[Paper Reading] Attention to Scale: Scale-aware Semantic Image Segmentation
2016-08-02 11:54
519 查看
Motivation:
Multi-scale features对性能的提升是非常大的。做Multi-scale一般是两个思路:skip-net和share-net

skip-net的思路是将各个中间层的特征都结合进来,不同层带来的特征用来做多尺度
share-net的思路就比较简单粗暴,不同尺度的图片都输入到网络进去,再将得到的特征结合起来
那么,就涉及到一个问题了,怎么结合?
Solution:
直观的,有Max-pooling和Average-pooling。这里,作者提出了一个加权和,也就是:
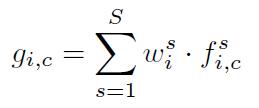
其中,w是权重,f是不同尺度的特征,g是结合后的结果。而Max-pooling和Average-pooling是这个公式的两种特殊情况。
看到这个公式我的第一反应是,用一个卷积来训练w?
当然作者想的比较多,采用了一种data-driven的方法,通过一个attention model来训练这里的权重。
所以简单来说,这篇文章做的事情只是把多尺度特征用加权组合起来而已
Attention Model:
注意力模型模拟的是我们看一张图片,会把注意力放在哪块区域。这里,作者认为,不同尺寸的图片,我们会把注意力放在不同的地方
比如,比较小的图片,我们就会把注意力放在较大的区域(这个是有道理的)。比较大的图片,我们会把注意力放在比较小的东西(这个我就不敢苟同了)。
在实现上,他的attention model是一个两层卷积结构,第一个卷积层有512个3*3的卷积核,第二个卷积层有S个1*1的卷积核(S是尺度数,也就是不同尺寸输入图片数)。
Network Architecture:
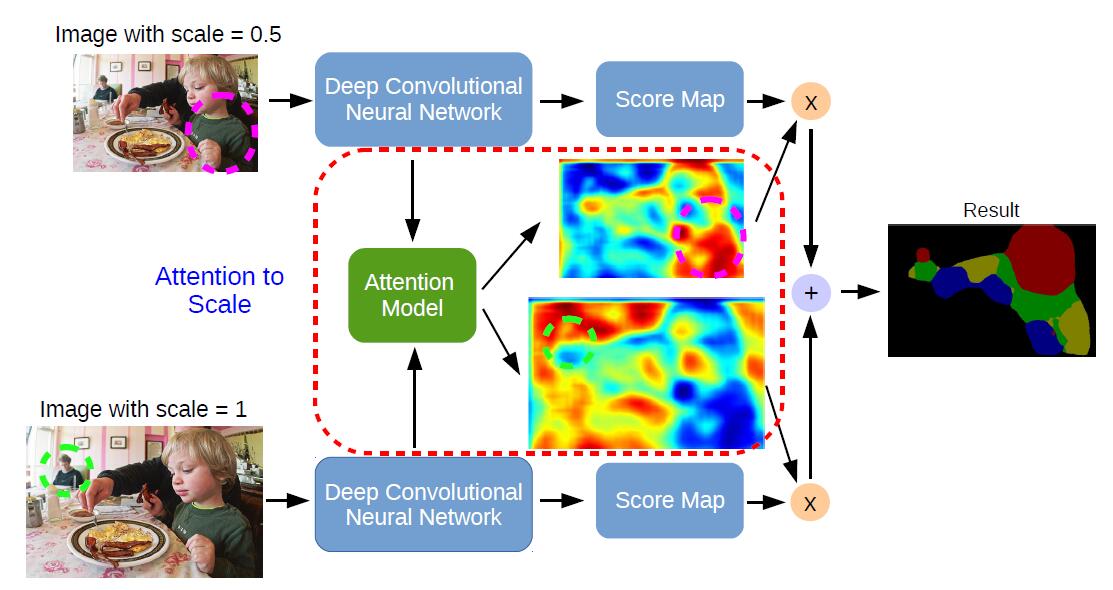
不看虚线框起来的attention model,其实就是用 FCN 提取两个不同Size图片的特征,然后结合起来。
细分下去:
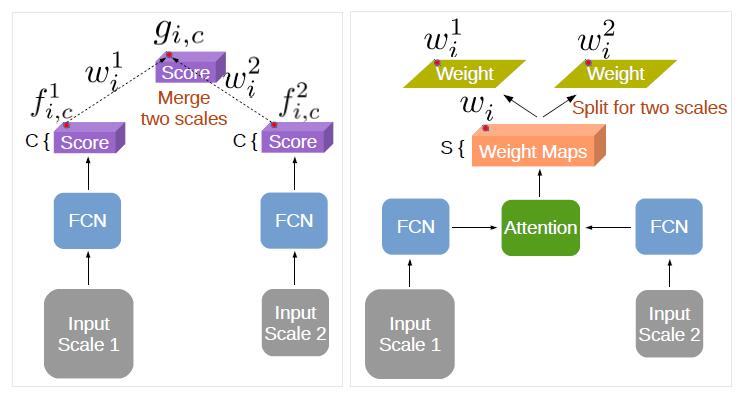
FCN 的fc7形成分支。一方面,传给fc8作为score map ,另一方面,传输给这个attention model(也就是我们刚才说的两层卷积结构),
来得到weight map,再对这两个weight map做一个softmax得到weight
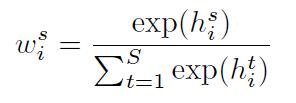
h是weight map
然后再如前面所说,加权和一下,就得到最后我们想要的包含多尺度信息的特征了
这里,文章中虽然没说,但我觉得传入attention model前,两个fc7应该要resize到相同尺寸
Experiment:
作者做了三个尺度,原尺寸,0.75和0.5,。0.25因为效果太差放弃了。

