文本处理三剑客之grep
2016-08-07 00:03
141 查看
文本处理三剑客之grep
正则表达式(regex)文本处理工具grepegrep试验环境:CentOS 7.2正则表达式
Linux的哲学之一“一切皆文件”,学习Linux应得掌握其基本的文本处理工具,这些工具主要包括:文件内容:less和cat 文件截取:head和tail 文件抽取:cut 关键字搜索:grep正则表达式是计算机科学中的一个概念,又称作regex或RE, 正则表达式诞生于对神经网络研究的需要,随着技术发展,正则表达式已经广泛应用于各个领域,其主要应用对象是文本。正则就是常规,正规的意思,由一些普通字符与元字符(metacharacters)组成,普通字符包括大小写字母和数字,而元字符则具有其特殊的含义,表示控制或通配的功能。在Linux中,支持正则表达式的程序有:grep, vim, less, nginx等,有两种类型:
基本正则表达式:BRE扩展正则表达式:ERE元字符分类:字符匹配、匹配次数,位置锚定、分组元字符简介表
| 元字符 | 定义 |
|---|---|
| \ | 字符标识符,后向引用,转义符 |
| ^ | 匹配字符串的开始位置 |
| $ | 匹配字符串的结束位置 |
| . | 匹配任意单个字符 |
| * | 贪婪模式,尽可能长的匹配,匹配前面的子表达式任意次 |
| .* | 匹配任意长度的任意单个字符 |
| + | 匹配前面的子表达式1次或多次(大于等于1) |
| ? | 匹配前面的子表达式0次或1次 |
| {n} | 匹配确定的n次 |
| {n,} | 至少匹配n次 |
| {n,m} | 至少匹配n次,最多匹配m次 |
| ? | 非贪婪模式,尽可以少地匹配所搜索到的字符串 |
| (pattern) | 匹配并获取pattern |
| [xyz] | 字符集合,匹配所包含的任意字符 |
| [^xyz] | 负值字符集合,匹配未包含的任意字符 |
| [a-z] | 字符范围集合,匹配指定范围内的任意字符 |
| [^a-z] | 负值字符范围集合,匹配任何不在范围内的任意字符 |
| \b | 位置匹配,匹配一个单词边界,指单词与空格间的位置 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车符 |
| \t | 制表符 |
| \v | 垂直制表符 |
| \s | 匹配任何一个不可见字符,包括空格,制表符等,等价于[\f\n\r\t\v] |
| \S | 匹配任何可见字符,等价于[^\f\n\r\t\v] |
| \w | 匹配下划线在内的任何单词字符,“单词”使用Unicode字符集 |
| \W | 匹配任何非单词字符 |
| \num | 引用匹配,num为一个正整数,如'(.)\1'匹配两个连续的相同字符 |
| < > | 匹配词的开始和结束 |
| ( ) | 将括号内的表达式定义为组(group),并且被正则表达式记录在内部的 变量中,可以被\1到\9的符号来引用 |
| + | 匹配1个或多个恰好在它前面的那个字符 |
| {i}{i,j} | 匹配指定数目的字符,这些字符是在它前面的表达式定义的 |
| 元字符 | 定义 |
|---|---|
| [:alpha:] | 所有字母,包括大小写 |
| [:alnum:] | 所有字母和数字 |
| [:upper:] | 所有大写字母 |
| [:lower:] | 所有小写字母 |
| [:digit:] | 所有数字 |
| [:punct:] | 所有标点符号 |
| [: space:] | 空格和Tab |
文本查看命令:cat, tac, rev
cat - concatenate files and print on the standard outputcat [OPTION]... [FILE]... tac - concatenate and print files in reversetac [OPTION]... [FILE]... rev - reverse lines of a file or filesrev [options] [file ...]cat-E: 显示行结束符$-n: 对显示出的每一行进行编号-A: 显示所有控制符-b: 非空行编号-s: 压缩连续的空行成一行
 哈哈,简洁点!
