利用Python进行数据分析
2016-08-09 09:19
791 查看
最近在阅读《利用Python进行数据分析》,本篇博文作为读书笔记 ,记录一下阅读书签和实践心得。
接下来是配置IPython,初步感受了这个与之前接触的IDE完全不一样的编程方式,感觉很不错,推荐给大家。
安装主要需要安装IPython和IPython notebook两个第三方包,通过pip install 一下就好了。
安装成功后,启动IPython服务器(?我感觉应该是后台自动开了一个服务器),命令是IPython notebook。
上述步骤都搞定后,在浏览器上输入“http://localhost:8888/tree”,可以看到这个界面准备工作已经就绪了。
Series
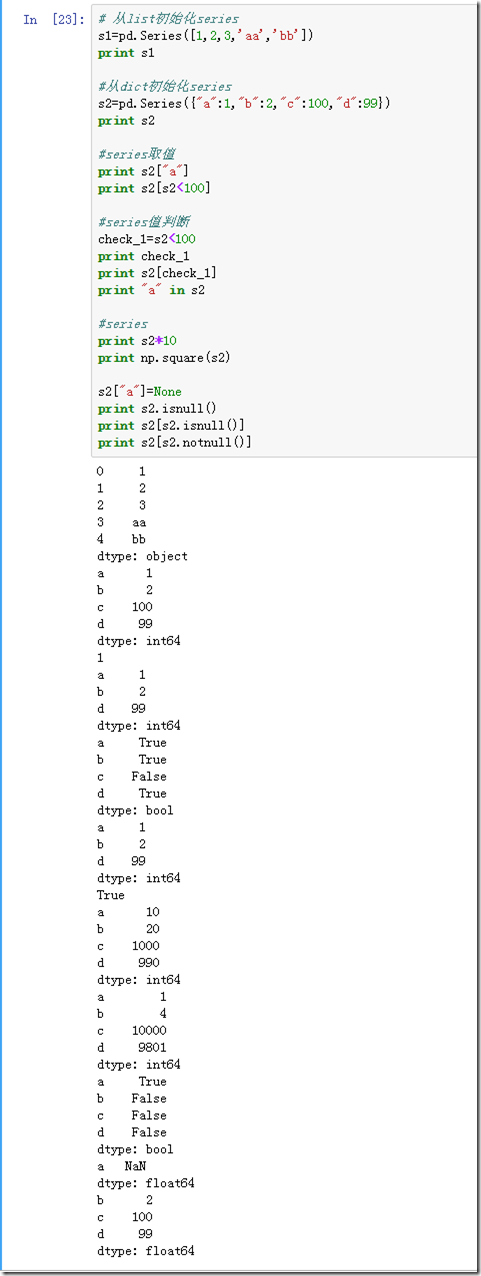
Series是一个一维数组对象,与list数据结构相近,Series中每个条目都会被分配一个标签索引。默认情况下,每个条目都会收到一个从0到N之间的索引标签,其中N等于Series的长度减一。Series可以从list或者dict初始化,可以多种取值方式,非常有意思:
DataFrame
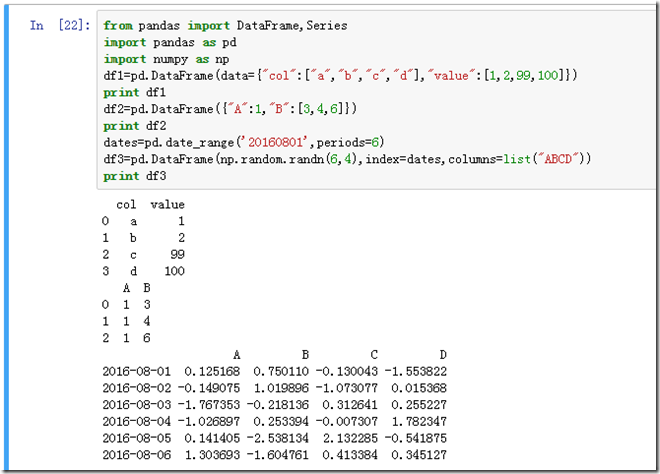
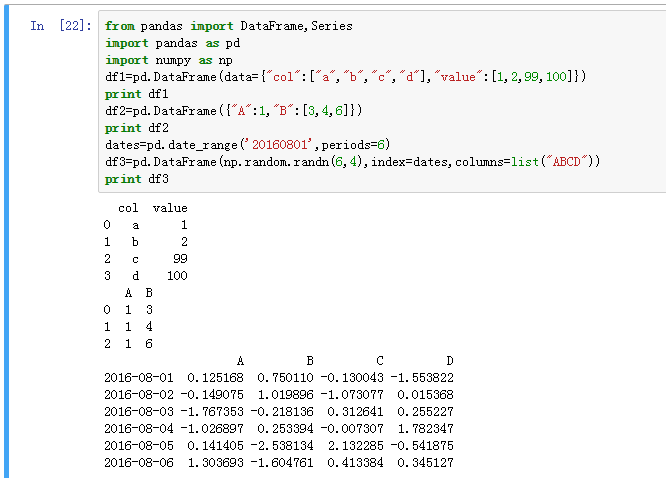
DataFrame是一种由列向量和行向量组成的数据结构,它类似于电子数据表、数据库表格,也可以认为DataFrame是有多个共享索引值的Series对象构成。
对于DataFrame,可以从python的dict中转化得到,也可以从csv或者数据库中获得。通过help(Pandas.DataFrame)可以获得信息:
基本上可以对如何构建DataFrame对象有一个基本的概念,如果不从外部数据(csv、数据库)中导入文件的话,可以通过字典或者numpy来构建输入数据:
准备工作
python环境配置好了,可以参见我之前的博文《基于Python的数据分析(1):配置安装环境》。还需要安装第三方包包括NumPy、pandas、matplotlib、IPython、SciPy。用pip安装工具下载自动安装即可,如果有网络问题,请在自行百度”host google“更新host文件。接下来是配置IPython,初步感受了这个与之前接触的IDE完全不一样的编程方式,感觉很不错,推荐给大家。
安装主要需要安装IPython和IPython notebook两个第三方包,通过pip install 一下就好了。
安装成功后,启动IPython服务器(?我感觉应该是后台自动开了一个服务器),命令是IPython notebook。
上述步骤都搞定后,在浏览器上输入“http://localhost:8888/tree”,可以看到这个界面准备工作已经就绪了。

