Ng深度学习笔记 1-线性回归、监督学习、成本函数、梯度下降
2016-08-15 18:05
507 查看
查了查Ng是港裔。深度学习课的在线地址在这里:Deep Learning@Stanford。
他讲了监督学习的两类问题,分类和回归,并引入了两个例子。一个讲用现有的房屋面积和房价的数据集推算任意房子的价格(可认为是连续的),然后再引入其他模型参数,比如卧室个数等。另一个讲用肿瘤的大小来推断是否为良性或恶性肿瘤,如果引入其他参数,比如肿瘤细胞大小的一致性,及细胞形状的一致性等,依然可以找出这种关系,其结果是离散的(在其他问题中,可能分多于两个类,但依然是离散结果,是分类问题)。总之,两类问题都是根据已知的数据(参数值和输出)来推算尚未知输入的输出,这也就是监督学习的直观理解。
设计不同的模型来研究现实世界中的问题,引入更多的参数让该模型更趋近真实情形,这可能就是工程师看世界的角度吧。有人做过北京租房价格的统计,->戳post,可以在这个基础上学习一个房价模型(应该链家、麦田早就有他们的定价模型吧),现实情况往往复杂很多,链家员工去挨家挨户统计真实住房信息得磨断多少腿?->戳video
h(θ)是要学习的模型,xi为输入数据,yi是第i个观测数据,m为数据总量。θ是参数,这个是要学习的结果。学习过程就是不断调整参数,以使其误差J(θ)最小。这是跟最小二乘法如出一辙,最小二乘是要误差为 0。
在线性问题中,模型是这样表示的,n为参数个数,x下标的意义是第j个输入变量。
h(θ)=∑jnθjx(j)=θTx
在调整参数的时候,介绍了梯度下降的方法。求偏导部分读者自行推导一下。
这里 α 就是学习速率(learning rate),通过给 J 求偏导乘以学习速率来更新参数θ,这样才会逐渐趋近 J 的局部最小值 (local minimum)。在视频里,他举了单个参数的例子,在这样调整的时候,α 并不需用改变,因为每次的步长(Δθ) 是自动减少的,因为它每次在找偏导会变小的方向。如果开始就步长过长,可能第一次调整就越过(overshoot)局部最小值。xi,(j)就是第j个变量的第i个输入。
有两个变量的时候,J(θ0,θ1) 有直观的三维平面表示,如下图。
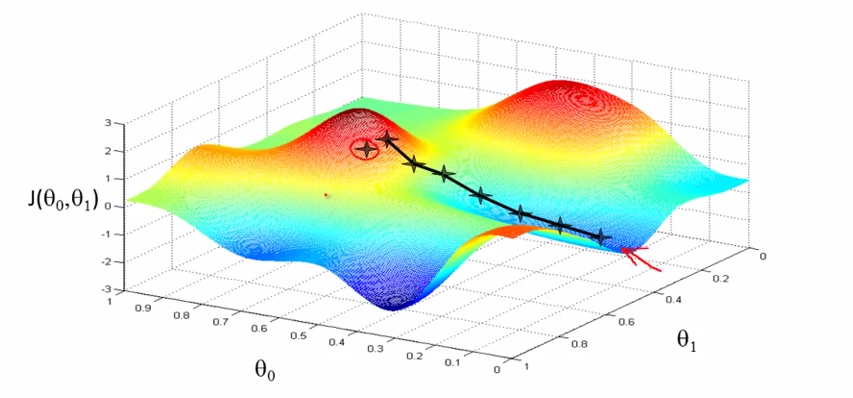
图中的每个十字是一次迭代计算。每一次迭代的时候好比从该十字向周围嗅探,去哪儿会降低 J。运气好的话,会找到波谷(深蓝色区域),从不同的出发点开始,可能会去到不同的波谷,运气差的话,可能走到两个波峰之间的平地(称作鞍面,即两个红色山丘的中间)。
Hθ(x)=θx
故,
θ′=θ−α∂∂θJ(θ)=θ−αm∑im((Hθ(x)−y)x)
Tornadomeet Blog
UFLDL Tutorial
他讲了监督学习的两类问题,分类和回归,并引入了两个例子。一个讲用现有的房屋面积和房价的数据集推算任意房子的价格(可认为是连续的),然后再引入其他模型参数,比如卧室个数等。另一个讲用肿瘤的大小来推断是否为良性或恶性肿瘤,如果引入其他参数,比如肿瘤细胞大小的一致性,及细胞形状的一致性等,依然可以找出这种关系,其结果是离散的(在其他问题中,可能分多于两个类,但依然是离散结果,是分类问题)。总之,两类问题都是根据已知的数据(参数值和输出)来推算尚未知输入的输出,这也就是监督学习的直观理解。
