hadoop入门级总结三:hive
2016-07-26 19:48
363 查看
认识hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务运行Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
因此,可以看到,hadoop中诸如hdfs和map/reduce更多是为编程开发人员设计的一套系统,而hive则是提供给数据分析人员的一套工具。
当然,开发人员也可以利用Hive快速实现数据的查询、聚合等功能,避免自己去实现复杂的map/reduce接口和繁琐易错的作业提交过程。
hive架构说明
下图是一个hive的系统架构图: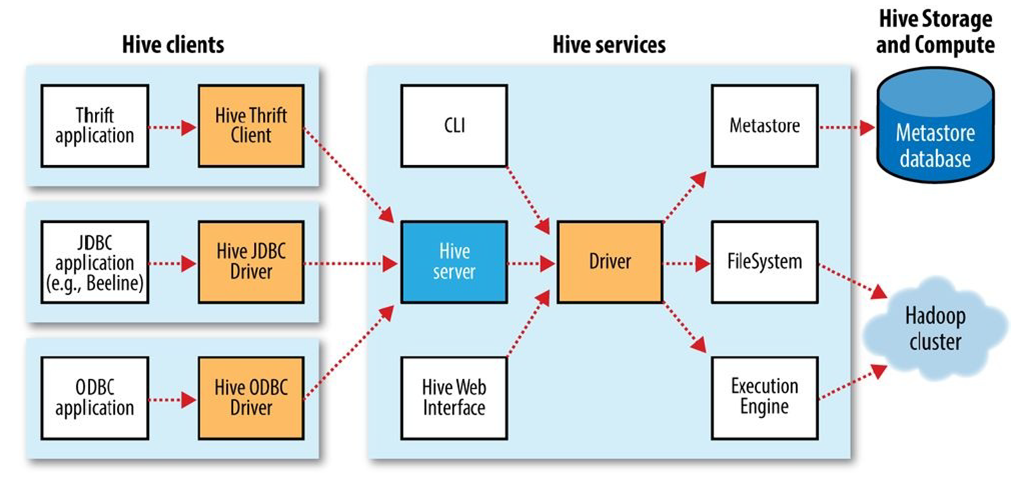
可以看到,hive架构可以简单的概括为3个组成部分:
hive客户端程序,用户通过客户端程序提交查询语句给hive服务器。包括3中类型的客户端:thrift客户端用来对任意的开发语言提供任务提交的接口,JDBC客户端用来对java程序提交查询任意,ODBC开放数据库接口等。
hive服务器:hive服务器的核心是hive驱动,hive驱动包括解释器、编译器和优化器,用户通过hive客户端提交HQL或者命令行提交的HQL会经过hive驱动的处理之后形成具体的可执行任务,才会提交至map/reduce运行。
hive的元数据存储、数据存储、分布式计算:这一部分都是hive借助外部的组件完成的,一般而言,hive的元数据存储是借助mysql来完成的(当然可以使用hive内置的deby数据库,使用外部数据库会更稳定一点),hive的业务数据是存储在hdfs上,计算则是借助hadoop的map/reduce。
因此,hive其实是一个桥梁或者翻译官的角色,来将熟悉sql查询分析的人员和hadoop的海量存储和计算能力衔接起来。
hive CLI与HQL
hive CLI及hive命令行,是hive与用户交互过程中非常方便的根据,进入hive安装目录的bin目录运行./hive即可进入hive CLI 交互模式。在这里可以执行一些常见的如数据库创建、建表、计算、查询的一些操作。下面罗列一些HQL常用的一些命令:
建数据库:CREATE DATABASE csdn;
建表:CREATE TABLE test_t (foo INT, bar STRING);
创建分区表:CREATE TABLE test_t (foo INT, bar STRING) PARTITIONED BY (ds STRING);
查看表:SHOW TABLES;
导入数据:LOAD DATA LOCAL INPATH ‘/u.data’
OVERWRITE INTO test_t PARTITION (ds=’20160729’);
查看数据:SELECT * FROM test_t LIMIT 10;
聚合数据:SELECT COUNT(*) FROM test_t
删除表:DROP TABLE test_t;
还有很多其他的HQL命令,可以参考apach hive的官方文档进行学习。
hive自定义函数
对于一些复杂的查询逻辑(如字符串处理、复杂计算等),需要我们自己编写hive的处理函数,并在查询中使用。在此,简单的总结一下hive自定义函数的类型、编写、提交等内容Hive自定义函数:
Hive自定义函数包括3中类型UDF、UDAF、UDTF。
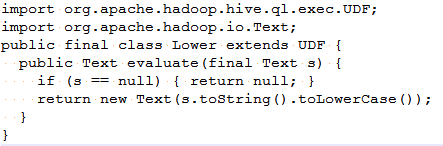
