概率图模型学习(一):概率图矩阵分解
2016-07-30 09:40
211 查看
最近在学习概率图模型,将所学知识根据自己的理解分享一下,因为初学,如果理解不到位,或者太简单,望理解。
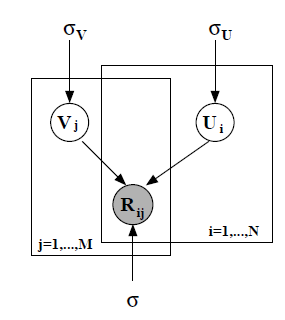
实际上就是将R矩阵分解为U,V矩阵的乘积,假设R,U,V都是服从正态分布,并作以下假设即:
Rij∼N(UTiVj,σ2)Ui∼N(0,σ2UI)Vj∼N(0,σ2VI)
P(U,V|R)∼P(U)P(V)P(R|U,V)
为了清楚表示,省略了超参数的表示(σ2,σ2U,σ2V),实际上根据贝叶斯公式应该是:
P(U,V|R)=P(U)P(V)P(R|U,V)P(R)
但P(R)和我们要得到的U,V,在进行统计推断时可以忽略。对后验概率取log得到损失函数:
logP(U,V|R)=logP(U)+logP(V)+logP(R|U,V)+C
然后根据朴素贝叶斯假设
logP(U)logP(V)logP(R|U,V)=∑i=1N(UTiUi2σ2U)+CU=∑i=1M(VTiVi2σ2V)+CV=∑i=1N∑i=1MIij2σ2(Rij−UTiVj)2+CR
这里的CU,CV,CR都是常数,因此得到:
E=12∑i=1N∑i=1MIij(Rij−UTiVj)2+λU2∑i=1N∥Ui∥2+λV2∑i=1M∥Vi∥2
然后惊讶的发现,这不就是矩阵分解的目标函数嘛。进一步可以看到,如果直接用极大似然估计,而不是最大后验概率,那得到的就是上面公式等式右边第一项,即没有正则化项,所以为何贝叶斯学习可以有效防止过拟合,道理就在这里
概率矩阵分解(probabilistic matrix factorization)
建模与表示
实际上就是将R矩阵分解为U,V矩阵的乘积,假设R,U,V都是服从正态分布,并作以下假设即:
Rij∼N(UTiVj,σ2)Ui∼N(0,σ2UI)Vj∼N(0,σ2VI)
统计推断
这里运用最大后验概率推理,和极大似然估计挺像,只不过是对后验概率的最大化,实际上也是一种点估计的方法,运用贝叶斯公式:P(U,V|R)∼P(U)P(V)P(R|U,V)
为了清楚表示,省略了超参数的表示(σ2,σ2U,σ2V),实际上根据贝叶斯公式应该是:
P(U,V|R)=P(U)P(V)P(R|U,V)P(R)
但P(R)和我们要得到的U,V,在进行统计推断时可以忽略。对后验概率取log得到损失函数:
logP(U,V|R)=logP(U)+logP(V)+logP(R|U,V)+C
然后根据朴素贝叶斯假设
logP(U)logP(V)logP(R|U,V)=∑i=1N(UTiUi2σ2U)+CU=∑i=1M(VTiVi2σ2V)+CV=∑i=1N∑i=1MIij2σ2(Rij−UTiVj)2+CR
这里的CU,CV,CR都是常数,因此得到:
E=12∑i=1N∑i=1MIij(Rij−UTiVj)2+λU2∑i=1N∥Ui∥2+λV2∑i=1M∥Vi∥2
然后惊讶的发现,这不就是矩阵分解的目标函数嘛。进一步可以看到,如果直接用极大似然估计,而不是最大后验概率,那得到的就是上面公式等式右边第一项,即没有正则化项,所以为何贝叶斯学习可以有效防止过拟合,道理就在这里

相关文章推荐
- 统计学习(一)--统计学习的定义及常识
- 多项式分布的理解概率公式的理解
- 统计学习方法---朴素贝叶斯法
- 统计学习方法-----k近邻法
- 统计学习那些事
- 《统计学习方法》学习笔记(3.1)---对偶问题
- 统计量MAD
- 经典算法(4):K最近邻算法(KNN)
- 线性回归与贝叶斯推理——漫谈机器学习
- 统计学习方法——绪论
- Statistical learning Week 3 线性回归
- C++ 朴素贝叶斯模型(Naive Bayesian Model,NBM)实现, 西瓜实验数据集 基于周志华老师机器学习
- 机器学习三要素
- 统计学习方法 7-支持向量机
- 统计学习方法 6-逻辑斯谛回归与最大熵模型
- 统计学习方法 5-决策树
- 统计学习方法 4-朴素贝叶斯法
- 统计学习方法 2-感知机模型
- 统计学习方法 1-统计学习方法概论
- 最大似然估计(MLE)和最大后验概率(MAP)