Pandas
书本上手用了一个时区的数据对于Pandas的DataFrame和Series两个对象进行简单的操作。我不是很喜欢这种直接上实例教学的方法,所以先在网上找了一些Pandas库的基本对象和常用函数。Series
Series是一个一维数组对象,与list数据结构相近,Series中每个条目都会被分配一个标签索引。默认情况下,每个条目都会收到一个从0到N之间的索引标签,其中N等于Series的长度减一。Series可以从list或者dict初始化,可以多种取值方式,非常有意思:

DataFrame
DataFrame是一种由列向量和行向量组成的数据结构,它类似于电子数据表、数据库表格,也可以认为DataFrame是有多个共享索引值的Series对象构成。
对于DataFrame,可以从python的dict中转化得到,也可以从csv或者数据库中获得。通过help(Pandas.DataFrame)可以获得信息:
class DataFrame(pandas.core.generic.NDFrame)
| Two-dimensional size-mutable, potentially heterogeneous tabular data
| structure with labeled axes (rows and columns). Arithmetic operations
| align on both row and column labels. Can be thought of as a dict-like
| container for Series objects. The primary pandas data structure
|
| Parameters
| ----------
| data : numpy ndarray (structured or homogeneous), dict, or DataFrame
| Dict can contain Series, arrays, constants, or list-like objects
| index : Index or array-like
| Index to use for resulting frame. Will default to np.arange(n) if
| no indexing information part of input data and no index provided
| columns : Index or array-like
| Column labels to use for resulting frame. Will default to
| np.arange(n) if no column labels are provided
| dtype : dtype, default None
| Data type to force, otherwise infer
| copy : boolean, default False
| Copy data from inputs. Only affects DataFrame / 2d ndarray input
|
| Examples
| --------
| >>> d = {'col1': ts1, 'col2': ts2}
| >>> df = DataFrame(data=d, index=index)
| >>> df2 = DataFrame(np.random.randn(10, 5))
| >>> df3 = DataFrame(np.random.randn(10, 5),
| ... columns=['a', 'b', 'c', 'd', 'e'])
|
| See also
| --------
| DataFrame.from_records : constructor from tuples, also record arrays
| DataFrame.from_dict : from dicts of Series, arrays, or dicts
| DataFrame.from_csv : from CSV files
| DataFrame.from_items : from sequence of (key, value) pairs
| pandas.read_csv, pandas.read_table, pandas.read_clipboard基本上可以对如何构建DataFrame对象有一个基本的概念,如果不从外部数据(csv、数据库)中导入文件的话,可以通过字典或者numpy来构建输入数据:

相关文章推荐
- 利用python进行数据分析-关于包的坑
- 利用Python进行数据分析---ch02《MovieLens 1M数据集(上)》读书笔记
- 利用Python进行数据分析--数据聚合与分组运算
- 利用Python进行数据分析--数据规整化:清理、转换、合并、重塑
- 利用Python进行数据分析——准备工作篇
- 利用Python进行数据分析笔记(一
- 《利用Python进行数据分析: Python for Data Analysis 》学习随笔
- 利用Python进行数据分析--绘图和可视化
- 《利用Python 进行数据分析》 - 笔记(2)
- [python和大数据-1]利用爬虫登录知乎进行BFS搜索抓取用户信息本地mysql分析【PART1】
- 利用Python进行数据分析——第一章:重要Python库安装配置
- 利用Python进行数据分析——数据规整化:清理、转换、合并、重塑(七)(1)
- 利用python进行数据分析之pandas库的应用(一)
- 利用Python进行数据分析--时间序列
- 利用Python进行数据分析——数据规整化:清理、转换、合并、重塑(七)(5) .
- 利用Python进行数据分析--数据加载、存储与文件格式
- linux下利用python进行数据分析(1)Anaconda 安装
- 利用python进行数据分析之绘图和可视化
- 利用Python进行数据分析---ch02《MovieLens 1M数据集(下)》读书笔记
- 《利用python 进行数据分析》要点记录