + … +1.
(2) q(n,m) = q(n,n),m >= n; 最大加数n1实际上不能大于n。因此,q(1,m)=1。
(3) q(n,n)=1 + q(n,n-1); 正整数n的划分由n1=n的划分和n1 ≤ n-1的划分组成。
(4) q(n,m)=q(n,m-1)+q(n-m,m),n > m >1;正整数n的最大加数n1不大于m的划分由 n1 = m的划分和n1 ≤ m-1 的划分组成。
前面的一个例子中,问题本身都具有比较明显的递归关系,因而容易用递归函数直接求解。
在本例中,如果设p(n)为正整数n的划分数,则难以找到递归关系,因此考虑增加一个自变量:将最大加数n1不大于m的划分个数记作q(n,m)。可以建立q(n,m)的如下递归关系。
⎧⎩⎨⎪⎪⎪⎪⎪⎪q(n,m)=1,q(n,m)=q(n,m),q(n,m)=1+q(n,n−1),q(n,m)=q(n,m−1)+q(n−m,m),if n=1,m=1if n=1,m=1if n=mif n>m>1
正整数n的划分数p(n)=q(n,n)。
实现:
⎧⎩⎨⎪⎪n!=1,n!=n(n−1)!,if n=0 (边界条件)if n>0 (递归方程)
边界条件与递归方程是递归函数的二个要素,递归函数只有具备了这两个要素,才能在有限次计算后得出结果。
实现:
当n=1时,perm(R)=(r),其中r是集合R中唯一的元素;
当n>1时,perm(R)由(r1)perm(R1),(r2)perm(R2),…,(rn)perm(Rn)构成。
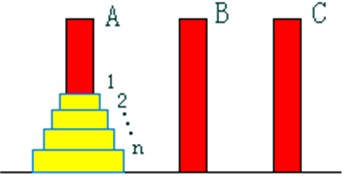
规则1:每次只能移动1个圆盘;
规则2:任何时刻都不允许将较大的圆盘压在较小的圆盘之上;
规则3:在满足移动规则1和2的前提下,可将圆盘移至a,b,c中任一塔座上。

分析
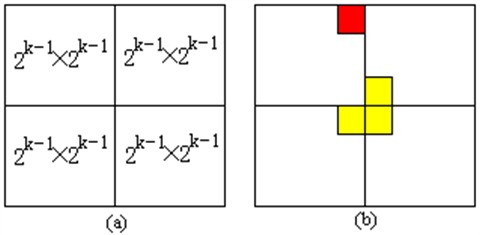
当k>0时,将2k×2k棋盘分割为4个2(k−1)×2(k−1)子棋盘所示。
特殊方格必位于4个较小子棋盘之一中,其余3个子棋盘中无特殊方格。为了将这3个无特殊方格的子棋盘转化为特殊棋盘,可以用一个L型骨牌覆盖这3个较小棋盘的会合处,从而将原问题转化为4个较小规模的棋盘覆盖问题。递归地使用这种分割,直至棋盘简化为棋盘1×1。
算法复杂度
⎧⎩⎨⎪⎪T(k)=O(1),T(k)=4T(k−1)+O(1),if k=0 if k>0
总共要4k−13张牌.T(n)=O(4k)渐近意义下的最优算法.
实现
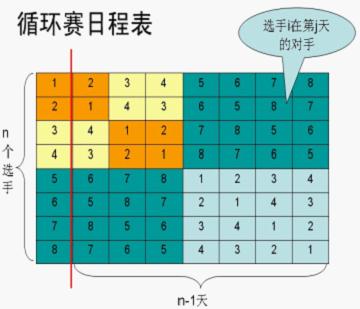
设有n=2k 个运动员要进行网球循环赛,设计一个满足以下要求的比赛日程表:
(1)每个选手必须与其他n−1个选手各赛一次;
(2)每个选手一天只能赛一次;
(3)循环赛一共进行n−1天。
按分治策略,将所有的选手分为两半,n个选手的比赛日程表就可以通过为n/2个选手设计的比赛日程表来决定。递归地用对选手进行分割,直到只剩下2个选手时,比赛日程表的制定就变得很简单。这时只要让这2个选手进行比赛就可以了。
实现
在最坏情况下,算法randomizedSelect需要O(n2)计算时间(在找最小元素的时候,总在最大元素处划分),但可以证明,算法randomizedSelect可以在O(n)平均时间内找出n个输入元素中的第k小元素。
如果能在线性时间内找到一个划分基准,使得按这个基准所划分出的2个子数组的长度都至多为原数组长度的ε倍(0<ε<1是某个正常数),那么就可以在最坏情况下用O(n)时间完成选择任务。
例如,若ε=910,算法递归调用所产生的子数组的长度至少缩短110。所以,在最坏情况下,算法所需的计算时间T(n)满足递归式T(n)≤T(9n10)+O(n) 。由此可得T(n)=O(n)。
步骤
第一步,将n个输入元素划分成én/5ù个组,每组5个元素,只可能有一个组不是5个元素。用任意一种排序算法,将每组中的元素排好序,并取出每组的中位数,共én/5ù个。
第二步,递归调用select来找出这én/5ù个元素的中位数。如果én/5ù是偶数,就找它的2个中位数中较大的一个。以这个元素作为划分基准。
分析
伪码描述如下:
算法复杂度分析
⎧⎩⎨⎪⎪T(n)≤C1,T(n)≤C2n+T(n5)+T(3n4),n <75n >= 75
解得时间复杂度是W(n)=O(n)。上述算法将每一组的大小定为5,并选取75作为是否作递归调用的分界点。这2点保证了T(n)的递归式中2个自变量之和n5+3n4=19n20=εn,0<ε<1。这是使W(n)=O(n)的关键之处。当然,除了5和75之外,还有其他选择。
实现
Donald E.Knuth 著,苏运霖 译,《计算机程序设计艺术,第2卷半数值算法》,国防工业出版社,2002年
Donald E.Knuth 著,苏运霖 译,《计算机程序设计艺术,第3卷排序与查找》,国防工业出版社,2002年
Thomas H. Cormen, Charles E.Leiserson, etc., Introduction to Algorithms(3rd edition), McGraw-Hill Book Company,2009
Jon Kleinberg, Ėva Tardos, Algorithm Design, Addison Wesley, 2005.
Sartaj Sahni ,《数据结构算法与应用:C++语言描述》 ,汪诗林等译,机械工业出版社,2000.
屈婉玲,刘田,张立昂,王捍贫,算法设计与分析,清华大学出版社,2011年版,2013年重印.
张铭,赵海燕,王腾蛟,《数据结构与算法实验教程》,高等教育出版社,2011年 1月
关于程序算法艺术与实践更多讨论与交流,敬请关注本博客和新浪微博songzi_tea.
