spark HashShuffleManager调优
2016-07-29 00:00
239 查看
shuffle调优概述
大多数Spark作业的性能主要就是消耗在了shuffle环 节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优。但是也 必须提醒大家的是,影响一个Spark作业性能的因素,主要还是代码开发、资源参数以及数据倾斜,shuffle调优只能在整个Spark的性能调优中占 到一小部分而已。因此大家务必把握住调优的基本原则,千万不要舍本逐末。下面我们就给大家详细讲解shuffle的原理,以及相关参数的说明,同时给出各 个参数的调优建议。
ShuffleManager发展概述
在Spark的源码中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager。该ShuffleManager而HashShuffleManager有着一个非常严重的弊端,就是会产生大量的中间磁盘文件,进而由大量的磁盘IO操作影响了性能。
因此在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。SortShuffleManager相较于 HashShuffleManager来说,有了一定的改进。主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件,但 是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
未优化的HashShuffleManager
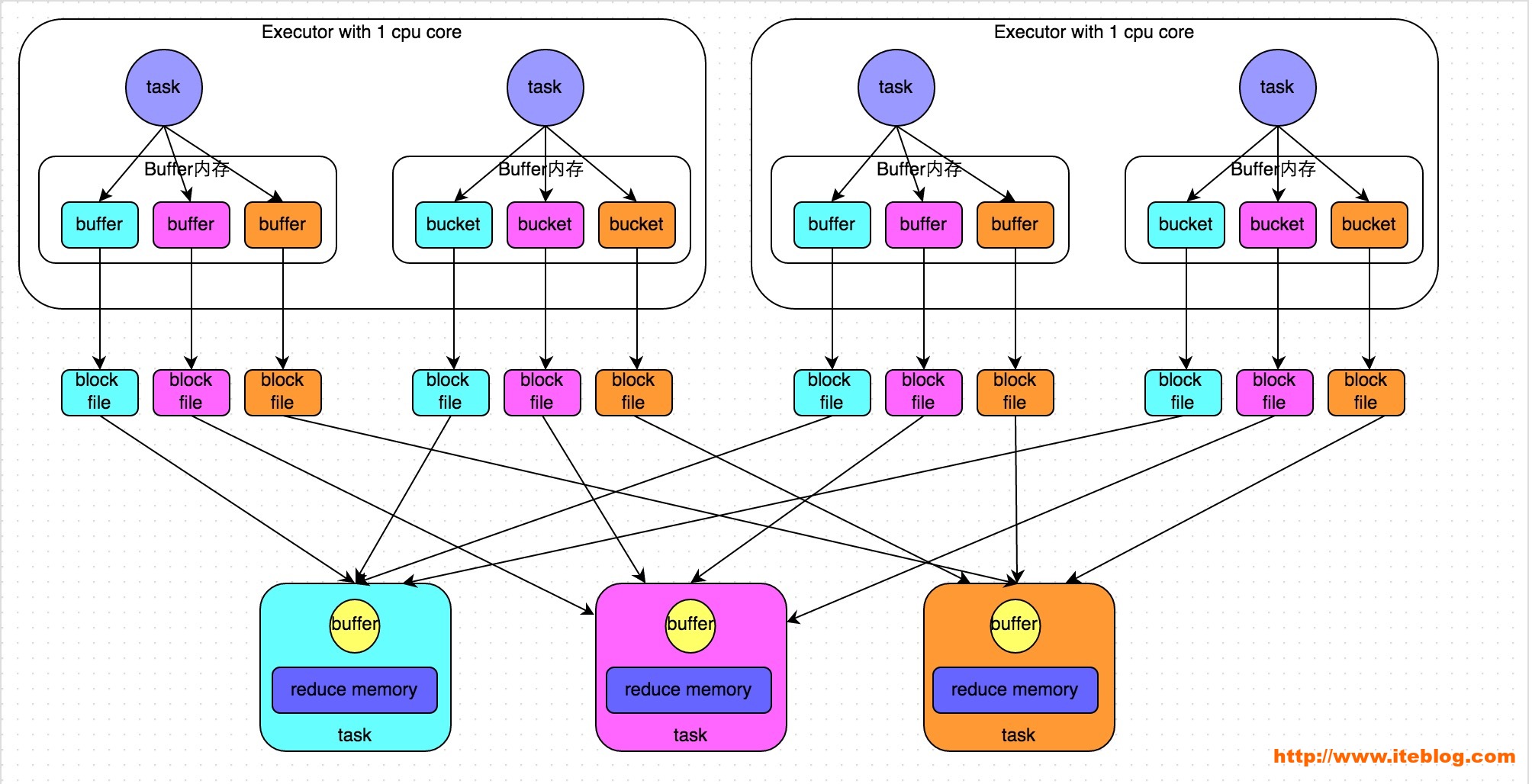
图说明了未经优化的HashShuffleManager的原理。这里我们先明确一个假设前提:每个Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task线程,同一时间都只能执行一个task线程。
shuffle write:shuffle write阶段就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey),而将每个 task处理的数据按key进行“分类”。也就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
那么每个执行shuffle write的task,要为下一个stage创建多少个磁盘文件呢?下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。比如下一个stage总共有100个task,那么当前stage的每个task都要创建100份磁盘文件。如果当前stage有50个 task,则总共会建立5000个磁盘文件。由此可见,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
shuffle read:shuffle read,通常就是一个stage刚开始时要做的事情。此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个 节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,task给下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数 据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
优化后的HashShuffleManager
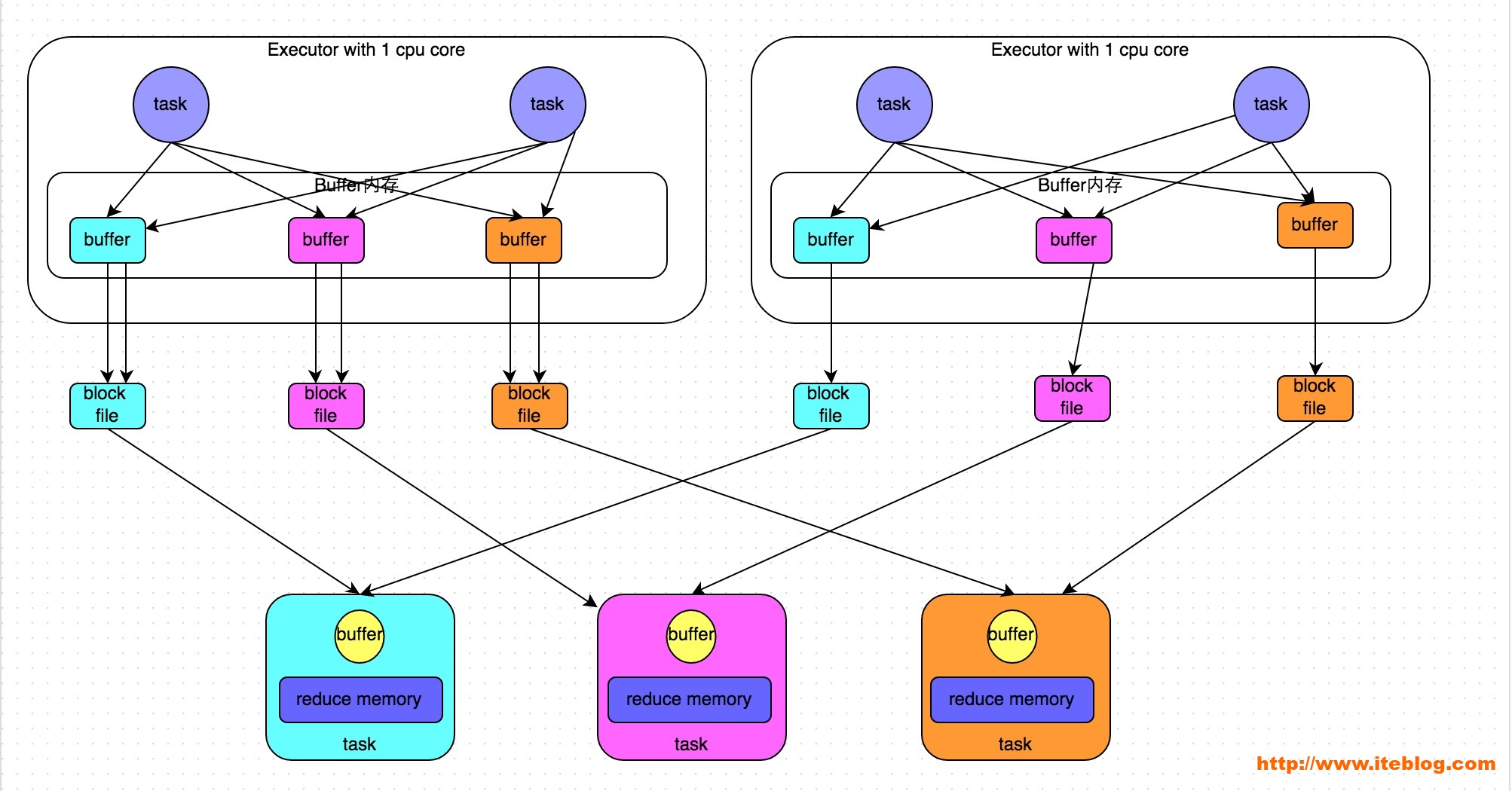
图说明了优化后的HashShuffleManager的原理。这里说的优化是指我们可以设置一个参数,spark.shuffle.consolidateFiles=true。该参数默认值为false,通常来说如果我们使用HashShuffleManager,那么都建议开启这个选项。
开启consolidate机制之后,在shuffle write过程中,task不会为下游stage的每个task创建一个磁盘文件,此时会出现shuffleFileGroup的概念,每个 shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。一个Executor上有多少个CPU core,就可以并行执行多少个task。而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。
当Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,包括其中的磁盘文件。也就是说task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。 这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
优化与未优化对比
假设第一个stage有 50个task, 第二个stage有100个task,总共还是有10个Executor(CPU核心数),每个Executor执行5个task。
未经优化的HashShuffleManager:每个Executor会产生500个磁盘文件,所有Executor会产生5000个磁盘文件的。
每个Executor创建的磁盘文件: 单个Executor执行task数 * 下一个stage的task数量 (5*100)
所有Executor创建的磁盘文件: 当前stage的task数 * 下一个stage的task数量 (50*100)
优化之后的HashShuffleManager: 每个Executor此时只会创建100个磁盘文件,所有Executor只会创建1000个磁盘文件。
每个Executor创建的磁盘文件:单个Executor CPU核心数量 * 下一个stage的task数量 (1*100)
所有 Executor创建的磁盘文件: 所有Executor CPU核心数量 * 下一个stage的task数量(10*100)
大多数Spark作业的性能主要就是消耗在了shuffle环 节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优。但是也 必须提醒大家的是,影响一个Spark作业性能的因素,主要还是代码开发、资源参数以及数据倾斜,shuffle调优只能在整个Spark的性能调优中占 到一小部分而已。因此大家务必把握住调优的基本原则,千万不要舍本逐末。下面我们就给大家详细讲解shuffle的原理,以及相关参数的说明,同时给出各 个参数的调优建议。
ShuffleManager发展概述
在Spark的源码中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager。该ShuffleManager而HashShuffleManager有着一个非常严重的弊端,就是会产生大量的中间磁盘文件,进而由大量的磁盘IO操作影响了性能。
因此在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。SortShuffleManager相较于 HashShuffleManager来说,有了一定的改进。主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件,但 是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
未优化的HashShuffleManager
图说明了未经优化的HashShuffleManager的原理。这里我们先明确一个假设前提:每个Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task线程,同一时间都只能执行一个task线程。
shuffle write:shuffle write阶段就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey),而将每个 task处理的数据按key进行“分类”。也就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
那么每个执行shuffle write的task,要为下一个stage创建多少个磁盘文件呢?下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。比如下一个stage总共有100个task,那么当前stage的每个task都要创建100份磁盘文件。如果当前stage有50个 task,则总共会建立5000个磁盘文件。由此可见,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
