数据结构与算法总结5_查找算法
2016-07-29 15:36
316 查看
0.
在这一篇博客里主要介绍二分查找,二叉查找树,平衡查找树(红黑树)以及散列表(哈希表)。平衡查找树(也就是红黑树)是二叉查找树的改进版本,如果想把红黑树介绍清楚的话,会花很长很长的篇幅,所以在这里可能只是对红黑树做一个简要的介绍。
我对查找的一个很浅显的认识:如果你现在面临着一个查找任务,而你又对此一筹莫展。先进行排序然后再去查找,结果总不会太差的。
1.二分查找
我如果没记错的话,在初中数学中,我们就已经接触过二分查找了。问题如下:如果现在有一组已经排好序的数字,我们怎么最快的找到某个数?先对这组数的中间那个数字和我们需要查找的数字进行比较,根据比较结果,选择在左半部分或者右半部分继续进行查找。就这样不断的折半折半,最后找到我们寻找的数。
根据二叉树的概念,很容易想到二分查找所需要的时间是和二叉树的树高成正比的(二叉查找的过程可以想象成在一颗平衡的二叉查找树上进行查找(关于二叉查找树在后面进行介绍),最坏情况所需的比较次数是树高次)。所以二分查找的时间复杂度是 O(lgN)。
需要注意:二分查找有一个比较强的限制,待查找数组必须是有序的。
代码实现:
int rank_digui(int key,int a[],int lo,int hi)
//递归版本
//返回a[lo]和a[hi]之间的元素为key的索引。
{
if(hi<lo)
return -1; //没有找到
int mid=lo+(hi-lo)/2;
if(a[mid]>key)
return rank_digui(key,a,lo,mid-1);
else if(a[mid]<key)
return rank_digui(key,a,mid+1,hi);
else
return mid;
}
int rank_feidigui(int key,int a[],int lo,int hi)
//非递归(迭代)版本
{
while(lo<=hi)
{
int mid=lo+(hi-lo)/2;
if(a[mid]>key)
{
hi=mid-1;
}
else if(a[mid]<key)
{
lo=mid+1;
}
else
return mid;
}
return -1; //没有找到
}2.二叉查找树
先对二叉查找树进行定义,每个节点都含有一个值,一个左链接和一个右链接。不同于普通的二叉树,二叉查找树的节点的左链接指向一棵由小于该节点的值的所有节点组成的二叉查找树,右链接指向一棵由大于该节点的值的所有节点组成的二叉查找树。简单来说,左边所有节点的值都小于该节点的值,右边所有节点的值都大于该节点的值。这条规则对二叉查找树中所有节点都是成立的。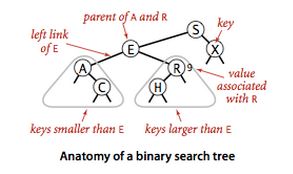
如果使用二叉查找树进行查找的话,我们首先需要面临的一个问题就是如何建立一棵二叉查找树。这个建树的过程很简单的,如果通过语言去描述这个过程,会显得很冗余,所以我们通过代码将这个过程描述出来。
代码实现:
//包括建立一个二叉查找树,以及在二叉查找树上实现查找。
//这只是最简单的为了表达二叉查找树的思想的一种实现。
#include<stdio.h>
#include<stdlib.h>
typedef int ElemType;
typedef struct Node
{
ElemType data;
Node* lchild;
Node* rchild;
}Node;
Node* Insert(Node* T, ElemType e)
//插入新的元素
{
if (T==NULL)
{
T=(Node*)malloc(sizeof(Node));
T->data=e;
T->lchild=NULL;
T->rchild=NULL;
return T;
}
if ((T->data) > e)
T->lchild=Insert(T->lchild,e);
else if((T->data) < e)
T->rchild=Insert(T->rchild,e);
else //这时e已经存在树中,不进行再次插入了
return T;
return T;
}
Node* Search(Node* T,ElemType e)
//查找,返回节点值为e的节点
{
if (T==NULL)
return NULL;
if(T->data > e)
return Search(T->lchild,e);
else if(T->data < e)
return Search(T->rchild,e);
else
return T;
}
void show(Node *root)
//增序显示树的节点值
{
if(root==NULL)
return;
show(root->lchild);
printf("%d\n",root->data);
show(root->rchild);
}
int main()
{
//建立一棵二查查找树
Node *root=NULL;
int count;
int e;
scanf("%d",&count);
for (int i=0;i<count;i++)
{
scanf("%d",&e);
root=Insert(root,e);