任何一个可以用计算机求解的问题所需的计算时间都与其规模有关。问题的规模越小,越容易直接求解,解题所需的计算时间也越少。例如,对于n个元素的排序问题,当n=1时,不需任何计算。n=2时,只要作一次比较即可排好序。n=3时只要作3次比较即可…而当n较大时,问题就不那么容易处理了。要想直接解决一个规模较大的问题,有时是相当困难的。
分治策略的基本思想
分治算法是 将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。如果原问题可分割成k个子问题,1<k≤n,且这些子问题都可解并可利用这些子问题的解求出原问题的解,那么这种分治法就是可行的。由分治法产生的子问题往往是原问题的较小模式,这就为使用递归技术提供了方便。在这种情况下,反复应用分治手段,可以使子问题与原问题类型一致而其规模却不断缩小,最终使子问题缩小到很容易直接求出其解。这自然导致递归过程的产生。分治与递归像一对孪生兄弟,经常同时应用在算法设计之中,并由此产生许多高效算法。熟悉的例子
二分查找: 给定已按升序排好序的n个元素a[0:n−1],现要在这n个元素中找出一特定元素x。算法 1 binarysearch(T,x)
输入:排好序的数组T;数x
输出:j
1. l⟵1;r⟵n
2. while l≤r do
3. m⟵⌊l+r2⌋
4. if T[m]=x then return m
5. else if T[m]≥x then r⟵m−1
6. else l⟵m+1
7.return 0
分析:
1、该问题的规模缩小到一定的程度就可以容易地解决;
2、该问题可以分解为若干个规模较小的相同问题;
3、分解出的子问题的解可以合并为原问题的解;
4、分解出的各个子问题是相互独立的。
很显然此问题分解出的子问题相互独立,即在a[i]的前面或后面查找x是独立的子问题,因此满足分治法的第四个适用条件。
#include <iostream>
using namespace std;
// 查找成功返回value索引,查找失败返回-1
template <class T>
int binary_search(T array[],const T& value,int left,int right){
while (right >= left) {
int m = (left + right) / 2;
if (value == array[m])
return m;
if (value < array[m])
right = m - 1;
else
left = m + 1;
}
return -1;
}
int main()
{
int array[] = {0,1,2,3,4,5,6,7,8,9};
cout << "0 in array position: " << binary_search(array,0,0,9) << endl;
cout << "9 in array position: " << binary_search(array,9,0,9) << endl;
cout << "2 in array position: " << binary_search(array,2,0,9) << endl;
cout << "6 in array position: " << binary_search(array,6,0,9) << endl;
cout << "10 in array position: " << binary_search(array,10,0,9) << endl;
return 0;
}算法复杂度分析:
⎧⎩⎨⎪⎪W(n)=W(⌊n2⌋)+1W(1)=1
每执行一次算法的while循环, 待搜索数组的大小减少一半。因此,在最坏情况下,while循环被执行了O(logn) 次。循环体内运算需要O(1) 时间,因此整个算法在最坏情况下的计算时间复杂性为O(logn) 。
上述算法就是用分治算法,它们的共同特点是:对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。
分治算法的一般性描述
对这k个子问题分别求解。如果子问题的规模仍然不够小,则再划分为k个子问题,如此递归的进行下去,直到问题规模足够小,很容易求出其解为止。将求出的小规模的问题的解合并为一个更大规模的问题的解,自底向上逐步求出原来问题的解。分治算法divide-and-conquer的伪码描述如下:算法2: divide−and−conquer(P)
1.if(|P|≤c) S(P) // 解决小规模的问题
2. divide P into smaller subinstances P1,P2,…,Pk //分解问题
3. for i=1 to k do
4. yi←divide−and−conquer(Pi) //递归的解各子问题
5. ReturnMerge(y1,y2,y3,…yk−1,yk) //将各子问题的解合并为原问题的解
人们从大量实践中发现,在用分治法设计算法时,最好使子问题的规模大致相同。即将一个问题分成大小相等的k个子问题的处理方法是行之有效的。这种使子问题规模大致相等的做法是出自一种平衡(balancing)子问题的思想,它几乎总是比子问题规模不等的做法要好。
一个分治法将规模为n的问题分成k个规模为nm的子问题去解。设分解阀值c=1,且S(P)解规模为1的问题耗费1个单位时间。再设将原问题分解为k个子问题以及用Merge将k个子问题的解合并为原问题的解需用f(n)个单位时间。用T(n)表示该分治法解规模为|P|=n的问题所需的计算时间,则有:
⎧⎩⎨⎪⎪W(n)=W(|P1|)+W(|P2|)+...+W(|Pk|)+f(n)W(c)=C
分治算法的分析技术
定义1: Fibonacci数列无穷数列1,1,2,3,5,8,13,21,34,55,……,称为Fibonacci数列。它可以递归地定义为:
⎧⎩⎨⎪⎪⎪⎪F(n)=1,F(n)=1,F(n)=F(n−1)+F(n−2),if n=0if n=1if n>1
实现:
#include <iostream>
using namespace std;
// fibonacci implement by recursive
long fibonacci_recursive(long n)
{
if (n <= 1 )
return 1;
return fibonacci_recursive(n - 1)
+ fibonacci_recursive(n - 2);
}
// fibonacci implement by loop
long fibonacci_loop(long n)
{
if (n == 0 || n == 1)
return 1;
long f1 = 1;
long f2 = 1;
long result = 0;
for (long i = 1; i < n ; ++ i) {
result = f1 + f2;
f1 = f2;
f2 = result;
}
return result;
}
int main()
{
cout << "fibonacci implement by recursive: " << endl;
for (long i = 0; i <= 20; ++ i)
cout << fibonacci_recursive(i) << " " ;
cout << endl << endl;
cout << "fibonacci implement by loop: " << endl;
for (long i = 0; i <= 20; ++ i)
cout << fibonacci_loop(i) << " " ;
cout << endl;
return 0;
}分治法所能解决的问题一般具有以下几个特征:
1) 该问题的规模缩小到一定的程度就可以容易地解决
2) 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
3) 利用该问题分解出的子问题的解可以合并为该问题的解;
4) 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
第一条特征是绝大多数问题都可以满足的,因为问题的计算复杂性一般是随着问题规模的增加而增加;
第二条特征是应用分治法的前提它也是大多数问题可以满足的,此特征反映了递归思想的应用;
第三条特征是关键,能否利用分治法完全取决于问题是否具有第三条特征,如果具备了第一条和第二条特征,而不具备第三条特征,则可以考虑用贪心法或动态规划法。
第四条特征涉及到分治法的效率,如果各子问题是不独立的则分治法要做许多不必要的工作,重复地解公共的子问题,此时虽然可用分治法,但一般用动态规划法较好。
提高分治算法的途经
从所周知,直接或间接地调用自身的算法称为递归算法。用函数自身给出定义的函数称为递归函数。它优点是结构清晰,可读性强,而且容易用数学归纳法来证明算法的正确性,因此它为设计算法、调试程序带来很大方便。可是递归算法的运行效率较低,无论是耗费的计算时间还是占用的存储空间都比非递归算法要多。解决方法:在递归算法中消除递归调用,使其转化为非递归算法。
1、采用一个用户定义的栈来模拟系统的递归调用工作栈。该方法通用性强,但本质上还是递归,只不过人工做了本来由编译器做的事情,优化效果不明显。
2、用递推来实现递归函数。
3、通过变换能将一些递归转化为尾递归,从而迭代求出结果。
后两种方法在时空复杂度上均有较大改善,但其适用范围有限。
大整数的乘法:请设计一个有效的算法,可以进行两个n位大整数的乘法运算。设X ,Y 是两个n位二进制数,n=2k,求XY。
解:以每为乘1次作为1次基本运算,则普通乘法的时间复杂度是O(n2) .
