Python爬取拉勾网招聘信息并写入Excel
2016-08-14 11:51
489 查看
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label
页面显示如下:
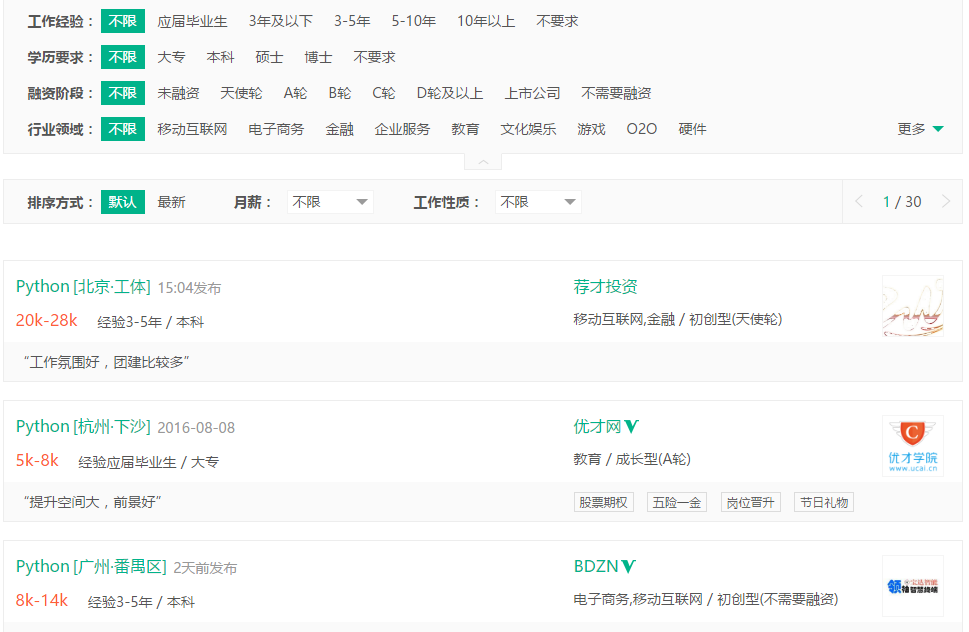
在Chrome浏览器中审查元素,找到对应的链接:

然后依次针对相应的链接(比如上面显示的第一个,链接为:http://www.lagou.com/jobs/2234309.html),打开之后查看,下面是我想具体爬取的每个公司岗位相关信息:
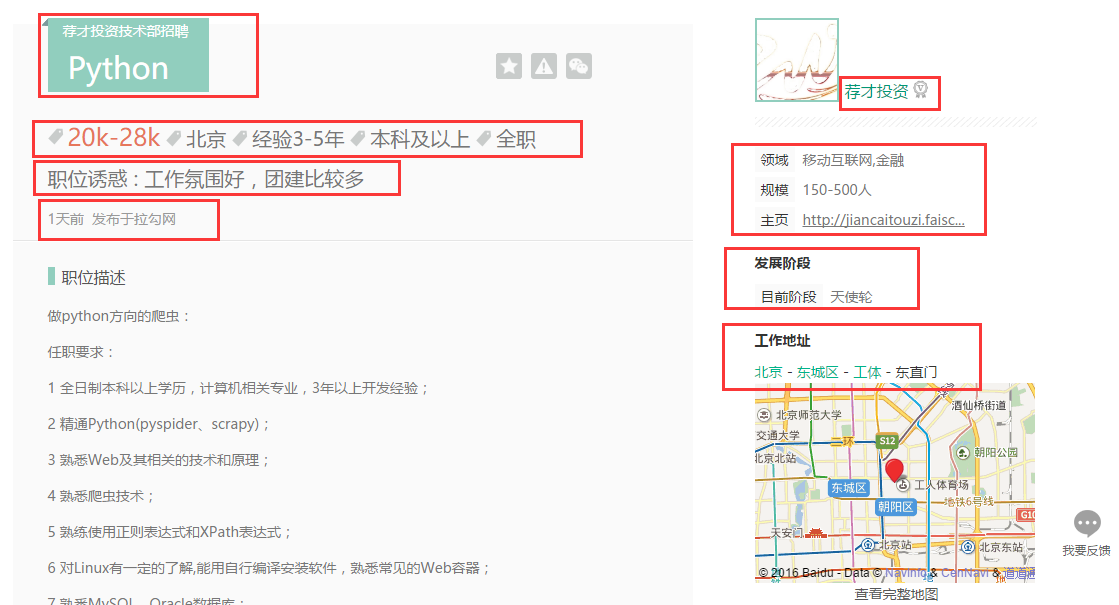
针对想要爬取的内容信息,找到html代码标签位置:
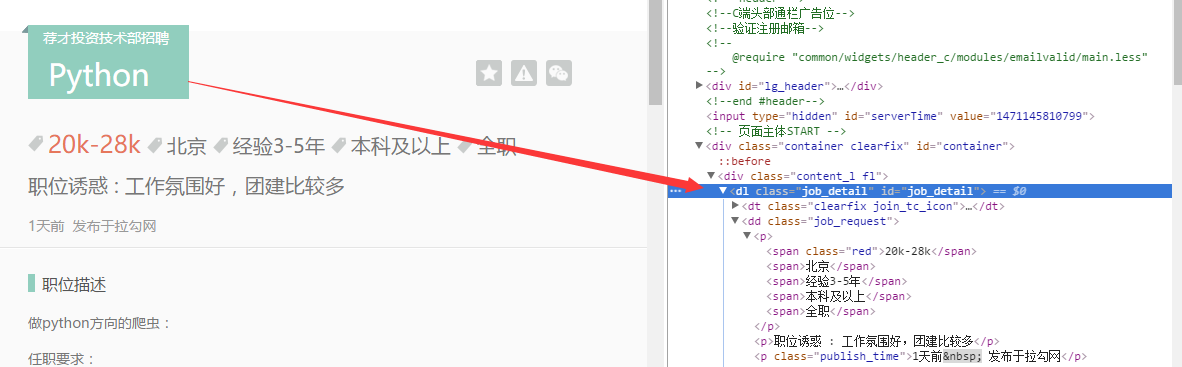
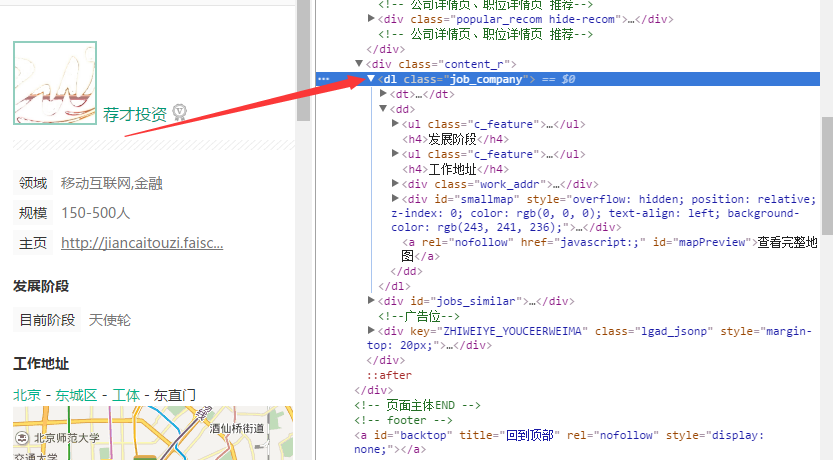
找到了相关的位置之后,就可以进行爬取的操作了。
以下是代码部分
也是一边摸索一边来进行的,其中的一些代码写的不是很规范和统一。
结果显示如下:
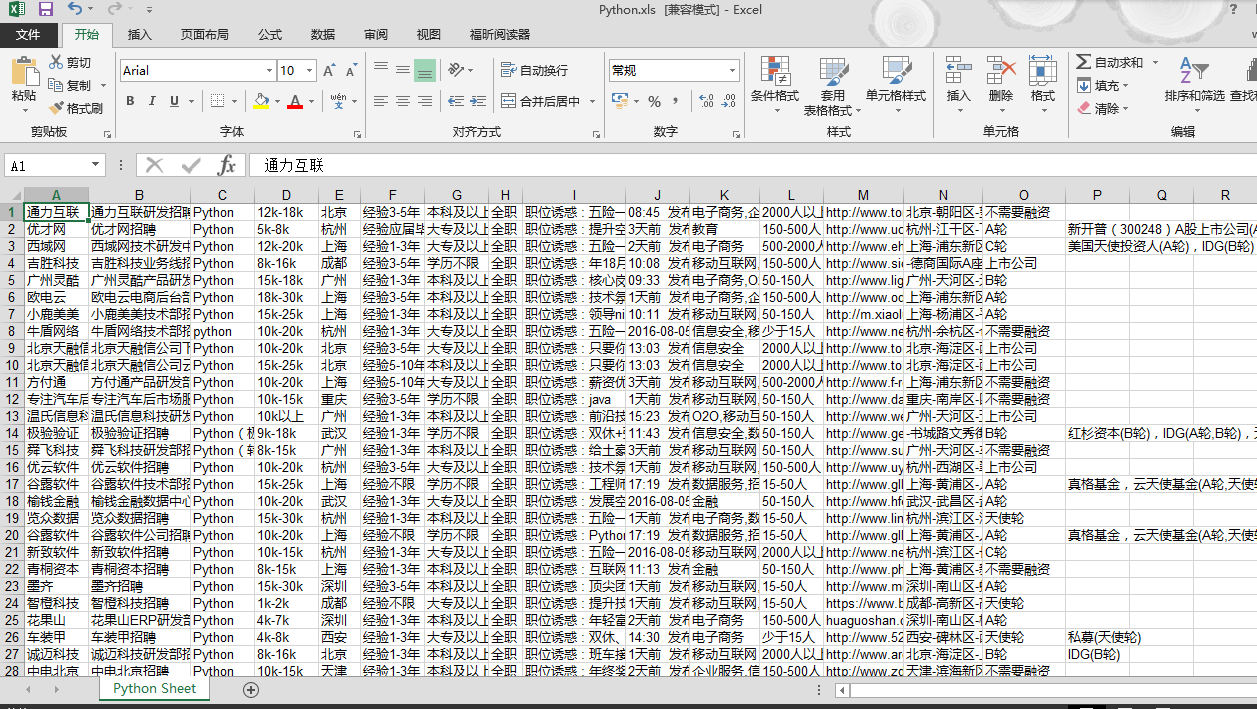
考虑打算下一步可以对相关的信息进行处理分析下,比如统计一下分布、薪资水平等之类的。
原文地址:http://www.cnblogs.com/leonwen/p/5769888.html
欢迎交流,请不要私自转载,谢谢
页面显示如下:
在Chrome浏览器中审查元素,找到对应的链接:
然后依次针对相应的链接(比如上面显示的第一个,链接为:http://www.lagou.com/jobs/2234309.html),打开之后查看,下面是我想具体爬取的每个公司岗位相关信息:
针对想要爬取的内容信息,找到html代码标签位置:
找到了相关的位置之后,就可以进行爬取的操作了。
以下是代码部分
# -*- coding:utf-8 -*-
import urllib
import urllib2
from bs4 import BeautifulSoup
import re
import xlwt
# initUrl = 'http://www.lagou.com/zhaopin/Python/?labelWords=label'
def Init(skillName):
totalPage = 30
initUrl = 'http://www.lagou.com/zhaopin/'
# skillName = 'Java'
userAgent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
headers = {'User-Agent':userAgent}
# create excel sheet
workBook = xlwt.Workbook(encoding='utf-8')
sheetName = skillName + ' Sheet'
bookSheet = workBook.add_sheet(sheetName)
rowStart = 0
for page in range(totalPage):
page += 1
