Hadoop:HDFS的数据复制
2016-07-28 10:23
176 查看
Hadoop认证培训:HDFS的数据复制,HDFS被设计成在一个大集群中可以跨机器可靠地存储海量的文件。它将每个文件存储成Block序列,除了最后一个Block,所有的Block都是同样的大小。文件的所有Block为了容错都会被冗余复制存储。每个文件的Block大小和Replication因子都是可配置的。
Replication因子在文件创建的时候会默认读取客户端的HDFS配置,然后创建,以后也可以改变。HDFS中的文件是write-one,并且严格要求在任何时候只有一个writer。HDFS数据冗余复制示意图如3-6图所示。
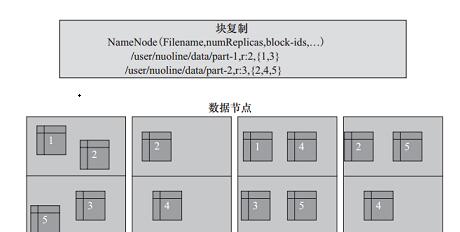
从图3-6中可以看到,文件/user/nuoline/data/part-1的复制因子Replication值是2,块的ID列表包括1和3,可以看到块1和块3分别被冗余备份了两份数据块;文件/user/nuoline/data/part-2的复制因子Replication值是3,块的ID列表包括2、4、5,可以看到块2、4、5分别被冗余复制了三份。在HDFS中,文件所有块的复制会全权由NameNode进行管理,NameNode周期性地从集群中的每个DataNode接收心跳包和一个Blockreport。心跳包的接收表示该DataNode节点正常工作,而Blockreport包括了该DataNode上所有的Block组成的列表。来源:CUUG官网
Replication因子在文件创建的时候会默认读取客户端的HDFS配置,然后创建,以后也可以改变。HDFS中的文件是write-one,并且严格要求在任何时候只有一个writer。HDFS数据冗余复制示意图如3-6图所示。
从图3-6中可以看到,文件/user/nuoline/data/part-1的复制因子Replication值是2,块的ID列表包括1和3,可以看到块1和块3分别被冗余备份了两份数据块;文件/user/nuoline/data/part-2的复制因子Replication值是3,块的ID列表包括2、4、5,可以看到块2、4、5分别被冗余复制了三份。在HDFS中,文件所有块的复制会全权由NameNode进行管理,NameNode周期性地从集群中的每个DataNode接收心跳包和一个Blockreport。心跳包的接收表示该DataNode节点正常工作,而Blockreport包括了该DataNode上所有的Block组成的列表。来源:CUUG官网

相关文章推荐
- Hadoop:HDFS文件存取机制
- 使用官方 docker registry 搭建私有镜像仓库及部署 web ui
- Hadoop:HDFS的Master/Slave架构
- 刚学习shell,碰到问题.执行时总出错:unexpected operator
- 【嵌入式学习日记】2016年7月28日
- linux下源码安装R-3.1.2.tar.gz和RStudio开发工具
- Thrift架构简介
- Linux iostat监测IO状态
- [Linux] 管道容量以及缓冲区的组成
- 调用fwrite函数向一个文件写入十六进制数据时,当写入值为0x0A时,其前面总是加上一个0x0D
- Hadoop MapReduce概念学习系列之shuffle大揭秘(十九)
- 为了 SHELL脚本开发汉诺塔游戏 部分草稿 shell建立二维数组并打印
- 商网站截断盲打后台客服
- Linux中history详解
- 浅谈mysql主从复制的高可用解决方案
- centos7.2编译安装gcc-4.9.2
- ubuntu安装tomcat
- Linux夜间模式(f.lux)
- 负载均衡集群解决方案 Nginx
- linux常用管理命令