设计不同的模型来研究现实世界中的问题,引入更多的参数让该模型更趋近真实情形,这可能就是工程师看世界的角度吧。有人做过北京租房价格的统计,->戳post,可以在这个基础上学习一个房价模型(应该链家、麦田早就有他们的定价模型吧),现实情况往往复杂很多,链家员工去挨家挨户统计真实住房信息得磨断多少腿?->戳video
Cost Function
J(θ)=12m∑im(hθ(xi)−yi)2h(θ)是要学习的模型,xi为输入数据,yi是第i个观测数据,m为数据总量。θ是参数,这个是要学习的结果。学习过程就是不断调整参数,以使其误差J(θ)最小。这是跟最小二乘法如出一辙,最小二乘是要误差为 0。
在线性问题中,模型是这样表示的,n为参数个数,x下标的意义是第j个输入变量。
h(θ)=∑jnθjx(j)=θTx
在调整参数的时候,介绍了梯度下降的方法。求偏导部分读者自行推导一下。
Gradient Descent
θ′j=θj−α∂∂θjJ(θ)=θj−αm∑im((hθ(xi)−yi)xi,(j))这里 α 就是学习速率(learning rate),通过给 J 求偏导乘以学习速率来更新参数θ,这样才会逐渐趋近 J 的局部最小值 (local minimum)。在视频里,他举了单个参数的例子,在这样调整的时候,α 并不需用改变,因为每次的步长(Δθ) 是自动减少的,因为它每次在找偏导会变小的方向。如果开始就步长过长,可能第一次调整就越过(overshoot)局部最小值。xi,(j)就是第j个变量的第i个输入。
有两个变量的时候,J(θ0,θ1) 有直观的三维平面表示,如下图。
图中的每个十字是一次迭代计算。每一次迭代的时候好比从该十字向周围嗅探,去哪儿会降低 J。运气好的话,会找到波谷(深蓝色区域),从不同的出发点开始,可能会去到不同的波谷,运气差的话,可能走到两个波峰之间的平地(称作鞍面,即两个红色山丘的中间)。
Vectorized Implementation
线性回归的成本函数向量化表达为下式:Hθ(x)=θx
故,
θ′=θ−α∂∂θJ(θ)=θ−αm∑im((Hθ(x)−y)x)
References
Deep Learning courseTornadomeet Blog
UFLDL Tutorial

相关文章推荐
- CS229学习笔记之线性回归与梯度下降
- 【学习笔记】斯坦福大学公开课(机器学习) 之一:线性回归、梯度下降
- 机器学习入门:线性回归及梯度下降
- 机器学习入门:线性回归及梯度下降
- 零基础入门深度学习(2) - 线性单元和梯度下降--https://www.zybuluo.com/hanbingtao/note/448086
- 机器学习入门:线性回归及梯度下降(二)
- 机器学习-斯坦福:学习笔记2-监督学习应用与梯度下降
- 机器学习入门:线性回归及梯度下降
- 【斯坦福---机器学习】复习笔记之监督学习应用.梯度下降
- 机器学习入门:线性回归及梯度下降(一)
- 机器学习入门:线性回归及梯度下降
- 机器学习推导笔记1--机器学习的任务、步骤、线性回归、误差、梯度下降
- 机器学习入门:线性回归及梯度下降
- 机器学习深度学习基础笔记(2)——梯度下降之手写数字识别算法实现
- 监督学习之梯度下降——Andrew Ng机器学习笔记(一)
- 【机器学习-斯坦福】学习笔记2 - 监督学习应用与梯度下降
- Ng深度学习笔记2 -逻辑回归、分类问题、牛顿迭代
- 机器学习入门:线性回归及梯度下降
- 机器学习入门:线性回归及梯度下降
- 斯坦福大学机器学习笔记--第一周(5.线性回归的梯度下降)