拆解Cluene系列(12)——创建索引生成的文件格式和内容
2016-08-19 15:09
501 查看
一个Seg生成的索引文件有如下几个:索引文件都是以seg做为文件名,只是扩展名不一样
这些索引文件可以分成如下几类:
- xxx.fnm
- xxx.fdt和xxx.fdx
- xxx.frq和xxx.prx
- xxx.tii和xxx.tis
- xxx.tvd,xxx.tvf,xxx.tvx
- xxx.f0,xxx.f1,xxx.f2…
这些文件都是二进制文件,本文不会分析每个文件的详细格式,本文会告诉你每个文件存储了那些东西,这些文件是如何关联的,以及检索时,会用到那些文件,使用文件的顺序。
在这个文件中,Field之间没有做排序。同时这个文件也决定了每个Field的编号,第一个Field是0,第二个Field是1,以此类推。在其他文件中引用到Field时,都是使用Field的编号。

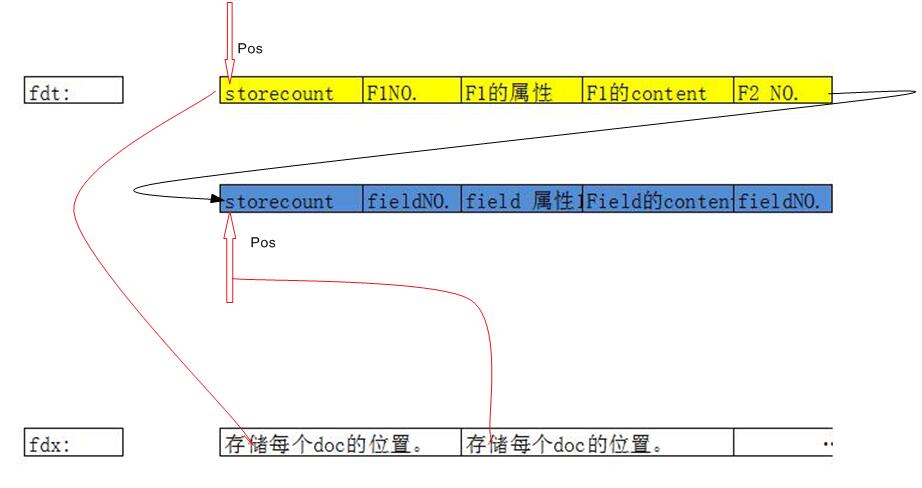
xxx.fdx是对xxx.fdt的索引。以每个doc作为界限。存储的是 每个doc在xxx.fdt的pos.
不知为什么需要把field的属性分为两部分存储在不同的文件中,感觉可以都放在fnm文件中。
tis是对tii建立的二级索引,建立索引后,肯定要包含大量的Term,为了便于查找,使用了快表技术。


