监督学习之线性回归(续)
2016-08-12 16:21
369 查看
本节接着监督学习——线性回归继续讲述线性回归相关知识。
3 概率解释
当面对一个回归问题,为什么线性回归,精确地说为什么最小二乘代价函数

,是一个合理的选择?在这节中,我们将会给出一组概率假设,在这组假设下,最小二乘回归是可以很自然得到的算法。
让我们假设目标变量和输入变量通过下面等式关联

在这里,

是误差项,捕捉了未建模的影响(比如如果有一些因素对预测房子的价格非常相关的,但是我们没有考虑在回归之内)或者随机噪声。让我们进一步假设
是IID分布(独立同分布,independently and indentically distributed),服从零均值和某方差

的高斯分布(也称作正态分布)。我们可以把这个假设写作

。也就是说,
的概率密度为

这暗示着


这个符号表明这是给定

的

的分布,以

为参数。注意我们不可以以
为条件

,因为
不是一个随机变量。我们也可以把
的分布写作

给定

(为包含所有
的设计矩阵)和
,
的分布是什么?数据
的概率由

给出。这个数量通常被看作在给定
(可能是
)下的

的函数。当我们希望把它明确地看作成一个
的函数,我们而把称它为似然性函数:

注意到
的独立性的假设(因此给定
时
也是独立的),这也可以被写作

现在,给定这个关联
和
的概率模型,选择我们对参数
的最好猜测的合理方式是什么呢?最大似然的原则告诉我们应该选择
使得数据
发生的概率尽量高,也就是说,我们应该选择
使得

最大。
代替最大化
,我们也可以最大化任何一个严格递增的
的函数。尤其是,如果我们最大化对数似然函数(log likelihood)
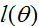
,推导也会简单一些。

因此,最大化
和最小化

得到同样的答案,而
,
我们认出是我们原始的最小二乘价值函数

。
总结:在对数据进行之前假设的情况下,最小二乘回归对应着求出
的最大似然估计。所以在这组假设下,最小二乘回归作为一种求解最大似然估计的很自然的方法是合理的。(然而,要注意的是,这些概率假设对最小二乘成为一个超好的和合理的程序绝不是必须的,可能有——而且确实有——其他自然的假设能够被用来证明这是正当的。)
也要注意的是,在我们之前的讨论中,我们对
最终的选择不依赖于
是什么,甚至如果
是未知的话我们确实也可以得到相同的结论。当我们之后谈论指数族和广义线性模型时,会用到这个事实。
4 局部加权线性回归
考虑由

预测

的问题。下面最左边的图形显示了

拟合一个数据集的结果。我们可以看到数据不能真正的分布在一条直线上,所以这个拟合不是很好。

相反,如果我们增加一个额外的特征

,用

拟合,然后我们得到一个稍微好一点的对数据的拟合(看中间的图形)。无邪地,似乎是我们添加的特征越多,(拟合)越好。然而,添加太多的特征也会有危险:最右边的图形是用一个5次多项式
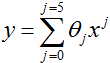
拟合的结果。我们看出,即使拟合曲线完美地经过所有数据,我们也不希望这是一个非常好的关于不同居住面积

的对房子价格
的预测器。我们将会说左边的图形是一个欠拟合的实例——在这个例子中,数据不能明确地呈现出模型捕捉到结构——右边的图形是一个过拟合的例子,(虽然)没有正式的定义这些项什么意思。(之后在这门课程中,当我们谈论学习理论时,我们将会形式化这些符号中的一些,也会更仔细的定义对于一个假设是好的还是坏的它意味着什么。)
正如前面讨论的,和上面例子中显示的,特征选择对确保学习算法的好的性能是重要的。
(当我们谈论模型选择时,我们将会看到自动选择一组好的特征的算法。)在这一节中,让我们简短地讨论一下局部加权线性回归(LWR)算法,这个算法假定有足够的训练数据,使得特征选择不再那么重要。这个处理将会简洁的,因为你将有机会在你的作业中探索LWR算法的一些特性。
在原始的线性回归算法,为了在查询点
作出一个预测,(也就是说,求

