mysql无限级分类实现基于汇报关系的信息管理权限
2016-08-08 14:46
411 查看
汇报关系和家族族谱的实现类似,采用树的数据结构进行定义,树采用递归进行定义。即要嘛是一个根节点,要嘛是由一个根节点和其子树组成。OA中的汇报关系也采用这种结构(与树稍有不同),除董事长外,其他人有且只有一个非其本人的直接主管,董事长的直接主管和越级主管是其本人。从以上的定义其实可以看出,汇报关系类似树,但又与树并不完全相同。除董事长外,其他汇报关系均是树形结构。树形结构采用递归定义,如采用递归查询是非常耗时的操作。比如以下需求:
1.主管可以看到所有直线下属的绩效信息;
针对以上需求,我们提出三种方法
1.递归:如果采用树递归进行查询,对于庞大的数据量和较深的层级来说是比较耗时的。
2.父类id前缀:即父id为fid,子类编码规则则是以fid为前缀,查询的时候采用like,这种方法的缺点是1.不符合数据库规范要求;2.修改和移动耗时或不便
以下采用一种mysql无限级分类的方法来实现基于汇报关系的信息管理权限。
先了解一下mysql的无限级分类实现方法——改进前序遍历树
以下图为例,先把树按照水平方式摆开。从根节点开始(“Food”),然后他的左边写上1。然后按照树的顺序(从上到下)给“Fruit”的左边写上2。这样,你沿着树的边界(这就是“遍历”),然后同时在每个节点的左边和右边写上数字。最后,我们回到了根节点“Food”在右边写上18。下面是标上了数字的树,同时把遍历的顺序用箭头标出来了。
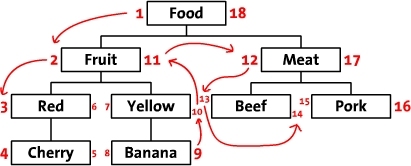
我们称这些数字为左值和右值(如,“Food”的左值是1,右值是18)。正如你所见,这些数字按时了每个节点之间的关系。因为“Red”有3和6两个值,所以,它是有拥有1-18值的“Food”节点的后续。同样的,我们可以推断所有左值大于2并且右值小于11的节点,都是有2-11的“Fruit” 节点的后续。这样,树的结构就通过左值和右值储存下来了。这种数遍整棵树算节点的方法叫做“改进前序遍历树”算法。
该算法具有据存储冗余小、直观性强;方便返回整个树型结构数据;可以很轻松的返回某一子树(方便分层加载);快整获以某节点的祖谱路径;插入、删除、移动节点效率高等特点。
我们需要解决的最集中问题是查询效率。从图上看,我们如果查询Fruit的所有子类,只需要查询其左值>父结点左值&&右值小于父节点右值的节点。其查询时间复杂度是常数阶O(1),而最有利的子树查询算法也是对数阶O(lgn)。从时间复杂度角度该算法的查询效率是达到最优的。
在本方法中主要采用两张表来实现,一张是汇报关系生成方法2格式的汇报关系对照表,第二张用于存储生成的改进前序遍历树
表1 tmpList定义如下:
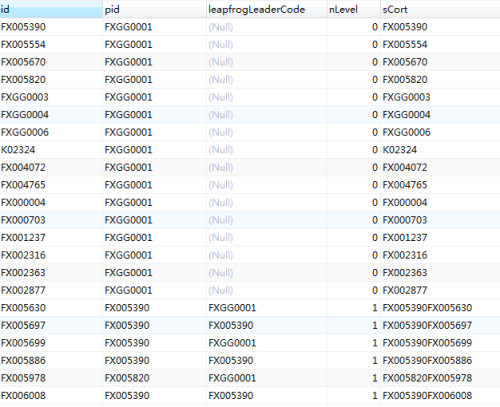
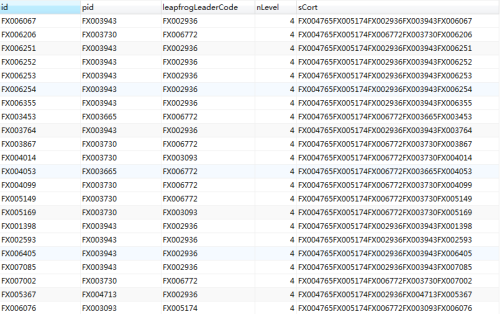
id是员工工号,pid是直接主管工号,leapfrogLeaderCode是越级主管工号,nLevel是层数,sCort是方法2生成的父节点前缀工号
根据tmpList生成tree_node的存储过程 :
插入操作很简单找到其父节点,之后把左值和右值大于父节点左值的节点的左右值加上2,之后再插入本节点,左右值分别为父节点左值加一和加二,可以用一个存储过程来操作:
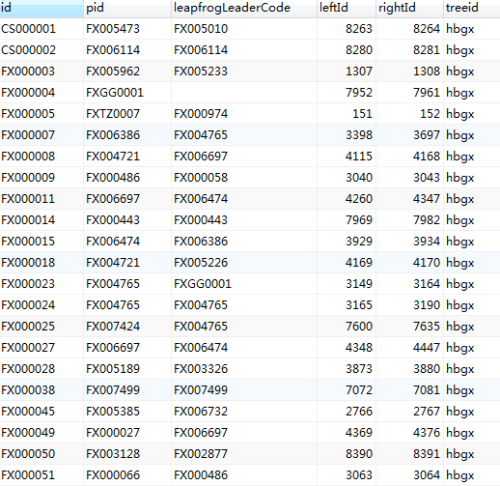
前序遍历树数据生成以后,在需要使用以汇报关系做为基准的数据范围查询中增加如下代码:
1.