}
show(root);
//查找
Node *temp=Search(root,4);
printf("%d\n",temp->data);
}这里你可能会发现二叉查找树的形状和插入顺序有关:
同样一组数据,调整插入顺序,生成的二叉查找树是不一样的。这一点和快速排序非常像。
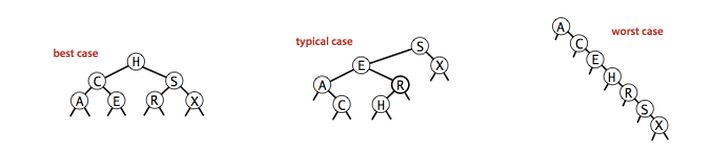
我们进行查找的时候,算法的运行时间和树的形状有着密切的关系。在最好的情况下,一棵含有N个节点的树是完全平衡的,查找某个元素所需要经过的节点最多为lgN。在最坏情况下,我们查找某个元素时,所需要经过的节点可能会有N个。
之前所说的二分查找,就可以看成在最好情况下的二叉查找树,最多只需要经过lgN个节点。
二叉查找树虽然说已经不错了,但是在最坏情况下性能还是非常糟糕。我们希望保证二分查找树的平衡性,以保证它在最坏情况下,所有的查找都可以在lgN次比较内完成。
这就是平衡查找树。红黑树是一种平衡查找树。
一棵大小为N的红黑树的高度不会超过2lgN。
一棵大小为为N的红黑树中,根节点到任意节点的平均路径长度为~lgN。
如果想把红黑树介绍清楚的话,会花很长很长的篇幅。而且因为红黑树的复杂,感觉在笔试面试中不太可能出现。这里就不做具体的介绍了,如果对此有兴趣的话,自行百度红黑树,有非常多的博客对其做了详细的介绍。
3.散列表(哈希表)
如果所有的值都是小整数,将该值作为数组的索引(数组的第i个位置里面存的就是整数i),这样我们就可以快速查找某个数。举个例子,如果我们将整数100存在a[100]中,如果我们再想查找100时,直接通过a[100]就可以找到了。可是事实不总是像我们想的那么美好。如果我们需要存放100000000这个数,我们不可能构造一个100000000那么大的数组只为了存放100000000这个数。哈希表就是通过某种方式将所有整数转换成某个范围之内的整数,作为数组索引进行存储。
这里所说的某种方式是指哈希函数。一般所采用的哈希函数都很简单,例如:对于任意正整数k,计算k除以M的余数。我们需要采用大小为M的数组存储需要存储的所有整数,M通常为素数。
可以想一下,通过这种方式可能产生一个问题,碰撞(如果有两个数字对M取余之后的值相同),这时应该怎么办? 碰撞处理是构建哈希表需要解决的主要问题。
题外话:我在硕士期间所研究的方向就是哈希算法,所以我对哈希表有着很强烈的亲切感。不过我所做的哈希算法比这里的哈希表复杂的多。主要是对图片进行编码,将图片根据语义信息编成一组二进制编码。通过二进制编码,就可以实现语义相似的图片之间的快速检索。
有两种不同的方式可以解决冲突。一种是基于拉链法的哈希表,另外一种是基于线性探测法的散列表。现在分别对此进行介绍。
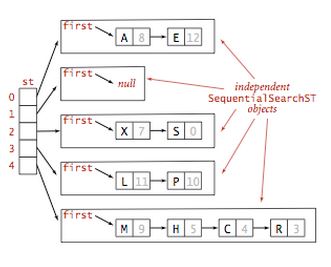
基于拉链法的哈希表
思路很简单,数组的每个元素是一个链表。如果发生碰撞,那就向链表后面添加一个元素。我们使用M条链表保存N个值。通常情况下,每条链表包含N/M个节点。
对于这种实现的哈希表,有一点好处是数组的大小M并不是问题的关键。如果向数组中存入多于预计的值,查找所需的时间只是比选择更大的数组稍长。
下面这幅图片,可以大概描述出基于拉链法的哈希表的思想。
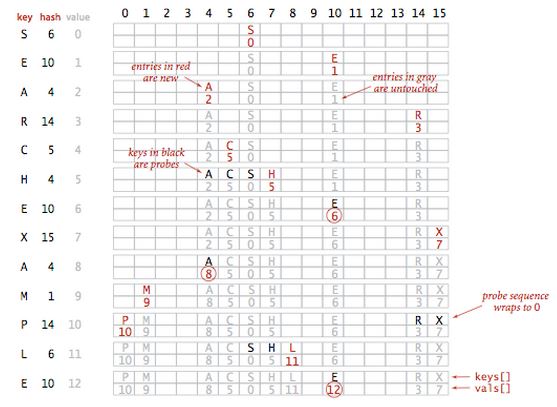
基于线性探测法的散列表
通过这种方式建立哈希表的时候,如果发生碰撞,就会检查下一个位置是否有空位,直到遇到空位,才把值存进去。
用大小为M的数组保存N个值,其中M>N,利用其中的空位解决碰撞冲突。我们计算某个值在数组中的索引,检查这个索引所对应的值和我们需要查找的值是否相同。如果不同则继续查找(到达数组尾则折回到数组的开头),直到找到该值或者遇到一个空元素。这些空元素作为查找结束的标志,如果以空元素结束的话,代表该值不存在。
这种方法有一个要求,要保证数组中的空位足够多,才能保证查找的性能。如果数组中没有空位,那进行查找的时候就会陷入一个无限死循环。通常需要保证数组的使用率不超过50%。如果达到50%时,就需要动态调整数组大小了。这个要求是很容易理解的。
下面这幅图片,可以大概描述出基于线性探测法的哈希表的思想。(稍微有点小出入)

相关文章推荐
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- C#数据结构之顺序表(SeqList)实例详解
- C#递归算法之分而治之策略
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- C#算法之大牛生小牛的问题高效解决方法
- Lua教程(七):数据结构详解
- C#算法函数:获取一个字符串中的最大长度的数字
- 解析从源码分析常见的基于Array的数据结构动态扩容机制的详解
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- C#数据结构之队列(Quene)实例详解
- C#数据结构揭秘一
- C#数据结构之单链表(LinkList)实例详解
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- 经典排序算法之冒泡排序(Bubble sort)代码