下面考虑分治算法将X 和Y都分成相等的两段,每段n/2 位,X的上半段(高位部分)记作A,下半段(低位部分)记作B;类似地,Y的上半段(高位部分)记作C,下半段(低位部分)记作D,那么有:
X=A2n/2+B
Y=C2n/2+D
XY=AC∗2n+(AD+BC)∗2n2+BD
时间复杂度的递推方程如下:
⎧⎩⎨⎪⎪T(n)=O(1),T(n)=4T(n2)+cn,if n = 1if n > 1
W(n)=O(nlog4)=O(n2) 这个分治算法与普通乘法的时间复杂度一样。根据代数知识,不难发现:
AD+BC=(A-B)(D-C)+AC+BD
为了降低时间复杂度,必须减少乘法的次数
XY=AC∗2n+(AD+BC)∗2n2+BD
⟹XY=AC∗2n+((A−B)(D−C)+AC+BD)∗2n2+BD
细节问题:两个XY的复杂度都是O(nlog3),但考虑到A+B,C+D可能得到n+1位的结果,使问题的规模变大.于是递推方程:
⎧⎩⎨⎪⎪T(n)=O(1),T(n)=3T(n2)+cn,if n = 1if n > 1
解得:
W(n)=O(nlog3)=O(n1.59)
较大的改进.更快的方法?? 如果将大整数分成更多段,用更复杂的方式把它们组合起来,将有可能得到更优的算法。Strassen矩阵乘法.矩阵乘法问题
对于两个n*n的矩阵A,B,求其乘积.传统方法:O(n3).A和B的乘积矩阵C中的元素C[i,j].若依此定义来计算A和B的乘积矩阵C,则每计算C的一个元素C[i][j],需要做n次乘法和n-1次加法。因此,算出矩阵C的个元素所需的计算时间为O(n3)
算法复杂度分析
⎧⎩⎨⎪⎪W(n)=8W(n2)+cn2W(1)=1
W(n)=O(nlog8)=O(n3)这个分治算法与普通乘法的时间复杂度一样.
为了降低时间复杂度,必须减少乘法的次数。
算法复杂度分析
⎧⎩⎨⎪⎪W(n)=7W(n2)+18(n2)2W(1)=1
由主定理得:
W(n)=O(nlog27)=O(n2.8075) 较大的改进
更快的方法??
Hopcroft和Kerr已经证明(1971),计算2个2×2矩阵的乘积,7次乘法是必要的。因此,要想进一步改进矩阵乘法的时间复杂性,就不能再基于计算2×2矩阵的7次乘法这样的方法了。或许应当研究3×3或5×5矩阵的更好算法。
在Strassen之后又有许多算法改进了矩阵乘法的计算时间复杂性。目前最好的计算时间上界是 O(n^2.376)
是否能找到O(n^2)的算法?
伪码如下
Strassen (N,MatrixA,MatrixB,MatrixResult) //splitting input Matrixes, into 4 submatrices each. for i <-0 to N/2 for j <-0 to N/2 A11[i][j] <- MatrixA[i][j]; //a矩阵块 A12[i][j] <- MatrixA[i][j+N/2];//b矩阵块 A21[i][j] <- MatrixA[i+N/2][j]; //c矩阵块 A22[i][j] <- MatrixA[i+N/2][j+N/2];//d矩阵块 B11[i][j] <- MatrixB[i][j]; //e 矩阵块 B12[i][j] <- MatrixB[i][j+N/2]; //f 矩阵块 B21[i][j] <- MatrixB[i+N/2][j]; //g 矩阵块 B22[i][j] <- MatrixB[i+N/2][j+N/2];//h矩阵块 //here we calculate M1..M7 matrices . //递归求M1 HalfSize <- N/2 AResult <- A11+A22 BResult <- B11+B22 Strassen( HalfSize, AResult, BResult, M1 ); //M1=(A11+A22)*(B11+B22) p5=(a+d)*(e+h) //递归求M2 AResult <- A21+A22 Strassen(HalfSize, AResult, B11, M2); //M2=(A21+A22)B11 p3=(c+d)*e //递归求M3 BResult <- B12 - B22 Strassen(HalfSize, A11, BResult, M3); //M3=A11(B12-B22) p1=a*(f-h) //递归求M4 BResult <- B21 - B11 Strassen(HalfSize, A22, BResult, M4); //M4=A22(B21-B11) p4=d*(g-e) //递归求M5 AResult <- A11+A12 Strassen(HalfSize, AResult, B22, M5); //M5=(A11+A12)B22 p2=(a+b)*h //递归求M6 AResult <- A21-A11 BResult <- B11+B12 Strassen( HalfSize, AResult, BResult, M6); //M6=(A21-A11)(B11+B12) p7=(c-a)(e+f) //递归求M7 AResult <- A12-A22 BResult <- B21+B22 Strassen(HalfSize, AResult, BResult, M7); //M7=(A12-A22)(B21+B22) p6=(b-d)*(g+h) //计算结果子矩阵 C11 <- M1 + M4 - M5 + M7; C12 <- M3 + M5; C21 <- M2 + M4; C22 <- M1 + M3 - M2 + M6; //at this point , we have calculated the c11..c22 matrices, and now we are going to //put them together and make a unit matrix which would describe our resulting Matrix. for i<-0 to N/2 for j<-0 to N/2 MatrixResult[i][j]<-C11[i][j]; MatrixResult[i][j+N/2]<-C12[i][j]; MatrixResult[i +N/2][j]<-C21[i][j]; MatrixResult[i +N/2][j+N/2]<-C22[i][j];
完成测试代码
Strassen.h
#ifndef STRASSEN_HH
#define STRASSEN_HH
template<typename T>
class Strassen_class{
public:
void ADD(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize );
void SUB(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize );
void MUL( T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize );//朴素算法实现
void FillMatrix( T** MatrixA, T** MatrixB, int length);//A,B矩阵赋值
void PrintMatrix(T **MatrixA,int MatrixSize);//打印矩阵
void Strassen(int N, T **MatrixA, T **MatrixB, T **MatrixC);//Strassen算法实现
};
template<typename T>
void Strassen_class<T>::ADD(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize )
{
for ( int i = 0; i < MatrixSize; i++)
{
for ( int j = 0; j < MatrixSize; j++)
{
MatrixResult[i][j] = MatrixA[i][j] + MatrixB[i][j];
}
}
}
template<typename T>
void Strassen_class<T>::SUB(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize )
{
for ( int i = 0; i < MatrixSize; i++)
{
for ( int j = 0; j < MatrixSize; j++)
{
MatrixResult[i][j] = MatrixA[i][j] - MatrixB[i][j];
}
}
}
template<typename T>
void Strassen_class<T>::MUL( T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize )
{
for (int i=0;i<MatrixSize ;i++)
{
for (int j=0;j<MatrixSize ;j++)
{
MatrixResult[i][j]=0;
for (int k=0;k<MatrixSize ;k++)
{
MatrixResult[i][j]=MatrixResult[i][j]+MatrixA[i][k]*MatrixB[k][j];
}
}
}
}
/*
*c++使用二维数组,申请动态内存方法
*申请
*int **A;
*A = new int *[desired_array_row];
*for ( int i = 0; i < desired_array_row; i++)
* A[i] = new int [desired_column_size];
*释放
*for ( int i = 0; i < your_array_row; i++)
* delete [] A[i];
*delete[] A;
*/
template<typename T>
void Strassen_class<T>::Strassen(int N, T **MatrixA, T **MatrixB, T **MatrixC)
{
int HalfSize = N/2;
int newSize = N/2;
if ( N <= 64 ) //分治门槛,小于这个值时不再进行递归计算,而是采用常规矩阵计算方法
{
MUL(MatrixA,MatrixB,MatrixC,N);
}
else
{
T** A11;
T** A12;
T** A21;
T** A22;
T** B11;
T** B12;
T** B21;
T** B22;
T** C11;
T** C12;
T** C21;
T** C22;
T** M1;
T** M2;
T** M3;
T** M4;
T** M5;
T** M6;
T** M7;
T** AResult;
T** BResult;
//making a 1 diminsional pointer based array.