删除的原理:
得到要删除节点的左右值,并得到他们的差再加一,@mywidth = @rgt - @lft + 1;
删除左右值在本节点之间的节点
修改条件为大于本节点右值的所有节点,操作为把他们的左右值都减去@mywidth
只允许删除叶子节点,如需删除叶子节点,先移动该节点不叶子节点,然后删除
参考资料:
SQL Server存储层级数据实现无限级分类
一个带存储过程的无限级分类数据库设计
1.主管可以看到所有直线下属的绩效信息;
针对以上需求,我们提出三种方法
1.递归:如果采用树递归进行查询,对于庞大的数据量和较深的层级来说是比较耗时的。
2.父类id前缀:即父id为fid,子类编码规则则是以fid为前缀,查询的时候采用like,这种方法的缺点是1.不符合数据库规范要求;2.修改和移动耗时或不便
以下采用一种mysql无限级分类的方法来实现基于汇报关系的信息管理权限。
先了解一下mysql的无限级分类实现方法——改进前序遍历树
以下图为例,先把树按照水平方式摆开。从根节点开始(“Food”),然后他的左边写上1。然后按照树的顺序(从上到下)给“Fruit”的左边写上2。这样,你沿着树的边界(这就是“遍历”),然后同时在每个节点的左边和右边写上数字。最后,我们回到了根节点“Food”在右边写上18。下面是标上了数字的树,同时把遍历的顺序用箭头标出来了。
我们称这些数字为左值和右值(如,“Food”的左值是1,右值是18)。正如你所见,这些数字按时了每个节点之间的关系。因为“Red”有3和6两个值,所以,它是有拥有1-18值的“Food”节点的后续。同样的,我们可以推断所有左值大于2并且右值小于11的节点,都是有2-11的“Fruit” 节点的后续。这样,树的结构就通过左值和右值储存下来了。这种数遍整棵树算节点的方法叫做“改进前序遍历树”算法。
该算法具有据存储冗余小、直观性强;方便返回整个树型结构数据;可以很轻松的返回某一子树(方便分层加载);快整获以某节点的祖谱路径;插入、删除、移动节点效率高等特点。
我们需要解决的最集中问题是查询效率。从图上看,我们如果查询Fruit的所有子类,只需要查询其左值>父结点左值&&右值小于父节点右值的节点。其查询时间复杂度是常数阶O(1),而最有利的子树查询算法也是对数阶O(lgn)。从时间复杂度角度该算法的查询效率是达到最优的。
在本方法中主要采用两张表来实现,一张是汇报关系生成方法2格式的汇报关系对照表,第二张用于存储生成的改进前序遍历树
表1 tmpList定义如下:
SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for tmplst -- ---------------------------- DROP TABLE IF EXISTS `tmplst`; CREATE TABLE `tmplst` ( `id` varchar(50) DEFAULT NULL, `pid` varchar(50) DEFAULT NULL, `leapfrogLeaderCode` varchar(50) DEFAULT NULL, `nLevel` int(11) DEFAULT NULL, `sCort` varchar(8000) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;表2 tree_node定义如下:
SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for tree_node -- ---------------------------- DROP TABLE IF EXISTS `tree_node`; CREATE TABLE `tree_node` ( `id` varchar(20) NOT NULL DEFAULT '' COMMENT '工号', `pid` varchar(20) DEFAULT NULL COMMENT '直接主管工号', `leapfrogLeaderCode` varchar(20) DEFAULT NULL COMMENT '越级主管工号', `leftId` int(50) DEFAULT NULL COMMENT '前序遍历树右节点左节点', `rightId` int(50) DEFAULT NULL COMMENT '前序遍历树右节点', `treeid` varchar(50) NOT NULL DEFAULT 'hbgx', PRIMARY KEY (`id`), KEY `idx_tree_node_leftId` (`leftId`) USING BTREE, KEY `idx_tree_node_rightId` (`rightId`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;由于汇报关系并不是简单的树形结构,第一个节点即根节点是特殊的。所以这个节点作为特殊节点单独插入,采用如下存储过程:
ExitLabel:BEGIN DECLARE vLeftId INT; DECLARE aff INT; SELECT `leftId` INTO vLeftId FROM `tree_node` WHERE `id`= rootid AND `pid` = 0; IF vLeftId IS NOT NULL THEN LEAVE ExitLabel; END IF; START TRANSACTION; INSERT INTO `tree_node`(`id`,`pid`,`leftId`,`rightId`,`leapfrogLeaderCode`) VALUES (rootid,0,1,2,rootid); SELECT ROW_COUNT() INTO aff; IF aff = 1 THEN COMMIT; ELSE ROLLBACK; END IF; END生成tmpList数据
BEGIN DECLARE Level int ; DECLARE pid VARCHAR(50); DECLARE id VARCHAR(50); DECLARE leapfrogLeaderCode VARCHAR(50); drop TABLE IF EXISTS tmpLst; CREATE TABLE tmpLst ( id varchar(50), pid varchar(50), leapfrogLeaderCode varchar(50), nLevel int, sCort varchar(8000) ); Set Level=0 ; INSERT into tmpLst SELECT staffId,directLeaderCode,leapfrogLeaderCode,Level,staffId FROM t_per_staffinfo WHERE directLeaderCode=rootid; WHILE ROW_COUNT()>0 DO SET Level=Level+1 ; INSERT into tmpLst SELECT A.staffId,A.directLeaderCode,A.leapfrogLeaderCode,Level,concat(B.sCort,A.staffId) FROM t_per_staffinfo A,tmpLst B WHERE A.directLeaderCode=B.ID AND B.nLevel=Level-1 ; END WHILE; END生成的数据格式如下:
id是员工工号,pid是直接主管工号,leapfrogLeaderCode是越级主管工号,nLevel是层数,sCort是方法2生成的父节点前缀工号
根据tmpList生成tree_node的存储过程 :
插入操作很简单找到其父节点,之后把左值和右值大于父节点左值的节点的左右值加上2,之后再插入本节点,左右值分别为父节点左值加一和加二,可以用一个存储过程来操作:
ExitLabel:BEGIN DECLARE vRightId INT; DECLARE vTreeId varchar(50); DECLARE aff INT; DECLARE af INT DEFAULT 0; SELECT `rightId` INTO vRightId FROM `tree_node` WHERE `id`= pid; IF vRightId IS NULL THEN LEAVE ExitLabel; END IF; START TRANSACTION; UPDATE `tree_node` SET `leftId`=`leftId`+2 WHERE `leftId` > vRightId; SELECT ROW_COUNT() INTO aff; SET af = aff+af; UPDATE `tree_node` SET `rightId`=`rightId`+2 WHERE `rightId` >= vRightId; SELECT ROW_COUNT() INTO aff; SET af = aff+af; INSERT INTO `tree_node`(`id`,`pid`,`leftId`,`rightId`,`leapfrogLeaderCode`) VALUES (code,pid,vRightId,vRightId+1,leapfrogLeaderCode); SELECT ROW_COUNT() INTO aff; SET af = aff+af; IF af >= 2 THEN COMMIT; ELSE ROLLBACK; END IF; END生成的改进前序遍历树数据如下:
前序遍历树数据生成以后,在需要使用以汇报关系做为基准的数据范围查询中增加如下代码:
<!-- 查询当前工号的汇报关系下属 -->
<select id="queryTreeNodeByStaffid" parameterType="String" resultMap="UserResultMap">
SELECT u.* FROM T_SYS_USER u LEFT JOIN tree_node t ON u.staffId = t.id
WHERE
u.userStatus = 'normal'
and
<![CDATA[ t.leftId > (SELECT leftId FROM tree_node treenode WHERE treenode.id = #{staffId}) ]]>
AND
<![CDATA[ t.rightId < (SELECT rightId FROM tree_node treenode WHERE treenode.id = #{staffId}) ]]>
</select> 由于汇报关系并不是一成不变的,在汇报关系出现变化时,应该修改tree_node表以适应最新的变化,使基于汇报关系的数据范围查询更加准确,以下存储过程是修改遍历表的:1.
