K-means学习笔记
2016-08-13 17:55
99 查看
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
k-Means算法,是一种非监督的机器学习方法。
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设宇宙中的星星可以表示成三维空间中的点集
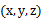
。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
在聚类问题中,给我们的训练样本是
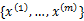
,每个
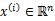
,没有了y。
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
1、 随机选取k个聚类质心点(cluster centroids)为
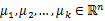
。
2、 重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的类
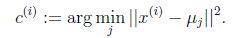
对于每一个类j,重新计算该类的质心
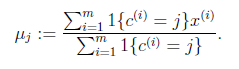
}
K是我们事先给定的聚类数,

代表样例i与k个类中距离最近的那个类,

的值是1到k中的一个。质心

代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为

,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心

(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
k-Means算法,是一种非监督的机器学习方法。
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设宇宙中的星星可以表示成三维空间中的点集

。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
在聚类问题中,给我们的训练样本是

,每个

,没有了y。
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
1、 随机选取k个聚类质心点(cluster centroids)为

。
2、 重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的类

对于每一个类j,重新计算该类的质心

}
K是我们事先给定的聚类数,

代表样例i与k个类中距离最近的那个类,

的值是1到k中的一个。质心

代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为

,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心

(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。

相关文章推荐
- 斯坦福NG机器学习:K-means笔记
- Deep Learning论文笔记之(一)K-means特征学习
- Deep Learning论文笔记之(一)K-means特征学习
- Opencv Python版学习笔记(七)k均值-k-means
- 机器学习笔记:K-Means无监督聚类算法
- MLAPP学习笔记-KNN与K-means引发的思考
- K-means、KNN学习笔记
- K-means学习笔记
- Deep Learning论文笔记之(一)K-means特征学习
- 【学习笔记】机器学习-K均值(k-means)
- K-means 学习笔记
- Deep Learning论文笔记之(一)K-means特征学习
- Deep Learning论文笔记之(一)K-means特征学习
- Deep Learning论文笔记之(一)K-means特征学习
- 机器学习笔记-聚类算法K-means和FCM的学习小结
- Andrew Ng机器学习课程笔记--week8(K-means&PCA)
- Deep Learning论文笔记之(一)K-means特征学习
- Deep Learning论文笔记之(一)K-means特征学习
- Deep Learning论文笔记之(一)K-means特征学习
- Deep Learning论文笔记之(一)K-means特征学习