哈哈,简洁点!分页查看文件内容:more, less
more [options] file [...] -d: 显示翻页及退出标致 less: 一页一页地查看文件或STDIN输出 查看时有用的命令包括: /文本 表示搜索文本 ?文本 表示搜索文本 n/N 跳到下一个或上一个匹配 less命令是man命令使用的分页器
显示文本前或后行的内容:head, tail
headhead - output the first part of fileshead [OPTION]... [FILE]... -c #: 指定获取前#字节 -n #: 指定获取前n行 -#: 指定行数tail
tail - output the last part of files tail [OPTION]... [FILE]... -c #: 指定获取后#字节 -n #: 指定获取后n行; -n +K: 表示从第K行开始输出 -#: 指定行数 -f: 跟踪显示文件新追加的内容,常用日志监控上述命令就不单独举例了

按列抽取文件cut与合并文件paste
cut主要用途显示或删除文本中的指定字段cut命令可以显示和删除文本中的指定字段或部分,将得到的内容输出到标准输出上,注意,cut有一个重要的特性,就是按列截取与显示;另外,cut还有连接两个和多个文件的作用,如cut f1 f2 > f3 将把文件f1和f2的内容合并起来,然后通过重定向符 > 的作用将它们放入到文件f3中。常用参数-b: --bytes=LIST, 仅显示行中指定范围内的内容-c: --characters=LIST, 仅显示行中指定范围内的字符-d: --delimiter=DELIM, 指定字段的分隔符,默认的分隔符为‘TAB'-n: 与-b连用,不分割多字节字符--output-delimiter=STRING: 指定输出分割符-f: --fields=LIST,显示指定字段的内容#: 第#个字段 #,#[,#]: 离散的多个字段,如1,3,7 #-#:连续的多个字段 混合使用:如1-3,7使用示例
[root@localhost ~]# cat file1 num char 1 a 2 b 3 c [root@localhost ~]# cat file2 Name Gen liansir man xiaolei girl [root@localhost ~]# [root@localhost ~]# cut -c1-3 file2 # 打印第1到第3个字符Nam lia xia [root@localhost ~]# cut -b1-2 file1 # 打印批1到第2个字节 nu 1 2 3 [root@localhost ~]
[root@localhost ~]# head -5 /etc/passwd > passwd.min [root@localhost ~]# cat passwd.min root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@localhost ~]#截取出passwd.min中的shell类型:
[root@localhost ~]# cut -d: -f7 passwd.min # 指定某一具体字段 /bin/bash /sbin/nologin /sbin/nologin /sbin/nologin /sbin/nologin [root@localhost ~]#截取出用户名,uid与注释信息:
[root@localhost ~]# cut -d: -f1,3,5 passwd.min # 离散的多个字段 root:0:root bin:1:bin daemon:2:daemon adm:3:adm lp:4:lp [root@localhost ~]#截取出uid与家目录之间的字段,并指输出分隔符为#:
[root@localhost ~]# cut -d: -f3-6 --output-delimiter=# passwd.min # 连续字段 0#0#root#/root 1#1#bin#/bin 2#2#daemon#/sbin 3#4#adm#/var/adm 4#7#lp#/var/spool/lpd [root@localhost ~]#
paste
主要用途合并两个文件同行号的列到一行paste - merge lines of files paste [OPTION]... [FILE]...常用参数-d: --delimiters=LIST, 指定分隔符,默认用TAB.-s: 所有行合成一行显示
paste f1 f2 paste -s f1 f2使用示例
[root@localhost ~]# paste file1 file2 # 合并两个文件同行号的列到一行 num char Name Gen 1 a liansir man 2 b xiaolei girl 3 c [root@localhost ~]# paste -s file1 file2 # 合成一行显示 num char 1 a 2 b 3 c Name Gen liansir man xiaolei girl [root@localhost ~]#
分析文本的工具:wc, diff, patch, sort, uniq
wc主要用途文本数据统计wc - print newline, word, and byte counts for each filewc [OPTION]... [FILE]...wc命令用来文本的数据统计,可以计算文本的Byte数、字数和列数。常用参数-c: --bytes, --chars,字节总数-m: --chars,字符总数-l: --lines,行数-w: --words,单词总数使用示例
[root@localhost ~]# cat file1 num char 1 a 2 b 3 c [root@localhost ~]# wc file1 4 8 31 file1 [root@localhost ~]# wc -l file1 4 file1 [root@localhost ~]# wc -c file1 31 file1 [root@localhost ~]# wc -m file1 31 file1 [root@localhost ~]# wc -w file1 8 file1 [root@localhost ~]#diff主要用途比较文本
diff - compare files line by line diff [OPTION]... FILESdiff一般就是用来比较两个给定的文本的异同,且以逐行的方式(line by line) 进行扫描;如果该命令是用来比较目录,则会比较两个目录中具有相同文件名的文件,且不会对其子目录文件进行任何比较。另外,diff命令的输出被保存在一个叫“补丁”的文件中,使用 -u 选项来输出“统一的(unified) diff格式文件,最适用于补丁文件。常用参数-y: 以并列的方式显示文件的异同之外-q: 仅显示有无差异,不显示详细信息-u: 以统一合并的方式来显示文件的不同使用示例看这两个文件:
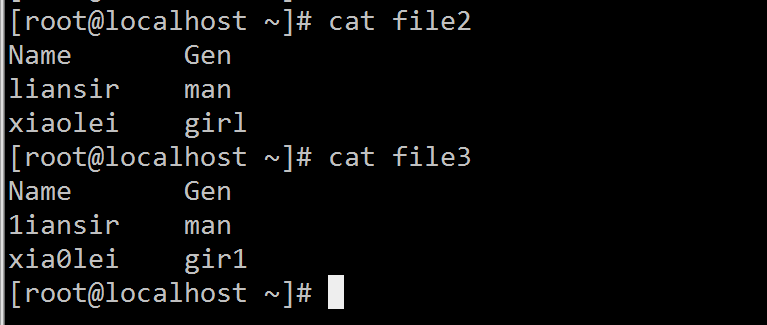 看看两个文件有何异同:
看看两个文件有何异同:[root@localhost ~]# diff file2 file3
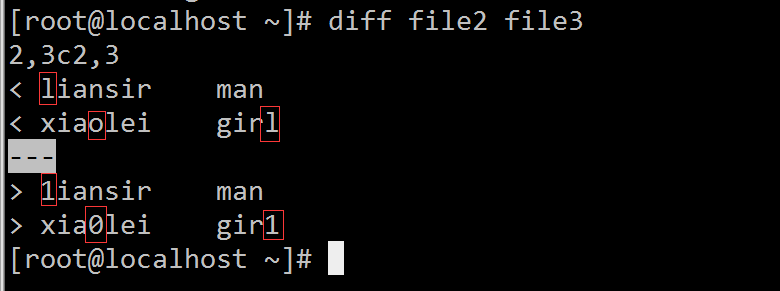