shuffle read:shuffle read,通常就是一个stage刚开始时要做的事情。此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个 节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,task给下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数 据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
优化后的HashShuffleManager
图说明了优化后的HashShuffleManager的原理。这里说的优化是指我们可以设置一个参数,spark.shuffle.consolidateFiles=true。该参数默认值为false,通常来说如果我们使用HashShuffleManager,那么都建议开启这个选项。
开启consolidate机制之后,在shuffle write过程中,task不会为下游stage的每个task创建一个磁盘文件,此时会出现shuffleFileGroup的概念,每个 shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。一个Executor上有多少个CPU core,就可以并行执行多少个task。而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。
当Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,包括其中的磁盘文件。也就是说task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。 这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
优化与未优化对比
假设第一个stage有 50个task, 第二个stage有100个task,总共还是有10个Executor(CPU核心数),每个Executor执行5个task。
未经优化的HashShuffleManager:每个Executor会产生500个磁盘文件,所有Executor会产生5000个磁盘文件的。
每个Executor创建的磁盘文件: 单个Executor执行task数 * 下一个stage的task数量 (5*100)
所有Executor创建的磁盘文件: 当前stage的task数 * 下一个stage的task数量 (50*100)
优化之后的HashShuffleManager: 每个Executor此时只会创建100个磁盘文件,所有Executor只会创建1000个磁盘文件。
每个Executor创建的磁盘文件:单个Executor CPU核心数量 * 下一个stage的task数量 (1*100)
所有 Executor创建的磁盘文件: 所有Executor CPU核心数量 * 下一个stage的task数量(10*100)

相关文章推荐
- 第23课:Spark旧版本中性能调优之HashShuffle剖析及调优
- 【spark】HashShuffleManager解析
- 《Spark商业案例与性能调优实战100课》第25课:Spark Hash Shuffle源码解读与剖析
- shuffle性能调优之HashShuffleManager和SortShuffleManager
- 第23课:Spark旧版本中性能调优之HashShuffle剖析及调优(内含大数据Shuffle本质及其思考)
- [Spark性能调优] 第二章:彻底解密Spark的HashShuffle
- Shuffle 调优之 HashShuffleManager 和 SortShuffleManager
- spark新能优化之shuffle新能调优
- 《Spark商业案例与性能调优实战100课》第35课:彻底解密Spark 2.1.X中Sort Shuffle中TimSort排序源码具体实现
- 四、Spark性能优化:shuffle调优
- Spark性能优化:shuffle调优
- Spark性能优化--数据倾斜调优与shuffle调优
- Spark性能优化:shuffle调优
- Spark源码学习1.8——ShuffleBlockManager.scala
- spark-调优-shuffle
- Spark性能优化:shuffle调优
- 四、Spark性能优化:shuffle调优
- Spark性能优化:shuffle调优
- Spark技术内幕:Shuffle的性能调优
- Spark技术内幕:Shuffle的性能调优