A11 = new T *[newSize];
A12 = new T *[newSize];
A21 = new T *[newSize];
A22 = new T *[newSize];
B11 = new T *[newSize];
B12 = new T *[newSize];
B21 = new T *[newSize];
B22 = new T *[newSize];
C11 = new T *[newSize];
C12 = new T *[newSize];
C21 = new T *[newSize];
C22 = new T *[newSize];
M1 = new T *[newSize];
M2 = new T *[newSize];
M3 = new T *[newSize];
M4 = new T *[newSize];
M5 = new T *[newSize];
M6 = new T *[newSize];
M7 = new T *[newSize];
AResult = new T *[newSize];
BResult = new T *[newSize];
int newLength = newSize;
//making that 1 diminsional pointer based array , a 2D pointer based array
for ( int i = 0; i < newSize; i++)
{
A11[i] = new T[newLength];
A12[i] = new T[newLength];
A21[i] = new T[newLength];
A22[i] = new T[newLength];
B11[i] = new T[newLength];
B12[i] = new T[newLength];
B21[i] = new T[newLength];
B22[i] = new T[newLength];
C11[i] = new T[newLength];
C12[i] = new T[newLength];
C21[i] = new T[newLength];
C22[i] = new T[newLength];
M1[i] = new T[newLength];
M2[i] = new T[newLength];
M3[i] = new T[newLength];
M4[i] = new T[newLength];
M5[i] = new T[newLength];
M6[i] = new T[newLength];
M7[i] = new T[newLength];
AResult[i] = new T[newLength];
BResult[i] = new T[newLength];
}
//splitting input Matrixes, into 4 submatrices each.
for (int i = 0; i < N / 2; i++)
{
for (int j = 0; j < N / 2; j++)
{
A11[i][j] = MatrixA[i][j];
A12[i][j] = MatrixA[i][j + N / 2];
A21[i][j] = MatrixA[i + N / 2][j];
A22[i][j] = MatrixA[i + N / 2][j + N / 2];
B11[i][j] = MatrixB[i][j];
B12[i][j] = MatrixB[i][j + N / 2];
B21[i][j] = MatrixB[i + N / 2][j];
B22[i][j] = MatrixB[i + N / 2][j + N / 2];
}
}
//here we calculate M1..M7 matrices .
//M1[][]
ADD( A11,A22,AResult, HalfSize);
ADD( B11,B22,BResult, HalfSize); //p5=(a+d)*(e+h)
Strassen( HalfSize, AResult, BResult, M1 ); //now that we need to multiply
//this , we use the strassen itself.
//M2[][]
ADD( A21,A22,AResult, HalfSize); //M2=(A21+A22)B11,p3=(c+d)*e
Strassen(HalfSize, AResult, B11, M2); //Mul(AResult,B11,M2);
//M3[][]
SUB( B12,B22,BResult, HalfSize); //M3=A11(B12-B22),p1=a*(f-h)
Strassen(HalfSize, A11, BResult, M3); //Mul(A11,BResult,M3);
//M4[][]
SUB( B21, B11, BResult, HalfSize); //M4=A22(B21-B11),p4=d*(g-e)
Strassen(HalfSize, A22, BResult, M4); //Mul(A22,BResult,M4);
//M5[][]
ADD( A11, A12, AResult, HalfSize); //M5=(A11+A12)B22 ,p2=(a+b)*h
Strassen(HalfSize, AResult, B22, M5); //Mul(AResult,B22,M5);
//M6[][]
SUB( A21, A11, AResult, HalfSize);
ADD( B11, B12, BResult, HalfSize); //M6=(A21-A11)(B11+B12),p7=(c-a)(e+f)
Strassen( HalfSize, AResult, BResult, M6); //Mul(AResult,BResult,M6);
//M7[][]
SUB(A12, A22, AResult, HalfSize);
ADD(B21, B22, BResult, HalfSize); //M7=(A12-A22)(B21+B22),p6=(b-d)*(g+h)
Strassen(HalfSize, AResult, BResult, M7); //Mul(AResult,BResult,M7);
//C11 = M1 + M4 - M5 + M7;
ADD( M1, M4, AResult, HalfSize);
SUB( M7, M5, BResult, HalfSize);
ADD( AResult, BResult, C11, HalfSize);
//C12 = M3 + M5;
ADD( M3, M5, C12, HalfSize);
//C21 = M2 + M4;
ADD( M2, M4, C21, HalfSize);
//C22 = M1 + M3 - M2 + M6;
ADD( M1, M3, AResult, HalfSize);
SUB( M6, M2, BResult, HalfSize);
ADD( AResult, BResult, C22, HalfSize);
//at this point , we have calculated the c11..c22 matrices, and now we are going to
//put them together and make a unit matrix which would describe our resulting Matrix.