第二行是max-pooling得到的weight map,第三行是他的attention model学出来的weight map,确实不同尺度关注的东西不大一样,scale最小的关注的就是比较大的比如背景
Multi-scale features对性能的提升是非常大的。做Multi-scale一般是两个思路:skip-net和share-net
skip-net的思路是将各个中间层的特征都结合进来,不同层带来的特征用来做多尺度
share-net的思路就比较简单粗暴,不同尺度的图片都输入到网络进去,再将得到的特征结合起来
那么,就涉及到一个问题了,怎么结合?
Solution:
直观的,有Max-pooling和Average-pooling。这里,作者提出了一个加权和,也就是:
其中,w是权重,f是不同尺度的特征,g是结合后的结果。而Max-pooling和Average-pooling是这个公式的两种特殊情况。
看到这个公式我的第一反应是,用一个卷积来训练w?
当然作者想的比较多,采用了一种data-driven的方法,通过一个attention model来训练这里的权重。
所以简单来说,这篇文章做的事情只是把多尺度特征用加权组合起来而已
Attention Model:
注意力模型模拟的是我们看一张图片,会把注意力放在哪块区域。这里,作者认为,不同尺寸的图片,我们会把注意力放在不同的地方
比如,比较小的图片,我们就会把注意力放在较大的区域(这个是有道理的)。比较大的图片,我们会把注意力放在比较小的东西(这个我就不敢苟同了)。
在实现上,他的attention model是一个两层卷积结构,第一个卷积层有512个3*3的卷积核,第二个卷积层有S个1*1的卷积核(S是尺度数,也就是不同尺寸输入图片数)。
Network Architecture:
不看虚线框起来的attention model,其实就是用 FCN 提取两个不同Size图片的特征,然后结合起来。
细分下去:
FCN 的fc7形成分支。一方面,传给fc8作为score map ,另一方面,传输给这个attention model(也就是我们刚才说的两层卷积结构),
来得到weight map,再对这两个weight map做一个softmax得到weight
h是weight map
然后再如前面所说,加权和一下,就得到最后我们想要的包含多尺度信息的特征了
这里,文章中虽然没说,但我觉得传入attention model前,两个fc7应该要resize到相同尺寸
Experiment:
作者做了三个尺度,原尺寸,0.75和0.5,。0.25因为效果太差放弃了。
第二行是max-pooling得到的weight map,第三行是他的attention model学出来的weight map,确实不同尺度关注的东西不大一样,scale最小的关注的就是比较大的比如背景

相关文章推荐
- Attention to Scale: Scale-Aware Semantic Image Segmentation论文阅读笔记
- 语义分割--Attention to Scale: Scale-aware Semantic Image Segmentation
- [paper] Attention to Scale
- [Flexbox] Use Flex to Scale Background Image
- 论文笔记:A Review on Deep Learning Techniques Applied to Semantic Segmentation
- Convolutional Networks for Image Semantic Segmentation
- FCN-for-semantic-image-segmentation 训练过程的一些坑记录_0
- [译]Rethinking Atrous Convolution for Semantic Image Segmentation
- Semantic Segmentation -- (DeepLabv1)Semantic image segmentation with deep convolutional ... CRFs论文解读
- #Paper Reading# Multi-Document Summarization via Sentence-Level Semantic Analysis and SMF
- 论文笔记--STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation
- FCN-for-semantic-image-segmentation 训练过程的一些坑记录
- FCN-for-semantic-image-segmentation 训练过程的一些坑记录
- #Paper Reading# Learning to Segment Object Candidates
- DeepLab V3 —— Semantic Image Segmentation
- 【Paper Note】Very Deep Convolutional Network For Large-Scale Image Recognition 论文翻译(VGG)
- 【Review】A Review on Deep Learning Techniques Applied to Semantic Segmentation
- 【Paper Reading】A Few Useful Things to Know about Machine Learning【机器学习那些事】
- 两篇关于用DL做Semantic Image Segmentation的文章
- Some paper related to Image Deblurring