print '##################################################### Page ',page,'#####################################################'
currPage = initUrl + skillName + '/' + str(page) + '/?filterOption=3'
# print currUrl
try:
request = urllib2.Request(currPage,headers=headers)
response = urllib2.urlopen(request)
jobData = readPage(response)
# rowLength = len(jobData)
for i,row in enumerate(jobData):
for j,col in enumerate(row):
bookSheet.write(rowStart + i,j,col)
rowStart = rowStart + i +1
except urllib2.URLError,e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
xlsName = skillName + '.xls'
workBook.save(xlsName)
def readPage(response):
btfsp = BeautifulSoup(response.read())
webLinks = btfsp.body.find_all('div',{'class':'p_top'})
# webLinks = btfsp.body.find_all('a',{'class':'position_link'})
# print weblinks.text
count = 1
jobData = []
for link in webLinks:
print 'No.',count,'==========================================================================================='
pageUrl = link.a['href']
jobList = loadPage(pageUrl)
# print jobList
jobData.append(jobList)
count += 1
return jobData
def loadPage(pageUrl):
currUrl = 'http:' + pageUrl
userAgent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
headers = {'User-Agent':userAgent}
try:
request = urllib2.Request(currUrl,headers=headers)
response = urllib2.urlopen(request)
content = loadContent(response.read())
return content
