如何在windows上编译Tesseract OCR
2015-01-08 14:40
351 查看
获取Tesseract源码的方式有很多。可以直接从repo获取,也可以下载压缩包。不过编译的时候往往也会出现各种奇怪的问题。这里介绍如何简单的配置和编译源码。
参考原文:How to Build Tesseract OCR Library
on Windows
Windows installer of tesseract-ocr 3.02.02
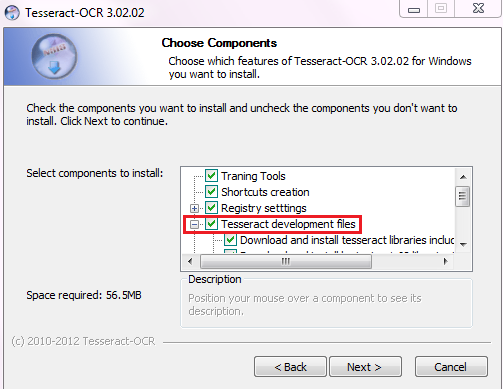
安装过程中勾选Tesseract development files:
在安装目录中找到vs2008到工程目录:

找到所有编译相关的库:

打开Visual Studio 2008(没有的可以去官网下载express版本),导入工程编译。最后生成DEBUG和RELEASE两个版本的DLL:libtesseract302d.dll ,libtesseract302.dll
在README中注意这段话:
Tesseract依赖Leptonica库,所以再看下Leptonica是怎么编译的。
Leptonica是C语言编写的一个图像处理库,支持JPEG, PNG, TIFF,GIF。
源码:leptonica-1.68.tar.gz
VS工程:vs2008-1.68.zip
相关头文件和库:leptonica-1.68-win32-lib-include-dirs.zip
把三个包解压,并按照下面的结构组建编译环境:
BuildFolder\leptonica-1.68 contents:
打开Visual Studio 2008,导入工程编译。最后生成DEBUG和RELEASE两个版本的DLL:liblept168d.dll,liblept168.dll
Leptonica
Leptonica & Visual Studio 2008
Tesseract-ocr
参考原文:How to Build Tesseract OCR Library
on Windows
编译Tesseract
下载
Windows installer of tesseract-ocr 3.02.02
安装
安装过程中勾选Tesseract development files:
编译
在安装目录中找到vs2008到工程目录:找到所有编译相关的库:
打开Visual Studio 2008(没有的可以去官网下载express版本),导入工程编译。最后生成DEBUG和RELEASE两个版本的DLL:libtesseract302d.dll ,libtesseract302.dll
在README中注意这段话:
Tesseract依赖Leptonica库,所以再看下Leptonica是怎么编译的。
编译Leptonica
Leptonica是C语言编写的一个图像处理库,支持JPEG, PNG, TIFF,GIF。
下载
源码:leptonica-1.68.tar.gzVS工程:vs2008-1.68.zip
相关头文件和库:leptonica-1.68-win32-lib-include-dirs.zip
编译
把三个包解压,并按照下面的结构组建编译环境:BuildFolder\leptonica-1.68 contents:
打开Visual Studio 2008,导入工程编译。最后生成DEBUG和RELEASE两个版本的DLL:liblept168d.dll,liblept168.dll
参考
LeptonicaLeptonica & Visual Studio 2008
Tesseract-ocr

相关文章推荐
- 如何在Windows下编译sqlite3,生成动态链接库并使用(New_070929)
- [HOW-TO]Windows平台如何编译代码
- Visual Studio 2010编译的C++程序如何支持Windows 2000
- Windows 下如何使用 Microsoft 的工具编译 PHP
- 如何在windows下编译Chrome源代码
- Windows下如何编译ffmpeg
- 如何在Windows下编译或调试MySQL
- [笔记] 如何在Windows下编译 cdrtools
- 如何在windows环境下编译servlet...
- windows 下如何成功编译wireshark 1.6.5
- MySQL代码如何在Windows环境下编译
- s如何在WINDOWS下编译BOOST C++库
- 如何在WINDOWS下编译BOOST C++库
- 如何在windows下编译Chrome源代码
- 如何在 Windows上编译Objective-C
- 问题的提出:如何在Windows上通过终端程序实现Unix平台的前台编译?
- [HOW-TO] Windows平台如何编译MySQL代码
- 如何在Windows下编译OpenSSL
- 如何在Windows下编译 cdrtools
- 如何在Windows中编译Linux Unix的代码?