//组合小矩阵到一个大矩阵
for (int i = 0; i < N/2 ; i++)
{
for (int j = 0 ; j < N/2 ; j++)
{
MatrixC[i][j] = C11[i][j];
MatrixC[i][j + N / 2] = C12[i][j];
MatrixC[i + N / 2][j] = C21[i][j];
MatrixC[i + N / 2][j + N / 2] = C22[i][j];
}
}
// 释放矩阵内存空间
for (int i = 0; i < newLength; i++)
{
delete[] A11[i];delete[] A12[i];delete[] A21[i];
delete[] A22[i];
delete[] B11[i];delete[] B12[i];delete[] B21[i];
delete[] B22[i];
delete[] C11[i];delete[] C12[i];delete[] C21[i];
delete[] C22[i];
delete[] M1[i];delete[] M2[i];delete[] M3[i];delete[] M4[i];
delete[] M5[i];delete[] M6[i];delete[] M7[i];
delete[] AResult[i];delete[] BResult[i] ;
}
delete[] A11;delete[] A12;delete[] A21;delete[] A22;
delete[] B11;delete[] B12;delete[] B21;delete[] B22;
delete[] C11;delete[] C12;delete[] C21;delete[] C22;
delete[] M1;delete[] M2;delete[] M3;delete[] M4;delete[] M5;
delete[] M6;delete[] M7;
delete[] AResult;
delete[] BResult ;
}//end of else
}
template<typename T>
void Strassen_class<T>::FillMatrix( T** MatrixA, T** MatrixB, int length)
{
for(int row = 0; row<length; row++)
{
for(int column = 0; column<length; column++)
{
MatrixB[row][column] = (MatrixA[row][column] = rand() %5);
//matrix2[row][column] = rand() % 2;//ba hazfe in khat 50% afzayeshe soorat khahim dasht
}
}
}
template<typename T>
void Strassen_class<T>::PrintMatrix(T **MatrixA,int MatrixSize)
{
cout<<endl;
for(int row = 0; row<MatrixSize; row++)
{
for(int column = 0; column<MatrixSize; column++)
{
cout<<MatrixA[row][column]<<"\t";
if ((column+1)%((MatrixSize)) == 0)
cout<<endl;
}
}
cout<<endl;
}
#endif //Strassen.hStrassen.cpp
#include <iostream>
#include <ctime>
#include <Windows.h>
using namespace std;
#include "Strassen.h"
int main()
{
Strassen_class<int> stra;//定义Strassen_class类对象
int MatrixSize = 0;
int** MatrixA; //存放矩阵A
int** MatrixB; //存放矩阵B
int** MatrixC; //存放结果矩阵
clock_t startTime_For_Normal_Multipilication ;
clock_t endTime_For_Normal_Multipilication ;
clock_t startTime_For_Strassen ;
clock_t endTime_For_Strassen ;
srand(time(0));
cout<<"\n请输入矩阵大小(必须是2的幂指数值(例如:32,64,512,..): ";
cin>>MatrixSize;
int N = MatrixSize;//for readiblity.
//申请内存
MatrixA = new int *[MatrixSize];
MatrixB = new int *[MatrixSize];
MatrixC = new int *[MatrixSize];
for (int i = 0; i < MatrixSize; i++)
{
MatrixA[i] = new int [MatrixSize];
MatrixB[i] = new int [MatrixSize];
MatrixC[i] = new int [MatrixSize];
}
stra.FillMatrix(MatrixA,MatrixB,MatrixSize); //矩阵赋值
//*******************conventional multiplication test
cout<<"朴素矩阵算法开始时钟: "<< (startTime_For_Normal_Multipilication = clock());
stra.MUL(MatrixA,MatrixB,MatrixC,MatrixSize);//朴素矩阵相乘算法 T(n) = O(n^3)
cout<<"\n朴素矩阵算法结束时钟: "<< (endTime_For_Normal_Multipilication = clock());
cout<<"\n矩阵运算结果... \n";
stra.PrintMatrix(MatrixC,MatrixSize);
//*******************Strassen multiplication test
cout<<"\nStrassen算法开始时钟: "<< (startTime_For_Strassen = clock());
stra.Strassen( N, MatrixA, MatrixB, MatrixC ); //strassen矩阵相乘算法
cout<<"\nStrassen算法结束时钟: "<<(endTime_For_Strassen = clock());
cout<<"\n矩阵运算结果... \n";
stra.PrintMatrix(MatrixC,MatrixSize);
cout<<"矩阵大小 "<<MatrixSize;
cout<<"\n朴素矩阵算法: ";
cout<<(endTime_For_Normal_Multipilication-startTime_For_Normal_Multipilication);
cout<<" Clocks.."<<(endTime_For_Normal_Multipilication- \\
startTime_For_Normal_Multipilication)/CLOCKS_PER_SEC<<" Sec";
cout<<"\nStrassen算法:"<<(endTime_For_Strassen-startTime_For_Strassen)<<" Clocks.."
cout<<(endTime_For_Strassen-startTime_For_Strassen)/CLOCKS_PER_SEC<<" Sec\n";
system("Pause");
return 0;
}典型实例
归并排序
将待排序序列R[0…n-1]看成是n个长度为1的有序序列,将相邻的有序表成对归并,得到n/2个长度为2的有序表;将这些有序序列再次归并,得到n/4个长度为4的有序序列;如此反复进行下去,最后得到一个长度为n的有序序列。归并排序其实要做两件事:“分解”——将序列每次折半划分。“合并”——将划分后的序列段两两合并后排序。实现
#include <iostream>
#include <vector>
#include <iterator>
#include <algorithm>
#include <cstdio>
using namespace std;
template <class T>
void merge(vector<T>& arr,int start ,int middle,int end)
{
int n1 = middle - start + 1;
int n2 = end - middle;
vector<T> left(n1);
vector<T> right(n2);
int i,j,k;
for (i = 0;i < n1; ++ i)
left[i] = arr[start + i];
for (j = 0;j < n2; ++ j)
right[j] = arr[middle + j + 1];
i = j = 0;
k = start;
while (i < n1 && j < n2) {
if (left[i] < right[j])
arr[k ++] = left[i ++];
else
arr[k ++] = right[j ++];
}
while (i < n1)
arr[k ++] = left[i ++ ];
while (j < n2)
arr[k ++] = right[j ++];
}
template <class T>
void sort(vector<T>& arr,int start,int end)
{
// getchar();
if (start < end)
{
int middle = (start + end) / 2;
sort(arr,start,middle);
sort(arr,middle + 1,end);
merge(arr,start,middle,end);
}
}
int main()
{
const int length = 20;
vector<int> arr(length);
for (size_t i = 0;i < arr.size(); ++ i)
arr[i] = i;
random_shuffle(arr.begin(),arr.end());
copy(arr.begin(),arr.end(),ostream_iterator<int>(cout, " "));
cout << endl;
sort(arr,0,length - 1);
copy(arr.begin(),arr.end(),ostream_iterator<int>(cout, " "));
cout << endl;
return 0;
}整数划分问题
将正整数n表示成一系列正整数之和:n=n1+n2+…+nk,其中n1≥n2≥…≥nk≥1,k≥1。正整数n的这种表示称为正整数n的划分。正整数n的不同划分个数称为正整数n的划分数,记作p(n)。例如:正整数6有如下11种不同的划分,所以p(6) = 11:
6; 5+1; 4+2,4+1+1; 3+3,3+2+1,3+1+1+1; 2+2+2,2+2+1+1,2+1+1+1+1; 1+1+1+1+1+1。
前面的几个例子中,问题本身都具有比较明显的递归关系,因而容易用递归函数直接求解。
在本例中,如果设p(n)为正整数n的划分数,则难以找到递归关系,因此考虑增加一个自变量:在正整数n的所有不同划分中,将最大加数n1不大于m的划分个数记作q(n,m)。可以建立q(n,m)的如下递归关系。
(1) q(n,1)=1,n >= 1;当最大加数n1不大于1时,任何正整数n只有一种划分形式,即n = 1 + 1 + 1 + … +1.
