HuffmanTree----文件压缩
2016-08-20 20:39
183 查看

所谓Huffmantree又称为最优二叉树,是一种带权路径长度最短的二叉树;在Huffmantree中只有叶子节点才是有效数据节点,其他的非叶子节点是为了构造Huffmantree引入的。
一、首先要知道哈弗曼树的原理:
如果有一些结点的权值分别是0,1,2,3,4,5,6,7,8,9
构建出的Huffmantree是什么?
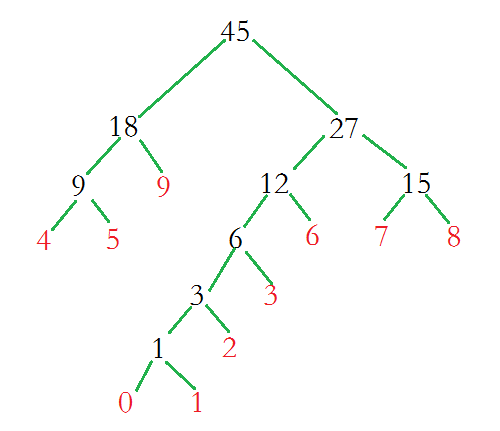

上面所构建的Huffmantree所用到的算法总结如下:
根据权值{0,1,2,3,4,5,6,7,8,9}构成10棵二叉树的集合H,其中每一棵二叉树只有一个根节点分别为{0,1,2,3,4,5,6,7,8,9};,左右子树为空;
在构建的二叉树中选择权值最最小的两棵树作为左右子树构造一棵新的二叉树,并且置新的二叉树的根节点的权值为左右子树权值之和;
在H中删掉上一步的两棵树,同时将新得到的二叉树加入H中;
重复上述步骤,知道H中只剩一棵树,而这棵树就是Huffmantree。
二、哈弗曼树的构建:
因为每次选择权值最小的两棵树构建新的树,因此使用堆来实现,自然这里需要构建最小堆;
三、文件压缩的原理:
文件压缩需要的是哈夫曼编码,对于上面的Huffmantree,怎样来进行编码呢?
从根节点开始,根节点的右支编码为1,而左支编码为0,依次递归下去,得到如下编码图:
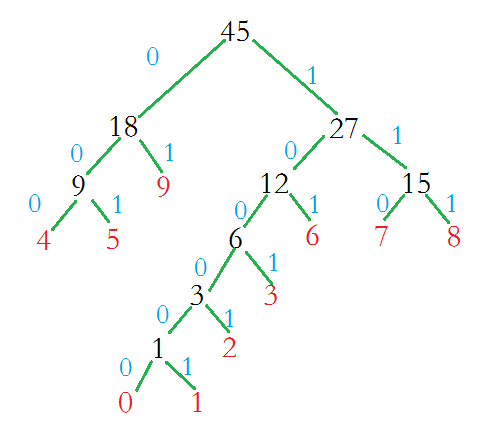

哈夫曼编码只是对叶子节点编码;而且可以发现权值越小的,它的哈夫曼编码越长,权值越大的,哈夫曼编码越短。
那如何运用到文件压缩中呢?
举一个简单的例子吧,假设有一个文件的内容是“abbcccdddd“,‘a’出现的次数是1,‘b’出现的次数是2,‘c’出现的次数是3,‘d’出现的次数是4,以各字符出现的次数构建一个哈夫曼树,并为各字符编码,结果是:
‘a’:100; ‘b’:101; ‘c’:11; ‘d’:0;
以编码的形式按照原字符的顺序写入压缩文件,就应该是这样滴:
1001011011111110000
这一个0或1代表一个二进制位,那压缩文件是多大呢?3个字节
原文件是多大呢?10个字节
这就是文件压缩的原理。
四、文件压缩的过程:
根据上面的例子,首先要统计待压缩文件中各字符出现的次数,然后构造Huffmantree,得到编码,把编码写入压缩文件,不够一个字节的就在后面补零,为了实现解压缩,需要将每个字符出现的次数写入配置文件。
五、文件解压缩的过程:
通过配置文件,构建Huffmantree得到哈弗曼编码,根据压缩文件里的编码到Huffmantree里面找,找到叶子结点,就把叶子节点的字符写入解压缩文件中。


相关文章推荐
- Java 3D(JSR184)文件压缩
- FOJ 1409 文件压缩
- 对文件压缩加密,解密解压缩,对称加密,DES算法
- 使用 apache ant 轻松实现文件压缩/解压缩
- Linux下文件压缩和解压使用详解-羽飞作品
- 3 文件压缩
- 用C++实现文件压缩(1.5)
- 多线程实现文件备份和文件压缩
- Hadoop IO 文件压缩 序列化
- ubuntu下文件压缩/解压缩命令总结
- 16、文件压缩和解压
- 文件压缩
- 文件压缩与解压
- 文件压缩
- gzip,zip,bzip2 文件压缩和归档
- php 文件压缩
- PHP中文件压缩为Zip包及专门解压Zip包的类文件
- HuffmanTree
- 文件压缩及解压缩命令(5)
- 文件压缩与解压缩(哈夫曼编码)