[root@localhost ~]# diff -q file2 file3 Files file2 and file3 differ [root@localhost ~]# [root@localhost ~]# diff -y file2 file3 Name Gen Name Gen liansir man | 1iansir man xiaolei girl | xia0lei gir1 [root@localhost ~]# [root@localhost ~]# diff -u file2 file3 --- file2 2016-08-06 05:06:59.809254741 -0400 +++ file3 2016-08-06 07:03:22.579524822 -0400 @@ -1,3 +1,3 @@ Name Gen -liansir man -xiaolei girl +1iansir man +xia0lei gir1 [root@localhost ~]#patch主要用途备份与安装补丁程序
patch - apply changes to files patch [-blNR][ -c| -e| -n][-d dir][-D define][-i patchfile] [-o outfile][-p num][-r rejectfile][file]patch命令可以为开放源代码程序安装补丁,一般情况下,修改一个或少量文件可下达指令依序执行,如果配合修补文件的方式则能一次修补大批文件,这是Linux系统一项重要的升级方法。常用参数-b: --backup, 备份每一个原始文件--binary: 以二进制模式读取数据,而不通过标准输出设备-u: 可将文件一差异存到其他文件中使用示例说明:patch这个命令在CentOS 7.2上能够man 出来,但运行时找不到命令,得重新安装;在CentOS 6.8上无此情况
[root@centos6 ~]# diff -u f1 f2 > f1f2.diff # -u将不同重定向到其他文件 [root@centos6 ~]# patch -b f1 f1f2.diff # -b选项是备份f1 [root@centos6 ~]#[root@centos6 ~]# ll f* -rw-r--r--. 1 root root 22 Aug 6 20:40 f1 -rw-r--r--. 1 root root 0 Aug 6 20:42 f1f2.diff -rw-r--r--. 1 root root 845 Aug 5 14:28 f1.orig # 自动生成的 -rw-r--r--. 1 root root 22 Aug 6 20:40 f2 [root@centos6 ~]#说明:如果f2丢了,可以使用f1与f1f2.diff找回f2,但是,如果在patch时没有-b,则将f1和f1f2.diff恢复f2后,会覆盖原来的f1,故这里使用-b达到同时备份f1的效果。打补丁实例:
[root@centos6 ~#]cp /etc/fstab ./fstab [root@centos6 ~#]cp fstab fstab.new [root@centos6 ~#]diff fstab fstab.new 2c2 < # # 在fstab的第二行删除了# --- > liansir # 在fstab.new的第二行增加了liansir [root@centos6 ~#] [root@centos6 ~#]diff fstab fstab.new > fstab.patch # 将两个文件的差异重定向到另一个文件 [root@centos6 ~#]patch -i fstab.patch fstab # 向原文件打补丁patching file fstab [root@centos6 ~#]diff fstab fstab.new # 原文件与新文件已无差异 [root@centos6 ~#] [root@centos6 ~#]patch -R -i fstab.patch fstab # 恢复到上一版本 patching file fstab [root@centos6 ~#] [root@centos6 ~#]diff fstab fstab.new # 成功回滚 2c2 < # --- > liansir [root@centos6 ~#]