(2) q(n,m) = q(n,n),m >= n; 最大加数n1实际上不能大于n。因此,q(1,m)=1。
(3) q(n,n)=1 + q(n,n-1); 正整数n的划分由n1=n的划分和n1 ≤ n-1的划分组成。
(4) q(n,m)=q(n,m-1)+q(n-m,m),n > m >1;正整数n的最大加数n1不大于m的划分由 n1 = m的划分和n1 ≤ m-1 的划分组成。
前面的一个例子中,问题本身都具有比较明显的递归关系,因而容易用递归函数直接求解。
在本例中,如果设p(n)为正整数n的划分数,则难以找到递归关系,因此考虑增加一个自变量:将最大加数n1不大于m的划分个数记作q(n,m)。可以建立q(n,m)的如下递归关系。
⎧⎩⎨⎪⎪⎪⎪⎪⎪q(n,m)=1,q(n,m)=q(n,m),q(n,m)=1+q(n,n−1),q(n,m)=q(n,m−1)+q(n−m,m),if n=1,m=1if n=1,m=1if n=mif n>m>1
正整数n的划分数p(n)=q(n,n)。
实现:
#include <iostream>
using namespace std;
//
int __int_partition(int n,int m)
{
if (n < 1 || m < 1)
return 0;
if (n == 1 || m == 1)
return 1;
if (n < m)
return __int_partition(n,n);
if (n == m)
return __int_partition(n,m - 1) + 1;
return __int_partition(n,m - 1) + __int_partition(n - m,m);
}
int integer_partition(int n)
{
return __int_partition(n,n);
}
int main()
{
for (int i = 1; i < 7; ++ i) {
cout << "integer_patition("
<< i
<< ") = "
<< integer_partition(i)
<< endl;
}
return 0;
}阶乘函数
阶乘函数可递归地定义为:⎧⎩⎨⎪⎪n!=1,n!=n(n−1)!,if n=0 (边界条件)if n>0 (递归方程)
边界条件与递归方程是递归函数的二个要素,递归函数只有具备了这两个要素,才能在有限次计算后得出结果。
实现:
#include <iostream>
using namespace std;
// factorial implement by recursive
long factorial_recursive(long n)
{
if (n == 0)
return 1;
return n * factorial_recursive(n-1);
}
// factorial implement by loop
long factorial_loop(long n)
{
long result = 1;
for (int i = n; i > 0; -- i)
result *= i;
return result;
}
int main()
{
for (int i = 0; i < 10; i ++ ) {
cout << i << "!" << " = "
<< factorial_recursive(i)
<< ","
<< factorial_loop(i)
<< endl;
}
return 0;
}排列问题
设计一个递归算法生成n个元素{r1,r2,…,rn}的全排列。设R={r1,r2,…,rn}是要进行排列的n个元素,Ri=R−{ri}。集合X中元素的全排列记为perm(X)。(ri)perm(X)表示在全排列perm(X)的每一个排列前加上前缀得到的排列。R的全排列可归纳定义如下:当n=1时,perm(R)=(r),其中r是集合R中唯一的元素;
当n>1时,perm(R)由(r1)perm(R1),(r2)perm(R2),…,(rn)perm(Rn)构成。
#include <iostream>
#include <vector>
#include <iterator>
using namespace std;
/* 使用递归实现
* 递归产生所有前缀是list[0:k-1],且后缀是list[k,m]的全排列的所有排列.调用算法perm(list,0,n-1)则产生list[0:n-1]的全排列
*/
template <class T>
void perm_recursion(T list[],int k,int m)
{
// 产生list[k:m]的所有排列
if (k == m) {
for (int i = 0; i <= m; i ++)
cout << list[i] << " ";
cout << endl;
}
else {
// 还有多个元素,递归产生排列
for (int i = k; i <= m; ++ i) {
swap(list[k],list[i]);
perm_recursion(list,k+1,m);
swap(list[k],list[i]);
}
}
}
// 非递归实现(可参照STL next_permutation源码)
template <class T>
void perm_loop(T list[],int len)
{
int i,j;
vector<int> v_temp(len);
// 初始排列
for(i = 0; i < len ; i ++)
v_temp[i] = i;
while (true) {
for (i = 0; i < len; i ++ )
cout << list[v_temp[i]] << " ";
cout << endl;
// 从后向前查找,看有没有后面的数大于前面的数的情况,若有则停在后一个数的位置。
for(i = len - 1;i > 0 && v_temp[i] < v_temp[i-1] ; i--);
if (i == 0)
break;
// 从后查到i,查找大于 v_temp[i-1]的最小的数,记入j
for(j = len - 1 ; j > i && v_temp[j] < v_temp[i-1] ; j--);
// 交换 v_temp[i-1] 和 v_temp[j]
swap(v_temp[i-1],v_temp[j]);
// 倒置v_temp[i]到v_temp[n-1]
for(i = i,j = len - 1 ; i < j;i ++,j --) {
swap(v_temp[i],v_temp[j]);
}
}
}
int main()
{
int list[] = {0,1,2};
cout << "permutation implement by recursion: " << endl;
perm_recursion(list,0,2);
cout << endl;
cout << "permutation implement by loop: " << endl;
perm_loop(list,3);
cout << endl;
return 0;
}Hanoi塔问题
设a,b,c是3个塔座。开始时,在塔座a上有一叠共n个圆盘,这些圆盘自下而上,由大到小地叠在一起。各圆盘从小到大编号为1,2,…,n,现要求将塔座a上的这一叠圆盘移到塔座b上,并仍按同样顺序叠置。在移动圆盘时应遵守以下移动规则:规则1:每次只能移动1个圆盘;
规则2:任何时刻都不允许将较大的圆盘压在较小的圆盘之上;
规则3:在满足移动规则1和2的前提下,可将圆盘移至a,b,c中任一塔座上。
#include <iostream>
using namespace std;
void __move(char t1,char t2){
cout << t1 << " -> " << t2 << endl;
}
// 把n个圆盘,从t1塔移至t2塔通过t3塔
void hanoi(int n,char t1,char t2,char t3){
if (n > 0) {
hanoi(n-1,t1,t3,t2);
__move(t1,t2);
hanoi(n-1,t3,t2,t1);
}
}
int main(){
cout << "hanoi(1,'a','b','c'): " << endl;
hanoi(1,'a','b','c');
cout << endl;
cout << "hanoi(1,'a','b','c'): " << endl;
hanoi(2,'a','b','c');
cout << endl;
cout << "hanoi(3,'a','b','c'): " << endl;
hanoi(3,'a','b','c');
cout << endl;
return 0;
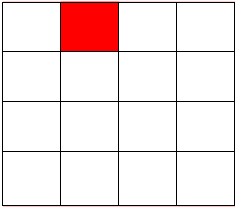
}棋盘覆盖
在一个2k×2k 个方格组成的棋盘中,恰有一个方格与其它方格不同,称该方格为一特殊方格,且称该棋盘为一特殊棋盘。在棋盘覆盖问题中,要用图示的4种不同形态的L型骨牌覆盖给定的特殊棋盘上除特殊方格以外的所有方格,且任何2个L型骨牌不得重叠覆盖。棋盘示例(k = 2)和四种L型骨牌示例:分析
当k>0时,将2k×2k棋盘分割为4个2(k−1)×2(k−1)子棋盘所示。
特殊方格必位于4个较小子棋盘之一中,其余3个子棋盘中无特殊方格。为了将这3个无特殊方格的子棋盘转化为特殊棋盘,可以用一个L型骨牌覆盖这3个较小棋盘的会合处,从而将原问题转化为4个较小规模的棋盘覆盖问题。递归地使用这种分割,直至棋盘简化为棋盘1×1。
算法复杂度
⎧⎩⎨⎪⎪T(k)=O(1),T(k)=4T(k−1)+O(1),if k=0 if k>0
总共要4k−13张牌.T(n)=O(4k)渐近意义下的最优算法.