except urllib2.URLError,e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
def loadContent(pageContent):
# print pageContent
btfsp = BeautifulSoup(pageContent)
# job infomation
job_detail = btfsp.find('dl',{'id':'job_detail'})
jobInfo = job_detail.h1.text
tempInfo = re.split(r'(?:\s*)',jobInfo) # re.split is better than the Python's raw split function
jobTitle = tempInfo[1]
jobName = tempInfo[2]
job_request = job_detail.find('dd',{'class':'job_request'})
reqList = job_request.find_all('p')
jobAttract = reqList[1].text
publishTime = reqList[2].text
itemLists = job_request.find_all('span')
salary = itemLists[0].text
workplace = itemLists[1].text
experience = itemLists[2].text
education = itemLists[3].text
worktime = itemLists[4].text
# company's infomation
jobCompany = btfsp.find('dl',{'class':'job_company'})
# companyName = jobCompany.h2
companyName = re.split(r'(?:\s*)',jobCompany.h2.text)[1]
companyInfo = jobCompany.find_all('li')
# workField = companyInfo[0].text.split(' ',1)
workField = re.split(r'(?:\s*)|(?:\n*)',companyInfo[0].text)[2]
# companyScale = companyInfo[1].text
companyScale = re.split(r'(?:\s*)|(?:\n*)',companyInfo[1].text)[2]
# homePage = companyInfo[2].text
homePage = re.split(r'(?:\s*)|(?:\n*)',companyInfo[2].text)[2]
# currStage = companyInfo[3].text
currStage = re.split(r'(?:\s*)|(?:\n*)',companyInfo[3].text)[1]
financeAgent = ''
if len(companyInfo) == 5:
# financeAgent = companyInfo[4].text
financeAgent = re.split(r'(?:\s*)|(?:\n*)',companyInfo[4].text)[1]
workAddress = ''
if jobCompany.find('div',{'class':'work_addr'}):
workAddress = jobCompany.find('div',{'class':'work_addr'})
workAddress = ''.join(workAddress.text.split()) # It's sooooo cool!
# workAddress = jobCompany.find('div',{'class':'work_addr'})
# workAddress = ''.join(workAddress.text.split()) # It's sooooo cool!
infoList = [companyName,jobTitle,jobName,salary,workplace,experience,education,worktime,jobAttract,publishTime,
workField,companyScale,homePage,workAddress,currStage,financeAgent]
return infoList
def SaveToExcel(pageContent):
pass
if __name__ == '__main__':
# Init(userAgent)
Init('Python')也是一边摸索一边来进行的,其中的一些代码写的不是很规范和统一。
结果显示如下:
考虑打算下一步可以对相关的信息进行处理分析下,比如统计一下分布、薪资水平等之类的。
原文地址:http://www.cnblogs.com/leonwen/p/5769888.html
欢迎交流,请不要私自转载,谢谢

相关文章推荐
- python3爬取拉勾网招聘信息存为excel格式
- Python爬虫:爬取拉勾网招聘信息
- 爬取拉勾网招聘信息并使用xlwt存入Excel
- Python爬取拉勾网招聘信息
- 【python爬虫02】使用Scrapy框架爬取拉勾网招聘信息
- Python scrapy 爬取拉勾网招聘信息
- Python爬取拉勾网招聘信息
- Python爬虫-爬取51job.com 招聘信息并写入文件和数据库mysql
- 爬取前程无忧招聘信息并写入excel
- Python学习之路 (六)爬虫(五)爬取拉勾网招聘信息
- Python实战--抓取拉勾网招聘信息
- 爬取拉勾网招聘信息并使用xlwt存入Excel ——问题总结
- python爬取拉勾网招聘信息并利用pandas做简单数据分析
- 【Python】抓取拉勾网全国Python的招聘信息
- python获取天气信息写入原有的excel文档
- selenium+python关于登录的脚本代码,使用了读取excel以及向excel中写入测试结果的方法
- Python爬虫框架Scrapy实战之定向批量获取职位招聘信息
- Python爬虫框架Scrapy实战之定向批量获取职位招聘信息
- Python使用xlwt写excel并设置写入格式
- python 写入excel