UDF(user-defined function),普通的用户自定义函数,接受单行输入并产生单行输出。如字符串的大写转小写就输入这一类型。
编写UDF需要继承UDF类、并实现evaluate()方法
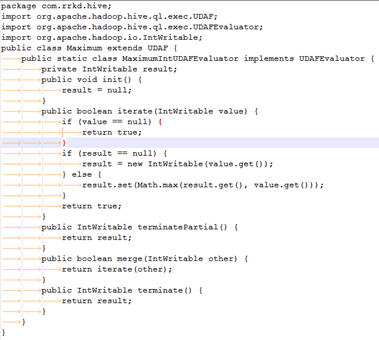
UDAF(User-defined aggregate function):用户自定义聚合函数、接受多行输入并产生单行输出,如max、min都输入这一类。
编写UDAF稍微复杂一点,需要继承UDAF类,内部类实现UDAFEvaluator接口,实现 init()方法 完成参数的初始化,实现iterate()方法 接受输入,并进行内部轮转,实现terminatePartial()方法 返回子区域聚合结果,实现nerge()方法完成子区域结果的合并,实现terminate()返回最终聚合结果。
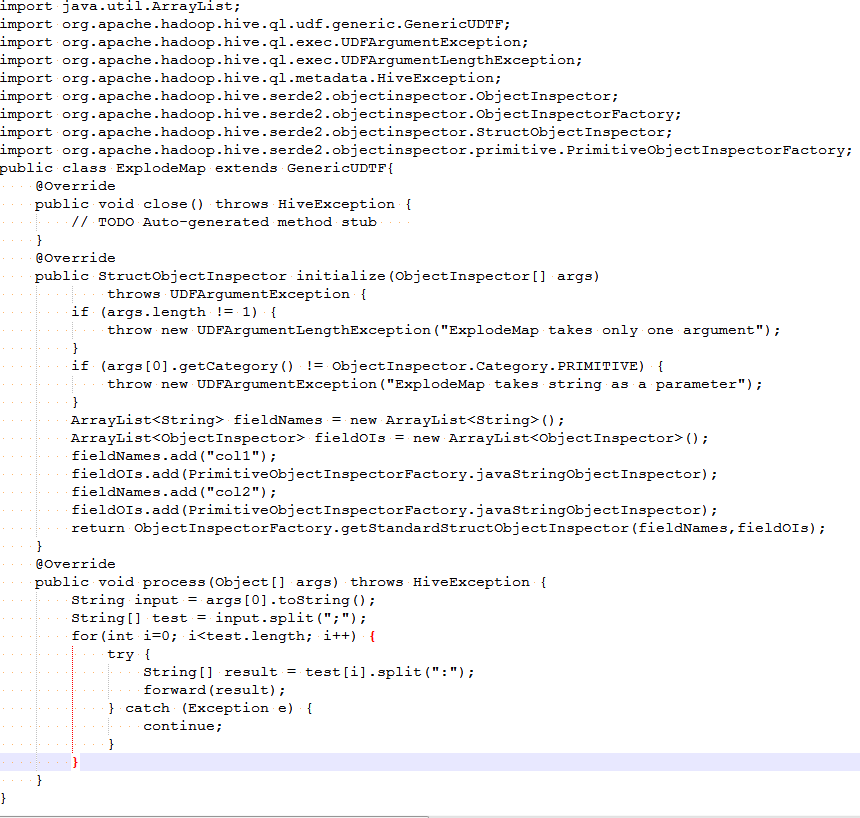
UDTF(User-defined table-generating function):用户自定义表生成函数,接受单行输入并产生多行输出。
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF。
实现initialize, process, close三个方法
UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。初始化完成后,会调用process方法,对传入的参数进行处理,可以通过forword()方法把结果返回。最后close()方法调用,对需要清理的方法进行清理。
写的一个用来切分”key:value;key:value;”这种字符串,返回结果为key, value两个字段
Hive用户自定义函数的提交:
编写好的UDF、UDAF、UDTF编译为jar包之后,需要提交给hive才能使用。提交包括3个过程:
通过命令行提交jar包: hive –auxpath /path/to/hive-examples.jar
注册临时函数: CREATE TEMPORARY FUNCTION maximum AS ‘Maximum’
使用自定义函数:select maximum(score) from score_table group by studentId
至此,hive的一些主要功能特性、架构设计介绍完了。其它的如HQL的编写,当然还得需要在实践中结合文档逐渐学习,在此不再赘述。
下一篇,将会对hbase做一些简单的介绍。

相关文章推荐
- hadoop入门级总结三:hive
- CentOS服务器最新分区方案
- CentOS下查看MySQL的安装路径
- Linux特殊权限
- Centos 文件和目录访问权限设置
- Linux帮助
- Linux wget命令
- Centos下软件的安装与卸载方法
- Linux服务器安装配置tomcat
- drop table中cascade的含义及用法
- Linux-(C)多线程学习(入门)
- CentOS7下Firewall防火墙配置用法详解
- 网站服务化
- 网站服务化
- 网站服务化
- Ubuntu系统下配置Hadoop2.7.1+Hive2.1.0
- CentOS7.0重置Root的密码
- js获取网站域名
- linux环境下同时使用静态库、动态库编译程序
- CentOS从入门到精通系列之PPTP