Google开源OCR项目Tesseract安装版在Windows下的使用测试记录
2016-08-16 11:26
381 查看
开源OCR项目有很多,给大家一个链接,这个链接列出了现有的比较出名的OCR开源项目,链接如下:
https://en.wikipedia.org/wiki/Comparison_of_optical_character_recognition_software
从上面的排名可以看到,Tesseract是排在第一名的,所以咱们就先研究和测试它吧!
首先下载Tesseract在Windows下的安装版。(因为在国外访问不了谷歌,所以我翻墙下载了下来,这里给大家百度网盘链接)
http://pan.baidu.com/s/1i56Uxlr
下载下来之后一路Next安装好,然后在开始菜单找到其控制台引导程序,如下图所示:
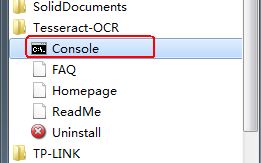
上面的安装包里自带了已经训练好的英文-拉丁文识别数据~所以我们先来测试一下英文字符的识别吧~识别图像如下:

上面这幅图片的下载链接:http://pan.baidu.com/s/1c9k4X4
把上面的图片放到Tesseract的安装目录下,如下图所示:
然后打开上面提到的控制台窗口,如下图所示:
在窗口中输入命令:“tesseract.exe 03.jpg 3”,并回车,如下图所示:

解释一下:03.jpg代表待识别的源文件,3代表输出文件名,默认输出格式是txt文件格式!
如果你不知道命令的参数格式,可以像下面这样查询:
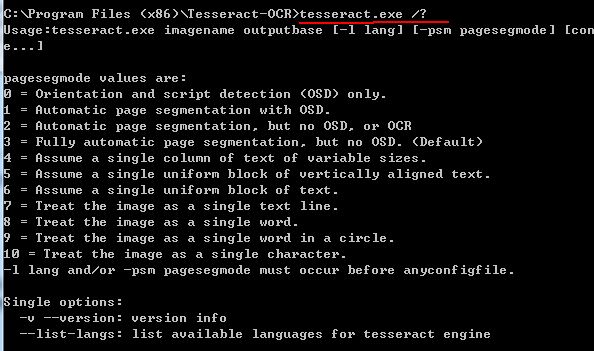
注意,上面的 lang之前是-l 而不是-1!
输入命令“tesseract.exe 03.jpg 3”后,在安装目录下生成了3.txt文件,这是识别结果,如下图所示:
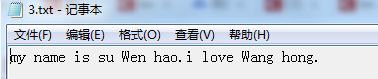
可见,对英文字符的识别率还是挺不错的。
接下来,我们测试下对中文的识别。首先要把中文训练数据放到目录C:\Program Files (x86)\Tesseract-OCR\tessdata 下边,如下图所示:
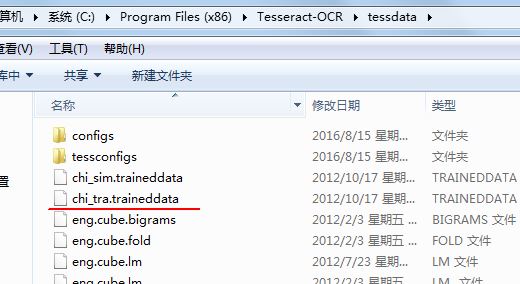
图片中的chi_tra.traineddata下载链接:http://pan.baidu.com/s/1nvaYhJz
然后在目录中放入测试图片04.jpg 05.jpg 这两幅图的下载链接为:http://pan.baidu.com/s/1qXUMwOk
如下图所示:


然后在CMD窗口中分别输入如下命令:
tesseract.exe 04.jpg 5 -l chi_tra
tesseract.exe 05.jpg 5_2 -l chi_tra
运行结果如下图所示:
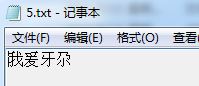
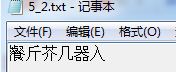
可见,结果非常不理想,所以接下来的任务就是要研究怎样提高识别率了,当然这是后话了,本文就先写到这样!
https://en.wikipedia.org/wiki/Comparison_of_optical_character_recognition_software
从上面的排名可以看到,Tesseract是排在第一名的,所以咱们就先研究和测试它吧!
首先下载Tesseract在Windows下的安装版。(因为在国外访问不了谷歌,所以我翻墙下载了下来,这里给大家百度网盘链接)
http://pan.baidu.com/s/1i56Uxlr
下载下来之后一路Next安装好,然后在开始菜单找到其控制台引导程序,如下图所示:
上面的安装包里自带了已经训练好的英文-拉丁文识别数据~所以我们先来测试一下英文字符的识别吧~识别图像如下:
上面这幅图片的下载链接:http://pan.baidu.com/s/1c9k4X4
把上面的图片放到Tesseract的安装目录下,如下图所示:
然后打开上面提到的控制台窗口,如下图所示:
在窗口中输入命令:“tesseract.exe 03.jpg 3”,并回车,如下图所示:
解释一下:03.jpg代表待识别的源文件,3代表输出文件名,默认输出格式是txt文件格式!
如果你不知道命令的参数格式,可以像下面这样查询:
注意,上面的 lang之前是-l 而不是-1!
输入命令“tesseract.exe 03.jpg 3”后,在安装目录下生成了3.txt文件,这是识别结果,如下图所示:
可见,对英文字符的识别率还是挺不错的。
接下来,我们测试下对中文的识别。首先要把中文训练数据放到目录C:\Program Files (x86)\Tesseract-OCR\tessdata 下边,如下图所示:
图片中的chi_tra.traineddata下载链接:http://pan.baidu.com/s/1nvaYhJz
然后在目录中放入测试图片04.jpg 05.jpg 这两幅图的下载链接为:http://pan.baidu.com/s/1qXUMwOk
如下图所示:
然后在CMD窗口中分别输入如下命令:
tesseract.exe 04.jpg 5 -l chi_tra
tesseract.exe 05.jpg 5_2 -l chi_tra
运行结果如下图所示:
可见,结果非常不理想,所以接下来的任务就是要研究怎样提高识别率了,当然这是后话了,本文就先写到这样!

相关文章推荐
- 图片识别工具Tesseract初探
- tesseract-ocr3.02字符识别过程操作步骤
- linux+tesseract+ruby 识别网站验证码
- Windows(VS2008) 下 build tesseract
- 利用开源程序(ImageMagick+tesseract-ocr)实现图像验证码识别
- 验证码识别的小程序源码
- ubuntu 12.04安装PIL tesseract进行验证码识别
- Tesseract训练注意事项
- zedboard-----------tesseract移植全过程记录
- debian8 上安装tesseract-ocr并使用Tess4j
- Tesseract OCR识别小结
- Translation:How to build Tesseract 3.03 with Visual Studio 2013 (翻译《VS2013 建立tesseract3.03工程》)
- tesseract3.03:vs2013 + x64 / x86 +win7 + 《How to build tesseract 3.03 with Visual Studio 2013》
- tesseract 3.04:vs2013 / vs2015 + 64 + win7 + charlesw 的代码
- Tesseract-OCR 字符识别---样本训练
- 如何通过Tesseract开源OCR引擎创建Android OCR应用
- 如何在windows上编译Tesseract OCR
- 使用Tesseract破解验证码并训练字库的方法
- 百度指数抓取思路
- tesseract在ok6410下的实现(一)