练习一
1、找出ifconfig命令结果中本机的所有IPv4地址[root@localhost ~]# ifconfig |tr -cs '[0-9].' '\n' |sort -ut. -k3 -n
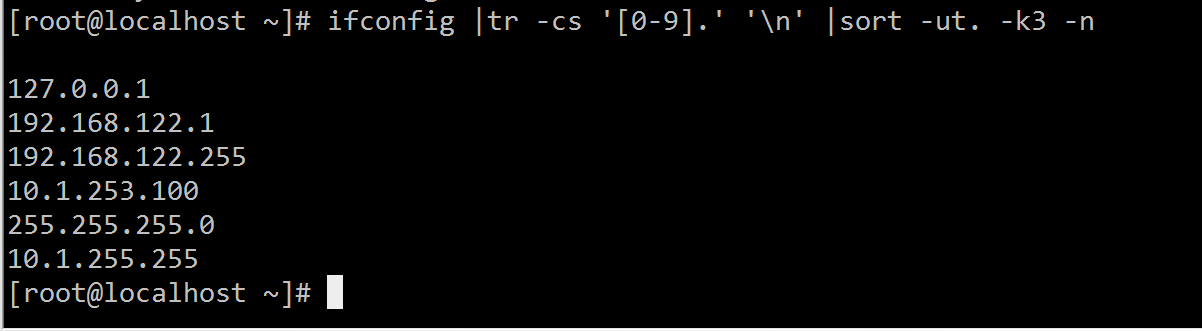 2、查出分区空间使用率的最大百分比值
2、查出分区空间使用率的最大百分比值[root@localhost ~]# df |tr -s ' ' |cut -d' ' -f5 |tr -d % |sort -r |tail -n +2 |head -n 1
 3、查出用户UID最大值的用户名、UID及shell类型.
3、查出用户UID最大值的用户名、UID及shell类型.[root@localhost ~]# getent passwd |cut -d: -f1,3,7 |sort -t: -k2 -n | tail -1
 4、查出/tmp的权限,以数字方式显示
4、查出/tmp的权限,以数字方式显示[root@localhost ~]# stat /tmp |head -4 |tail -1 |tr -s ' ' |cut -d'(' -f2 |cut -d/ -f1
或
[root@localhost ~]# stat /tmp |head -4 |tail -1 |tr ' ' '\n' |head -2 |tail -1 |tr -dc '[:digit:]'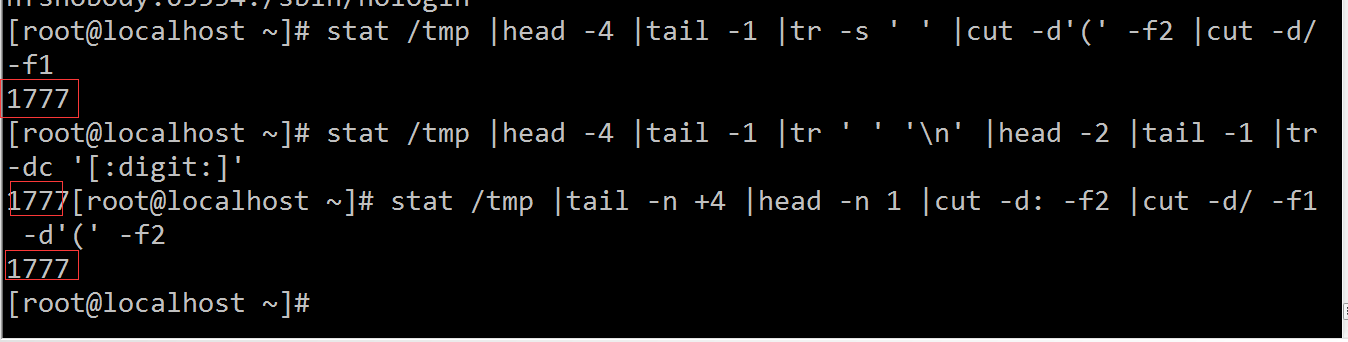 5、统计当前连接本机的每个远程主机IP的连接数,并按从大到小排序
5、统计当前连接本机的每个远程主机IP的连接数,并按从大到小排序[root@localhost ~]# netstat -nt | tr -s ' ' |cut -d' ' -f5 |tail -n +3 |cut -d: -f1 |sort -n |uniq -c

sort
主要用途排序sort - sort lines of text files sort [OPTION]... [FILE]...sort [OPTION]... --files0-from=Fsort命令主要是将文本数据排序后并打印到标准输出,sort既可从文件也可从stdin中获得输入,注意,sort排序整理后的文本只是显示在了Stdout,并未改变原文件。sort将文件的每一行作为单位进行逐行比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。主要参数-r: 反向排序-n: 按数字大小排序-f: 忽略(fold)字符串中的字符大小写-u: --unique, 删除输出中的重复行-t: --field-separator, 指定排序时的字段分隔符-k X: 按照使用字段分隔符的X列来整理能够使用多次-b: 忽略每行前面开始处的空格字符-c: 检查文件是否已经按照顺序排序-d: 排序时,只处理英文字母、数字及空格字符,忽略其它字符-m: 将几个排序号的文件进行合并-o: --output=FILE,将整理排序后的结果存到指定的文件使用示例
[root@localhost ~]# head -5 /etc/passwd > passwd.min [root@localhost ~]# cat passwd.min root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@localhost ~]#将passwd.min将uid进行反序排序:
[root@localhost ~]# sort -t: -rk3 passwd.min lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin bin:x:1:1:bin:/bin:/sbin/nologin root:x:0:0:root:/root:/bin/bash将passwd.min中的家目录截取并转换成大写,且逆序排序并输出到另一文件:
[root@localhost ~]# cut -d: -f7 passwd.min |tr '[:lower:]' '[:upper:]' |sort -r -o minpasswd.bak [root@localhost ~]# cat minpasswd.bak /SBIN/NOLOGIN /SBIN/NOLOGIN /SBIN/NOLOGIN /SBIN/NOLOGIN /BIN/BASH [root@localhost ~]#
uniq
主要用途去重uniq - report or omit repeated lines uniq [OPTION]... [INPUT [OUTPUT]]uniq命令主要作用就是删除重复的前后相接的行。常用参数-c: --count, 显示每行重复出现的次数-d: 仅显示重复过的行-u: 仅显示不曾重复的行注:连续且完全相同广为重复!常和sort命令一起配合使用:sort userlist.txt | uniq -c
grep
主要用途文本搜索工具grep, egrep, fgrep - print lines matching a pattern grep [OPTIONS] PATTERN [FILE...] grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索并过滤文本,并把匹配的行打印出来( By default, grep prints the matching lines.)常用参数-a: --test,--binary-files=text option, 不要忽略二进制数据-A #: --after-context, 后#行-B #: --before-context, 前#行-C #: --context, 前后各#行-c: 统计匹配的行数-n: 显示匹配的行号-q: 静默模式,不输出任何信息-i: 忽略字符大小写-v: 显示不能够pattern匹配到的行-w: 整行匹配整个单词--color=auto: 对匹配到的文本着色-e: 实现多个选项之间的逻辑或关系-E: 使用ERE
练习二:正则表达式
1、显示/proc/meminfo文件中以大小s开头的行;(要求:使用两种方式)[root@localhost ~]# grep -i ^s /proc/meminfo或 [root@localhost ~]# grep -e '^s' -e '^S' /proc/meminfo
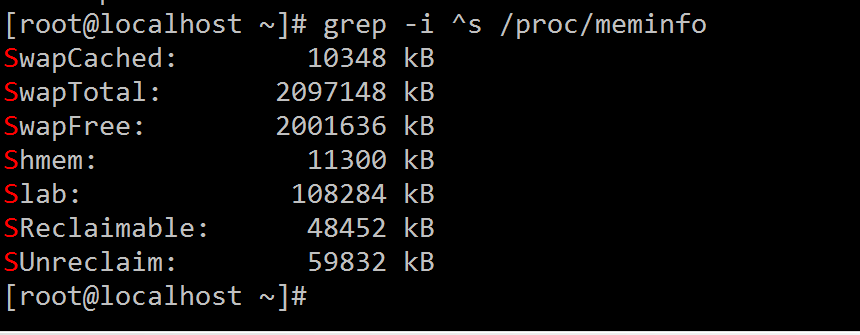 2、显示/etc/passwd文件中不以/bin/bash结尾的行
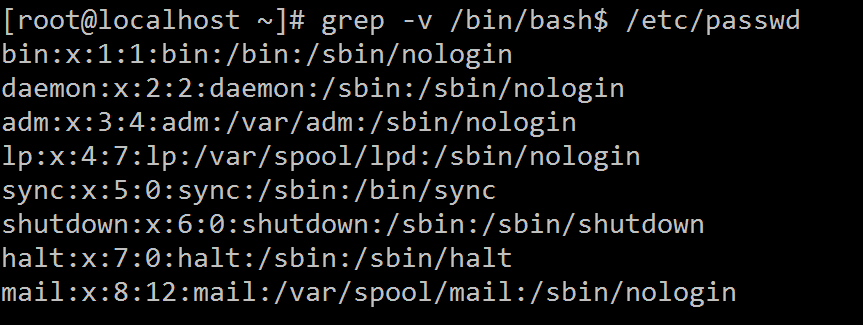
2、显示/etc/passwd文件中不以/bin/bash结尾的行[root@localhost ~]# grep -v /bin/bash$ /etc/passwd
 3、显示用户rpc默认的shell程序
3、显示用户rpc默认的shell程序[root@localhost ~]# grep '^rpc\>' /etc/passwd |cut -d: -f7 /sbin/nologin 或 [root@localhost ~]# grep -w '\<rpc\>' /etc/passwd |cut -d: -f7 /sbin/nologin [root@localhost ~]# 或 [root@localhost ~]# grep '\brpc\b' /etc/passwd |cut -d: -f7 /sbin/nologin [root@localhost ~]#4、找出/etc/passwd中的两位或三位数