ExitLabel:BEGIN call moveTreeNode(nodeId,pid,resultCode,resultMsg); IF resultCode=1000 THEN UPDATE `tree_node` SET `leapfrogLeaderCode` = leapfrogLeaderCode WHERE `id`= nodeId; COMMIT; END IF; END2.
ExitLabel:BEGIN DECLARE vLeftId INT; DECLARE vRightId INT; DECLARE vTreeId varchar(50); DECLARE vPid varchar(50); DECLARE vTargetLeftId INT; DECLARE vTargetRightId INT; DECLARE vDiff INT; DECLARE vLevelDiff INT; DECLARE vGroupTreeId INT; DECLARE vGroupIdStr varchar(1000); SELECT `leftId`,`rightId`,`treeId`,`pid` INTO vLeftId,vRightId,vTreeId,vPid FROM `tree_node` WHERE `id`= nodeId; IF vLeftId IS NULL THEN SET resultCode = 1002; SET resultMsg = "要移动的节点不存在"; LEAVE ExitLabel; END IF; IF vLeftId=1 THEN SET resultCode = 1003; SET resultMsg = "根节点不能移动"; LEAVE ExitLabel; END IF; IF nodeId = targetId THEN SET resultCode = 1004; SET resultMsg = "不能移动到自己"; LEAVE ExitLabel; END IF; IF vPid = targetId THEN SET resultCode = 1000; SET resultMsg = "目标节点是要移动节点的父节点,不需要移动"; LEAVE ExitLabel; END IF; SELECT `leftId`,`rightId` INTO vTargetLeftId,vTargetRightId FROM `tree_node` WHERE `treeId` = vTreeId AND `id`= targetId; IF vTargetLeftId IS NULL THEN SET resultCode = 1006; SET resultMsg = "目标节点不存在"; LEAVE ExitLabel; END IF; IF vTargetLeftId > vLeftId AND vTargetLeftId < vRightId THEN SET resultCode = 1007; SET resultMsg = "目标节点不能是要移动节点的子节点"; LEAVE ExitLabel; END IF; START TRANSACTION; SELECT `treeId`, group_concat(CAST(`id` as char)) as idStr INTO vGroupTreeId,vGroupIdStr FROM `tree_node` WHERE `treeId` = vTreeId AND `leftId` between vLeftId AND vRightId GROUP BY `treeId`; IF vTargetLeftId>vLeftId OR (vTargetLeftId < vLeftId AND vTargetRightId > vRightId) THEN SET vDiff = vTargetRightId - 1 - vRightId; UPDATE `tree_node` SET `leftId`=`leftId` +vDiff, `rightId`=`rightId` + vDiff WHERE `treeId` = vTreeId AND `leftId` between vLeftId AND vRightId; UPDATE `tree_node` SET `pid` = targetId WHERE `id`= nodeId; SET vDiff = vRightId-vLeftId+1; UPDATE `tree_node` SET `leftId`=`leftId`- vDiff WHERE `treeId` = vTreeId AND `leftId`>vRightId AND `leftId`< vTargetRightId AND NOT FIND_IN_SET(CAST(`id` as char),vGroupIdStr); UPDATE `tree_node` SET `rightId`=`rightId`- vDiff WHERE `treeId` = vTreeId AND `rightId`>vRightId AND `rightId`< vTargetRightId AND NOT FIND_IN_SET(CAST(`id` as char),vGroupIdStr); ELSE SET vDiff = vLeftId - vTargetRightId; UPDATE `tree_node` SET `leftId`=`leftId` -vDiff, `rightId`=`rightId` - vDiff WHERE `treeId` = vTreeId AND `leftId` between vLeftId AND vRightId; UPDATE `tree_node` SET `pid` = targetId WHERE `id`= nodeId; SET vDiff = vRightId-vLeftId+1; UPDATE `tree_node` SET `leftId`=`leftId`+ vDiff WHERE `treeId` = vTreeId AND `leftId`>vTargetRightId AND `leftId`< vRightId AND NOT FIND_IN_SET(CAST(`id` as char),vGroupIdStr); UPDATE `tree_node` SET `rightId`=`rightId`+ vDiff WHERE `treeId` = vTreeId AND `rightId`>=vTargetRightId AND `rightId`< vRightId AND NOT FIND_IN_SET(CAST(`id` as char),vGroupIdStr); END IF; COMMIT; SET resultCode = 1000; SET resultMsg = "成功"; END3.删除