实现
#include <iostream>
#include <vector>
#include <cmath>
#include <iterator>
using namespace std;
void __chessboard_cover(vector<vector<int> >& cheb,
int tx,int ty,
int dx,int dy,
int size,
int& tile);
/* 棋盘覆盖主函数
* cheb: 棋盘数组 dx: 特殊方格的横坐标 dy: 特殊方格的纵坐标
*/
void chessboard_cover(vector<vector<int> >& cheb,int dx,int dy)
{
int tile = 1;
__chessboard_cover(cheb,0,0,dx,dy,cheb.size(),tile);
}
/* 棋盘覆盖辅助函数
* cheb: 棋盘数组 tx: 起始横坐标 ty: 起始纵坐标
* dx: 特殊方格的横坐标 dy: 特殊方格的横坐标 size: 棋盘大小 tile: 骨牌编号
*/
void __chessboard_cover(vector<vector<int> >& cheb,
int tx,int ty,
int dx,int dy,
int size,
int& tile)
{
if (size == 1)
return ;
int t = tile ++ ; // L骨牌号
int s = size / 2; // 分割棋盘
// 覆盖左上角子棋盘
if (dx < tx + s && dy < ty + s) {
// 特殊方格在此子棋盘中
__chessboard_cover(cheb,tx,ty,dx,dy,s,tile);
}
else {
// 此棋盘中无特殊方格,用t号骨牌覆盖下角方格
cheb[tx + s - 1][ty + s - 1] = t;
// 覆盖其余方格
__chessboard_cover(cheb,tx,ty,tx + s - 1, ty + s - 1,s,tile);
}
// 覆盖右上角子棋盘
if (dx >= tx + s && dy < ty + s) {
// 特殊方格在此棋盘中
__chessboard_cover(cheb,tx + s,ty,dx,dy,s,tile);
}
else {
// 用t号L型骨牌覆盖左下角
cheb[tx + s][ty + s - 1] = t;
__chessboard_cover(cheb,tx + s,ty,tx + s,ty + s - 1,s,tile);
}
// 覆盖左下角子棋盘
if (dx < tx + s && dy >= ty + s) {
// 特殊方格在此棋盘中
__chessboard_cover(cheb,tx,ty + s,dx,dy,s,tile);
}
else {
// 用t号L型骨牌覆盖右上角
cheb[tx + s - 1][ty + s] = t;
__chessboard_cover(cheb,tx,ty + s,tx + s - 1,ty + s,s,tile);
}
// 覆盖右下角子棋盘
if (dx >= tx + s && dy >= ty + s) {
// 特殊方格在此棋盘中
__chessboard_cover(cheb,tx + s,ty + s,dx,dy,s,tile);
}
else {
// 用t号L型骨牌覆盖左上角
cheb[tx + s][ty + s] = t;
__chessboard_cover(cheb,tx + s,ty + s,tx + s,ty + s,s,tile);
}
}
int main()
{
int k = 2;
int size = pow (2,k);
vector<vector<int> > cheb(size);
for (size_t i= 0 ;i < cheb.size(); ++i) {
cheb[i].resize(size);
}
for (int i = 0; i < size; ++ i) {
for (int j = 0;j < size; ++ j) {
int dx = i;
int dy = j;
cout << "dx = " << dx << " , dy = " << dy << endl;
cheb[dx][dy] = 0;
chessboard_cover(cheb,dx,dy);
for (size_t i = 0;i < cheb.size(); ++ i) {
copy(cheb[i].begin(),cheb[i].end(),ostream_iterator<int>(cout," "));
cout << endl;
}
cout << endl;
}
}
return 0;
}循环赛日程表
题目表述:设有n=2k 个运动员要进行网球循环赛,设计一个满足以下要求的比赛日程表:
(1)每个选手必须与其他n−1个选手各赛一次;
(2)每个选手一天只能赛一次;
(3)循环赛一共进行n−1天。
按分治策略,将所有的选手分为两半,n个选手的比赛日程表就可以通过为n/2个选手设计的比赛日程表来决定。递归地用对选手进行分割,直到只剩下2个选手时,比赛日程表的制定就变得很简单。这时只要让这2个选手进行比赛就可以了。
实现
#include <iostream>
#include <vector>
#include <cmath>
#include <iterator>
#include <iomanip>
using namespace std;
void __table(vector<vector<int> >& arr,int start,int end);
void round_match_table(vector<vector<int> >& arr)
{
int count = arr.size();
for (int i = 0;i < count;++ i) {
arr[0][i] = i + 1;
}
__table(arr,0,count-1);
}
void __table(vector<vector<int> >& arr,int start,int end)
{
if (end - start + 1 == 2) {
arr[1][start] = arr[0][end];
arr[1][end] = arr[0][start];
return ;
}
int half = (end - start + 1) / 2;
// 左上角
__table(arr,start,start + half -1 );
// 右上角
__table(arr,start + half,end);
// 左下角
for (int i = 0;i < half; ++ i) {
for (int j = start; j <= end; ++ j) {
arr[i + half][j-half] = arr[i][j];
}
}
// 右下角(其实左下角和右下角可以在上一个循环中实现的,
// 但是为了算法结构清晰,因此分为两个循环)
for (int i = 0;i < half; ++ i) {
for (int j = start; j < end; ++j) {
arr[i + half][j + half] = arr[i][j];
}
}
}
int main()
{
int k = 4;
int size = pow(2,k);
vector<vector<int> > arr(size);
for (int i = 0; i < size; ++ i) {
arr[i].resize(size);
}
round_match_table(arr);
for (int i = 0;i < size; ++ i) {
for (int j = 0;j < size; ++ j) {
cout << std::setw(3) << arr[i][j];
}
cout << endl;
}
return 0;
}线性时间选择
给定线性序集中n个元素和一个整数k,1≤k≤n,要求找出这n个元素中第k小的元素。伪码描述如下:// 在数组a的p到r区间内找到第k小的元素
template<class Type>
Type RandomizedSelect(Type a[],int p,int r,int k){
if (p == r)
return a[p]; // 如果p,r相等,第n小都是a[p]
// 数组a[p:r]被随机分成两个部分,a[p:i]和a[i+1:r],
// 使得a[p:i]中的元素都小于a[i+1:r]中的元素。
int i = RandomizedPartition(a,p,r);
j = i - p + 1;
if (k <= j)
return RandomizedSelect(a,p,i,k);
else
return RandomizedSelect(a,i+1,r,k-j);
}在最坏情况下,算法randomizedSelect需要O(n2)计算时间(在找最小元素的时候,总在最大元素处划分),但可以证明,算法randomizedSelect可以在O(n)平均时间内找出n个输入元素中的第k小元素。
如果能在线性时间内找到一个划分基准,使得按这个基准所划分出的2个子数组的长度都至多为原数组长度的ε倍(0<ε<1是某个正常数),那么就可以在最坏情况下用O(n)时间完成选择任务。