),我们将会:
1.寻找合适的

使

最小化。
2.输出

。
作为对比,局部加权线性回归算法如下过程:
1. 寻找合适的
使

最小化。
2. 输出
。
这里,

是非负的权重值。直观地,对于一个特值

如果
较大,我们将会尽力选择

使

较小。如果
较小,误差项
在寻找合适
中几乎被忽略。
一个对权重相当普遍的选择是

注意到权重依赖于我们正要评估的特定点

。而且,如果

值小,
接近于1;如果
值大,
值小。因此,
被选择使临近查询点

的训练例子(的误差)有较大的权值(不懂)。(也要注意的是,尽管权重的公式采取了一种外观和高斯分布密度相似的形式,但
和高斯没有任何直接关系,特别地,
不是随机变量,正态分布或者其他)。参数

控制着一个训练例子的权重随着

和查询点
的距离减少的多快。
被称作带宽参数,也是你在作业中将会做实验的东西。
我们正在看的局部权值线性回归是第一个非参数算法的第一个例子。我们更早些看到的(非权值)线性回归算法叫做参数学习算法,因为它有一些固定的、有限的用来拟合数据的参数(

)。一旦我们得到了合适的
,并存储起来,我们不再需要留有训练数据来做对以后的预测。相反,使用局部权值线性回归来预测,我们需要留有整个训练集。术语“非参数”(大致上)是指这样一个事实,为了表示假设