[root@localhost ~]# cat /etc/passwd |tr -cs '[:digit:]' '\n' |grep '\b[0-9][0-9][0-9]\?\b'
或
[root@localhost ~]# getent passwd |tr -cs '[:digit:]' '\n' |grep '\b[0-9]\{2,3\}\b' 5、显示/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面存非空白字符的行这是一个:^'开头' 与 '^非'的练习
5、显示/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面存非空白字符的行这是一个:^'开头' 与 '^非'的练习[root@localhost ~]# grep '^[[:space:]]\+[^[:space:]]' /etc/grub2.cfg
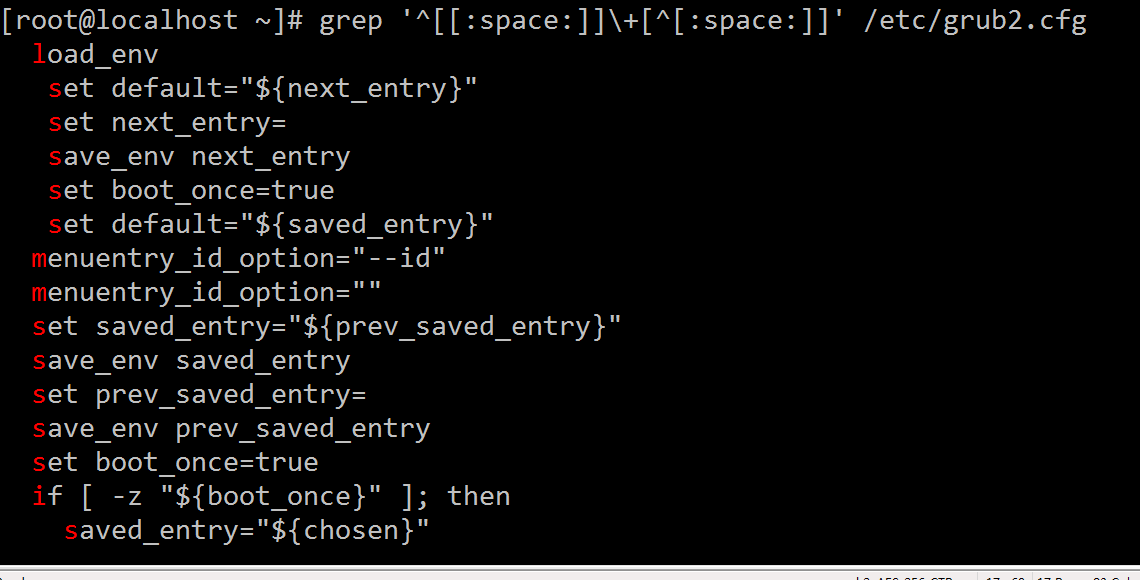 6、找出“netstat -tan”命令的结果中以‘LISTEN’后跟任意多个空白字符结尾的行
6、找出“netstat -tan”命令的结果中以‘LISTEN’后跟任意多个空白字符结尾的行netstat -tan |grep '\<LISTEN\>[[:space:]]*$'
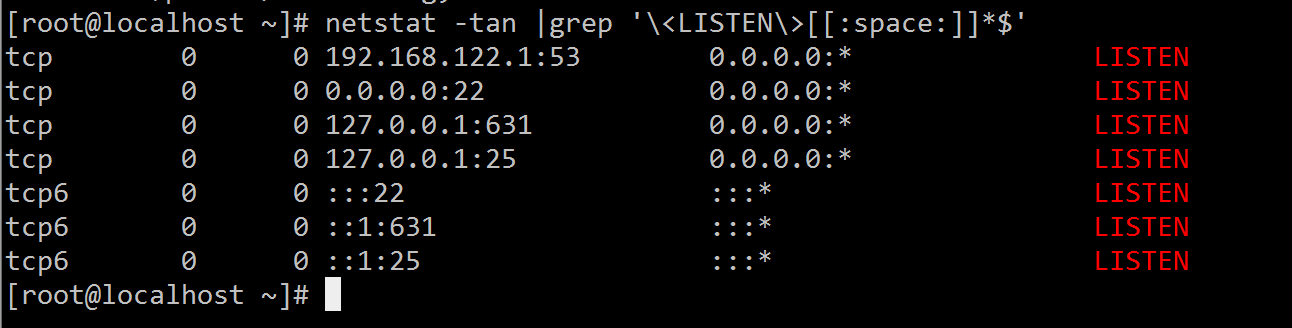 7、添加用户bash、testbash、basher以及nologin(其shell为/sbin/nologin),而后找出/etc/passwd文件中用户名同shell名的行
7、添加用户bash、testbash、basher以及nologin(其shell为/sbin/nologin),而后找出/etc/passwd文件中用户名同shell名的行[root@localhost ~]# grep '^\<\(.*\)\>.*/\1$' /etc/passwd
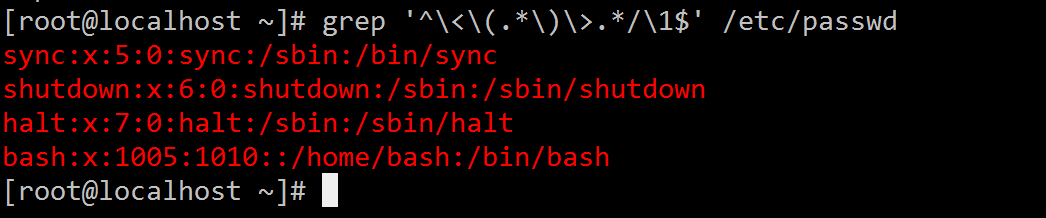
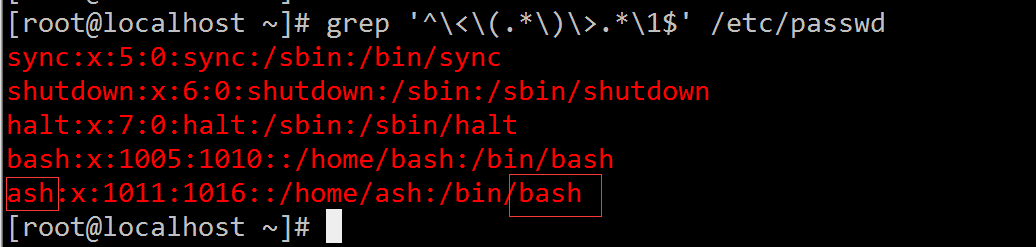
[root@localhost ~]# grep '^\<\(.*\)\>.*\1$' /etc/passwd # (这各做法有问题) [root@localhost ~]# grep '^\<\(.*\)\>.*\1$' /etc/passwd sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt bash:x:1005:1010::/home/bash:/bin/bash [root@localhost ~]#虽然此处结果是没问题的,但是当我们添加一个用户ash后,就有问题了。
练习三:扩展正则表达式
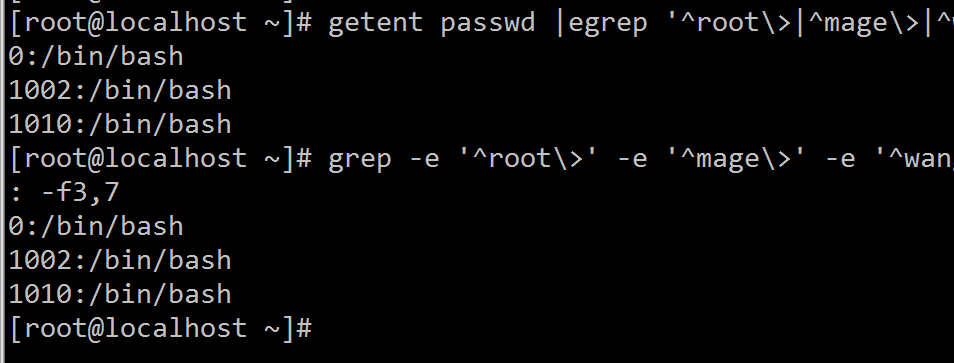
1、显示三个用户root、mage、wang的UID和默认shell[root@localhost ~]# getent passwd |egrep '^root\>|^mage\>|^wang\>' |cut -d: -f3,7 或 [root@localhost ~]# grep -e '^root\>' -e '^mage\>' -e '^wang\>' /etc/passwd |cut -d: -f3,7
 2、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一个小括号的行