检索时,首先在tis和tii定位到相应的Term, 这样就能知道有多个doc含有此Term,然后在frq中找到doc Id和词频。如果需要进一步的位置信息,可以在prx中查找。
如果查看包含词频的原始内容,可以结合fdt和fdx找到原始内容。
这些索引文件可以分成如下几类:
- xxx.fnm
- xxx.fdt和xxx.fdx
- xxx.frq和xxx.prx
- xxx.tii和xxx.tis
- xxx.tvd,xxx.tvf,xxx.tvx
- xxx.f0,xxx.f1,xxx.f2…
这些文件都是二进制文件,本文不会分析每个文件的详细格式,本文会告诉你每个文件存储了那些东西,这些文件是如何关联的,以及检索时,会用到那些文件,使用文件的顺序。
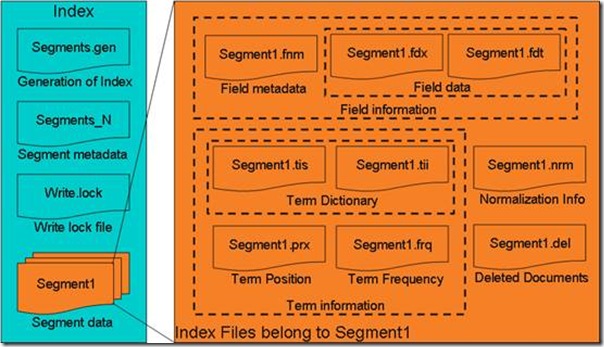
xxx.fnm
这个文件是最重要的文件,存储了Field的名字和Field的属性。 生成时先生成此文件,加载时也现价此文件,其他文件几乎都依赖于此文件。在这个文件中,Field之间没有做排序。同时这个文件也决定了每个Field的编号,第一个Field是0,第二个Field是1,以此类推。在其他文件中引用到Field时,都是使用Field的编号。
xxx.fdt和xxx.fdx
xxx.fdt主要存储了每个Field相应的内容。我们知道,每个doc可以包括多个Field,每个Field又有相应的内容,是个M*N的关系。xxx.fdx是对xxx.fdt的索引。以每个doc作为界限。存储的是 每个doc在xxx.fdt的pos.
不知为什么需要把field的属性分为两部分存储在不同的文件中,感觉可以都放在fnm文件中。
xxx.tii和xxx.tis
tii主要存储了每个term的docFreq,docFreq是指有多少个doc含有此Term。这里的FieldNo对应的Field要根据xxxx.fnm计算得知,所有的Term是按字典序排序的。tis是对tii建立的二级索引,建立索引后,肯定要包含大量的Term,为了便于查找,使用了快表技术。
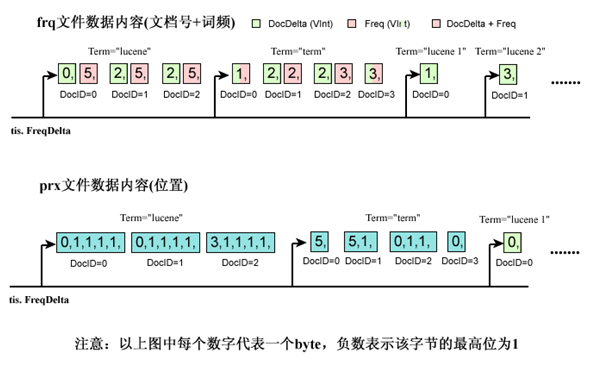
xxx.frq和xxx.prx
frq文件的数据很显然使用了差值规则和或然跟随规则,frq存储了每个Term的docId和词频。prx则存储了具体的位置信息。xxx.tvd,xxx.tvf,xxx.tvx
这三个文件也是存储Term在doc的位置信息的,没有研究过。xxx.f0,xxx.f1,xxx.f2
这些文件是用来存储Field的Norm因子,f0对应的是fnm的0号Field,其他以此类推比较简单。检索时,首先在tis和tii定位到相应的Term, 这样就能知道有多个doc含有此Term,然后在frq中找到doc Id和词频。如果需要进一步的位置信息,可以在prx中查找。
如果查看包含词频的原始内容,可以结合fdt和fdx找到原始内容。

相关文章推荐
- 将DataGrid内容生成标准的Excel格式文件
- 分享:将DataGrid内容生成标准的Excel格式文件(office2003)
- lucene4.5源码分析系列:lucene默认索引的文件格式-总述
- 拆解Cluene系列(11)——索引的合并(二)
- 拆解Cluene系列(10)——详解索引的合并(一)
- Google Android开发者文档系列-创建有内容分享特性的应用之请求共享文件
- cocoaPod的Podfile文件的创建和内容格式
- 拆解Cluene系列(9)——建立索引用到的类关系
- 在Linux上将12导联心电文件生成PDF格式文件
- SQL 文件内容存储表 创建索引
- Google Android开发者文档系列-创建有内容分享特性的应用之设置共享文件
- 【复杂网络系列】图模型语言(graph model language)gml格式文件生成代码
- C# 生成Excel文件及表格内容格式编辑 excel模板流
- 将DataGrid内容生成标准的Excel格式文件
- 把内容写入指定目录指定文件的java文件工具类,支持日期格式目录名的生成
- 利用Lucene测试索引生成的.fnm 和 .fdx 和 .fdt 和 .tii 和 .tis文件所包含的内容(详解)
- Google Android开发者文档系列-创建有内容分享特性的应用之文件共享(序言)
- MyEclipse动态Web工程创建Servlet文件不自动生成web.xml文件内容的原因
- javaweb动态导出指定格式文件,并写入内容动态生成
- 生成水印图片是出现这个问题!(无法从带有索引像素格式的图像创建 Graphics 对象。)