删除的原理:
得到要删除节点的左右值,并得到他们的差再加一,@mywidth = @rgt - @lft + 1;
删除左右值在本节点之间的节点
修改条件为大于本节点右值的所有节点,操作为把他们的左右值都减去@mywidth
只允许删除叶子节点,如需删除叶子节点,先移动该节点不叶子节点,然后删除
ExitLabel:BEGIN DECLARE vLeftId INT; DECLARE vRightId INT; DECLARE aff INT; /*影响记录条数*/ DECLARE af INT DEFAULT 0; /*影响记录总条数*/ SELECT `leftId`,`rightId` INTO vLeftId,vRightId FROM `tree_node` WHERE `id` = nodeId; IF vLeftId IS NULL THEN LEAVE ExitLabel; END IF; IF vLeftId=1 THEN LEAVE ExitLabel; END IF; START TRANSACTION; DELETE FROM `tree_node` WHERE `leftId` between vLeftId AND vRightId; SELECT ROW_COUNT() INTO aff; SET af = aff+af; UPDATE `tree_node` SET `leftId`=`leftId`-(vRightId-vLeftId+1) WHERE `treeId` = vTreeId AND `leftId`>vLeftId; SELECT ROW_COUNT() INTO aff; SET af = aff+af; UPDATE `tree_node` SET `rightId`=`rightId`-(vRightId-vLeftId+1) WHERE `rightId`>vLeftId; SELECT ROW_COUNT() INTO aff; SET af = aff+af; IF af >= 2 THEN COMMIT; ELSE ROLLBACK; END IF; END调用如下存储过程实现更新和插入
BEGIN DECLARE a VARCHAR(30); DECLARE b VARCHAR(30); DECLARE c VARCHAR(30); DECLARE str VARCHAR(300); DECLARE x int; DECLARE s int default 0; DECLARE cursor_name CURSOR FOR select pid,id,leapfrogLeaderCode from tmpLst; DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET s=1; set str = "--"; OPEN cursor_name; fetch cursor_name into a,b,c; while s <> 1 do set str = concat(str,x); call addTreeNode(a ,b,c); fetch cursor_name into a,b,c; end while; CLOSE cursor_name ; select str; END总的调用次序
call showTreeNodes_yongyupost2000('FXGG0001');
TRUNCATE tree_node ;
call addTreeRootNode('FXGG0001');
call add_test() 由于移动的代码比较晦涩难懂,我们采用的是tree_node定时trancate,重新生成的方式,周期为一天一次。参考资料:
应用mysql数据库设计无限级分类表
mysql存储过程实现的无限级分类,前序遍历树(本文的代码主要参考该文章)SQL Server存储层级数据实现无限级分类
一个带存储过程的无限级分类数据库设计
[原创]另类非递归的无限级分类(存储过程版)

相关文章推荐
- 项目视频讲解_基于SpringSecurity3.x, JasperReport5.x等技术实现仿金蝶权限管理的企业信息管理系统
- 基于SpringSecurity3.x, JasperReport5.x等技术实现仿金蝶权限管理的企业信息管理系统
- 基于SpringSecurity3.x, JasperReport5.x等技术实现仿金蝶权限管理的企业信息管理系统
- Acegi+hibernate 动态实现基于角色的权限管理
- 基于RBAC模型的权限管理系统的设计和实现
- 基于角色的访问控制'的权限管理的数据库的设计实现
- 基于RBAC的权限管理系统的实现--经典
- php+mysql实现无限级分类 | 树型显示分类关系
- Acegi+hibernate 动态实现基于角色的权限管理
- 基于面向对象的权限管理系统设计与实现[1]
- MOSS字段编辑权限控制方案的实现(1)-管理页面的开发和配置信息的持久化
- 基于Spring.net、Nhibernate、Attribute的面向切面的权限管理实现
- 基于面向对象的权限管理系统设计与实现
- MOSS字段编辑权限控制方案的实现(1)-管理页面的开发和配置信息的持久化
- 基于RBAC的权限管理系统的实现
- Acegi+hibernate 动态实现基于角色的权限管理
- 基于RBAC模型的权限管理系统的设计和实现
- Spring框架下实现基于组的用户权限管理
- Web应用中基于组的用户权限管理在Spring框架下的实现
- 基于web信息管理系统的权限设计分析和总结