而保留的资料的数量随着训练集的大小而线性增长。
对线性回归的知识介绍到这里,接下来介绍监督学习里的分类和逻辑回归。
想写一写机器学习的翻译来巩固一下自己的知识,同时给需要的朋友们提供参考,鉴于作者水平有限,翻译不对或不恰当的地方,欢迎指正和建议。
3 概率解释
当面对一个回归问题,为什么线性回归,精确地说为什么最小二乘代价函数
,是一个合理的选择?在这节中,我们将会给出一组概率假设,在这组假设下,最小二乘回归是可以很自然得到的算法。
让我们假设目标变量和输入变量通过下面等式关联
在这里,
是误差项,捕捉了未建模的影响(比如如果有一些因素对预测房子的价格非常相关的,但是我们没有考虑在回归之内)或者随机噪声。让我们进一步假设
是IID分布(独立同分布,independently and indentically distributed),服从零均值和某方差
的高斯分布(也称作正态分布)。我们可以把这个假设写作
。也就是说,
的概率密度为
这暗示着
这个符号表明这是给定
的
的分布,以
为参数。注意我们不可以以
为条件
,因为
不是一个随机变量。我们也可以把
的分布写作
给定
(为包含所有
的设计矩阵)和
,
的分布是什么?数据
的概率由
给出。这个数量通常被看作在给定
(可能是
)下的
的函数。当我们希望把它明确地看作成一个
的函数,我们而把称它为似然性函数:
注意到
的独立性的假设(因此给定
时
也是独立的),这也可以被写作
现在,给定这个关联
和
的概率模型,选择我们对参数
的最好猜测的合理方式是什么呢?最大似然的原则告诉我们应该选择
使得数据
发生的概率尽量高,也就是说,我们应该选择
使得
最大。
代替最大化
,我们也可以最大化任何一个严格递增的
的函数。尤其是,如果我们最大化对数似然函数(log likelihood)
,推导也会简单一些。
因此,最大化
和最小化
得到同样的答案,而
,
我们认出是我们原始的最小二乘价值函数
。
总结:在对数据进行之前假设的情况下,最小二乘回归对应着求出
的最大似然估计。所以在这组假设下,最小二乘回归作为一种求解最大似然估计的很自然的方法是合理的。(然而,要注意的是,这些概率假设对最小二乘成为一个超好的和合理的程序绝不是必须的,可能有——而且确实有——其他自然的假设能够被用来证明这是正当的。)
也要注意的是,在我们之前的讨论中,我们对
最终的选择不依赖于
是什么,甚至如果
是未知的话我们确实也可以得到相同的结论。当我们之后谈论指数族和广义线性模型时,会用到这个事实。
4 局部加权线性回归
考虑由
预测
的问题。下面最左边的图形显示了
拟合一个数据集的结果。我们可以看到数据不能真正的分布在一条直线上,所以这个拟合不是很好。
相反,如果我们增加一个额外的特征
,用
拟合,然后我们得到一个稍微好一点的对数据的拟合(看中间的图形)。无邪地,似乎是我们添加的特征越多,(拟合)越好。然而,添加太多的特征也会有危险:最右边的图形是用一个5次多项式
拟合的结果。我们看出,即使拟合曲线完美地经过所有数据,我们也不希望这是一个非常好的关于不同居住面积
的对房子价格
的预测器。我们将会说左边的图形是一个欠拟合的实例——在这个例子中,数据不能明确地呈现出模型捕捉到结构——右边的图形是一个过拟合的例子,(虽然)没有正式的定义这些项什么意思。(之后在这门课程中,当我们谈论学习理论时,我们将会形式化这些符号中的一些,也会更仔细的定义对于一个假设是好的还是坏的它意味着什么。)
正如前面讨论的,和上面例子中显示的,特征选择对确保学习算法的好的性能是重要的。
(当我们谈论模型选择时,我们将会看到自动选择一组好的特征的算法。)在这一节中,让我们简短地讨论一下局部加权线性回归(LWR)算法,这个算法假定有足够的训练数据,使得特征选择不再那么重要。这个处理将会简洁的,因为你将有机会在你的作业中探索LWR算法的一些特性。
在原始的线性回归算法,为了在查询点
作出一个预测,(也就是说,求
),我们将会:
1.寻找合适的
使
最小化。
2.输出
。
作为对比,局部加权线性回归算法如下过程:
1. 寻找合适的
使
最小化。
2. 输出
。
这里,
是非负的权重值。直观地,对于一个特值
如果
较大,我们将会尽力选择
使
较小。如果
较小,误差项
在寻找合适
中几乎被忽略。
一个对权重相当普遍的选择是
注意到权重依赖于我们正要评估的特定点
。而且,如果
值小,
接近于1;如果
值大,
值小。因此,
被选择使临近查询点
的训练例子(的误差)有较大的权值(不懂)。(也要注意的是,尽管权重的公式采取了一种外观和高斯分布密度相似的形式,但
和高斯没有任何直接关系,特别地,
不是随机变量,正态分布或者其他)。参数
控制着一个训练例子的权重随着
和查询点
的距离减少的多快。
被称作带宽参数,也是你在作业中将会做实验的东西。
我们正在看的局部权值线性回归是第一个非参数算法的第一个例子。我们更早些看到的(非权值)线性回归算法叫做参数学习算法,因为它有一些固定的、有限的用来拟合数据的参数(
)。一旦我们得到了合适的
,并存储起来,我们不再需要留有训练数据来做对以后的预测。相反,使用局部权值线性回归来预测,我们需要留有整个训练集。术语“非参数”(大致上)是指这样一个事实,为了表示假设
而保留的资料的数量随着训练集的大小而线性增长。
对线性回归的知识介绍到这里,接下来介绍监督学习里的分类和逻辑回归。
想写一写机器学习的翻译来巩固一下自己的知识,同时给需要的朋友们提供参考,鉴于作者水平有限,翻译不对或不恰当的地方,欢迎指正和建议。

相关文章推荐
- mysql show status详解
- Android开发----AsyncTask的使用以及源码解析
- AFNetworking 文件上传Data,File图片,文件等上传
- 论RE的多种姿势
- AAF技术及其在后期制作系统中的应用
- 存档2
- git使用技巧
- Mysql数据库优化
- 机器人运动学_不同D-H矩阵的对比
- 集合数组的转换
- hdu 5811 Colosseo (拓扑排序 + 最长上升子序列)
- 奥运赛事,精彩纷呈
- 存档
- 第四章:Linear Models for Classification exercise 25-26
- 大数据系列修炼-Scala课程13+14
- 理解Cookie和Session机制
- C语言操作符优先级
- CSS盒子模型-盒子模型应用
- OC当中的闭包
- swift学习----记使用NSClassFromString一个坑