2、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一个小括号的行[root@localhost ~]# egrep '^[[:alnum:]_]+\(\)' /etc/rc.d/init.d/functions 或[root@localhost ~]# egrep '^[[:alnum:]]+\(\)|^_*.*+\(\)' /etc/rc.d/init.d/functions
 扩展:该文件下以_开头且后面有括号的行:
扩展:该文件下以_开头且后面有括号的行:[root@localhost ~]# egrep '^_.*+\(\)' /etc/rc.d/init.d/functions
__pids_var_run() {
__pids_pidof() {
[root@localhost ~]#3、使用egrep取出/etc/rc.d/init.d/functions中其基名[root@localhost ~]# basename /etc/rc.d/init.d/functions # 专门取基名 functions [root@localhost ~]# echo '/etc/rc.d/init.d/functions' |egrep -o '[^/]+/?$' functions [root@localhost ~]#4.使用egrep取出/etc/rc.d/init.d/functions或/etc/rc.d/init.d/functions/的目录名5.统计以root身份登录的每个远程主机IP地址的登录次数
[root@localhost ~]# last |tr -s ' ' |cut -d' ' -f1,3 |egrep '^root\> ([0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3})' |sort -n |uniq -c24 root 10.1.250.373 root 192.168.1.1011 root 192.168.1.105[root@localhost ~]#6.利用扩展正则表达式分别表示0-9、10-99、100-199、200-249、250-255[0-9]、[1-9][0-9]、1[0-9]{2}、2[0-4][0-9]、25[0-5]7.显示ifconfig命令结果中所有IPv4地址[root@localhost ~]# ifconfig |egrep -o '\<[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\>'10.1.253.100255.255.0.010.1.255.255127.0.0.1255.0.0.0192.168.122.1255.255.255.0192.168.122.255[root@localhost ~]#老王的加餐题:待续

相关文章推荐
- Linux文本处理三剑客之grep和sed
- linux文本处理三剑客之grep
- Linux 系统中文本处理“三剑客”之grep
- Linux文本处理三剑客(grep)
- 第七章 Shell文本处理三剑客之grep
- 正则表达式与文本处理三剑客之一:grep和egrep
- 文本处理三剑客之grep(包括常用正则表达式)
- Linux文本处理三剑客之grep及正则表达式
- Linux文本处理“三剑客”之grep
- shell脚本之正则表达和文本处理(文本处理三剑客:1、grep 2、sed 3、awk)
- Linux文本处理三剑客之grep一族与正则表达式
- linux文本处理三剑客——grep
- 01-shell文本处理三剑客之grep
- Linux文本处理三剑客之grep
- Linux文本处理三剑客之grep
- Linux_ 文本处理三剑客中的“大宝剑“―Grep家族
- Linux基础(9)文本处理三剑客之grep
- Linux文本处理三剑客之grep详解
- Linux 系统中文本处理“三剑客”之grep
- 文本处理三剑客之-grep