例如,若ε=910,算法递归调用所产生的子数组的长度至少缩短110。所以,在最坏情况下,算法所需的计算时间T(n)满足递归式T(n)≤T(9n10)+O(n) 。由此可得T(n)=O(n)。
步骤
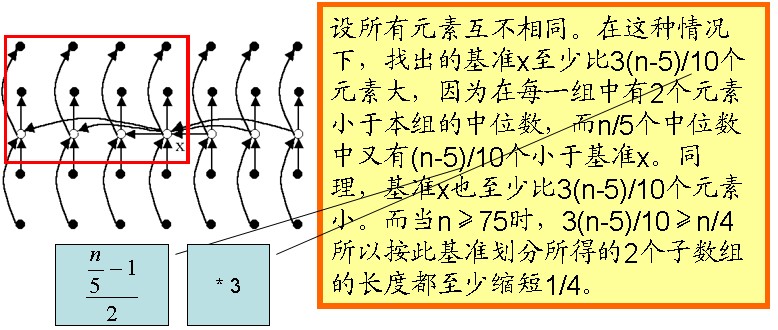
第一步,将n个输入元素划分成én/5ù个组,每组5个元素,只可能有一个组不是5个元素。用任意一种排序算法,将每组中的元素排好序,并取出每组的中位数,共én/5ù个。
第二步,递归调用select来找出这én/5ù个元素的中位数。如果én/5ù是偶数,就找它的2个中位数中较大的一个。以这个元素作为划分基准。
分析
伪码描述如下:
Type Select(Type a[], int p, int r, int k)
{
if (r - p < 75) {
// 问题的规模足够小,用某个简单排序算法对数组a[p:r]排序;
return a[p + k - 1];
}
for (int i = 0; i <= ( r - p - 4 ) / 5 ; i ++ ) {
将a[p + 5 * i]至a[p + 5 * i + 4]的第3小元素与a[p+i]交换位置;
}
// 找中位数的中位数,r - p - 4即上面所说的n - 5
Type x = Select(a, p, p + (r - p - 4 ) / 5, (r - p - 4) / 10);
// 数据n根据x划分开来
int i = Partition(a,p,r,x);
j = i - p + 1;
if (k <= j)
return Select(a,p,i,k);
else
return Select(a,i+1,r,k-j);
}算法复杂度分析
⎧⎩⎨⎪⎪T(n)≤C1,T(n)≤C2n+T(n5)+T(3n4),n <75n >= 75
解得时间复杂度是W(n)=O(n)。上述算法将每一组的大小定为5,并选取75作为是否作递归调用的分界点。这2点保证了T(n)的递归式中2个自变量之和n5+3n4=19n20=εn,0<ε<1。这是使W(n)=O(n)的关键之处。当然,除了5和75之外,还有其他选择。
实现
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
using namespace std;
/* 线性时间查找
* arr: 数据存储数组 start:开始查找点 end: 结束查找点 n: 查找第n小(n = 1,2,3,...,end-start+1)
*/
template <class T>
T linear_time_select(vector<T>& arr,int start,int end,int n)
{
if (end - start < 75) {
sort (arr.begin() + start,arr.begin() + end + 1);
return arr[start + n - 1];
}
for (int i = 0;i < (end - start - 4) / 5; ++ i) {
sort (arr.begin() + start + 5 * i,arr.begin() + start + 5 * i + 5);
swap (*(arr.begin() + start + 5 * i + 2),*(arr.begin() + start + i));
}
// 找到中位数的中位数
T median = linear_time_select(arr,start,start + (end-start-4)/5-1,(end-start-4)/10+1);
// 数据 arr 根据 median 划分开来
int middle = __partition_by_median(arr,start,end,median);
int distance = middle-start+1; // 中位数的位置与start的距离
if (n <= distance)
return linear_time_select(arr,start,middle,n);// 在前半截
else
return linear_time_select(arr,middle + 1,end,n - distance);// 在后半截
}
// 将arr按照值median划分开来,并返回界限的位置
template <class T>
int __partition_by_median(vector<T> &arr,int start,int end,T median)
{
while (true) {
while (true) {
if (start == end)
return start;
else if (arr[start] < median)
++ start;
else
break;
}
while (true) {
if (start == end)
return end;
else if (arr[end] > median) {
-- end;
}
else
break;
}
swap(arr[start],arr[end]);
}
}
int main()
{
vector<int> arr;
const int c = 2000;
for (int i = 0;i < c; ++ i) {
arr.push_back(i);
}
// 随机排列
random_shuffle(arr.begin(),arr.end());
for (int i = 1; i < c+1; ++ i) {
cout << "find the " << i << " element,position is "
<< linear_time_select(arr,0,c-1,i) << endl;
}
return 0;
}参考资料
Donald E.Knuth 著,苏运霖 译,《计算机程序设计艺术,第1卷基本算法》,国防工业出版社,2002年Donald E.Knuth 著,苏运霖 译,《计算机程序设计艺术,第2卷半数值算法》,国防工业出版社,2002年
Donald E.Knuth 著,苏运霖 译,《计算机程序设计艺术,第3卷排序与查找》,国防工业出版社,2002年
Thomas H. Cormen, Charles E.Leiserson, etc., Introduction to Algorithms(3rd edition), McGraw-Hill Book Company,2009
Jon Kleinberg, Ėva Tardos, Algorithm Design, Addison Wesley, 2005.
Sartaj Sahni ,《数据结构算法与应用:C++语言描述》 ,汪诗林等译,机械工业出版社,2000.
屈婉玲,刘田,张立昂,王捍贫,算法设计与分析,清华大学出版社,2011年版,2013年重印.
张铭,赵海燕,王腾蛟,《数据结构与算法实验教程》,高等教育出版社,2011年 1月
关于程序算法艺术与实践更多讨论与交流,敬请关注本博客和新浪微博songzi_tea.

相关文章推荐
- [算法Tutorial]Divide and Conquer,分治策略
- [TreeDivideAndConquer]点分治
- Delaunay Triangulation, Divide And Conquer Method
- 154. Find Minimum in Rotated Sorted Array II (Array; Divide-and-Conquer)
- Factorial Trailing Zeroes (Divide-and-Conquer)
- Divide and Conquer
- Leetcode Algorithms - Divide and Conquer:169. Majority Element
- Divide and Conquer -- Leetcode problem169: Majority Element
- LeetCode--169. Majority Element (Divide-and-Conquer)
- LeetCode—Divide and Conquer--53. Maximum Subarray
- algorithm:divide and conquer
- 327. Count of Range Sum(Divide and Conquer)
- leetcode_c++:Divide and Conquer: . Search a 2D Matrix II(240)
- the master theorem of divide-and-conquer
- divide and conquer in Date Structures and Algorithm Analysis in C
- Divide and Conquer
- 漫谈算法(四)分治算法 Divide and Conquer Algorithm
- LeetCode 215. Kth Largest Element in an Array--Divide and Conquer(分治法)
- 分治法——树的遍历(Divide and Conquer - Tree Traversal)
- Two question about Divide and Conquer