Faster rcnn代码解析
2016-07-24 15:59
676 查看
最近工作需要,对faster rcnn的代码进行了研究。faster rcnn中除开常规的神经网络部分之外,最终要的部分应该是数据的读取和组织,论文中提到的anchor的生成,以及如何使用这些anchor去进行loss的计算,pooling layer也是一个custom layer,, 但并不是本文的创新,在fast
rcnn中就有提到。
首先我们来看数据读取和组织的部分。faster rcnn的训练有几种方法,这里就说论文提到的第一种方法,它的训练分成多个阶段,在第一个阶段中,首先对RPN网络进行训练,然后是用第一部分产生的propasal对fast rcnn网络进行训练。
在训练RPN网络时,通过get_roidb()函数获得roidb和imdb。imdb实际指的就是图片数据,而roidb指的是图片对应的ground_truth label。imdb通过get_imdb获得,会返回一个pascal_voc对象。而roidb是通过roidb获得。roidb拥有@property装饰器,可以当做属性使用。roidb函数会调用roidb_handler,而在之前,这个handler被为gt_roidb(),它会读取所有图片的annotation.
下面看一下读取到的image和anotation是如何送到网络中去的
这是caffe的网络定义的文件有关input layer的描述,可以看到会输出data,im_info和gt_boxes三个数据。这是一个定制的python实现的layer,下面看看这个layer做了些什么。在这个layer的实现中,主要看forward()函数,它通过_get_next_minibatch()获得一个batch中的数据。这其中组织数据的逻辑是,通过之前设置的roidb中图片的index来获得对应的imdb中对应的图片数据,根据对图片数据的缩放,会对相应的label也进行调整,最后生成一个blobs。blobs中装着data,
gt_boxes和im_info这三个数据。在训练RPN net时,batchsize是1,也就是说每次只输入一个ground truth label进行训练。下图展示input layer数据的流向。

接下来我们再来看anchor的生成以及如何用anchor来计算loss。从下图可以看出,anchor是在rpn-data这一层中生成的,在AnchorTargetLayer的setup函数中,
<span style="font-size:12px;">anchor_scales = layer_params.get('scales', (8, 16, 32))</span>
首先设置anchor的缩放比例,之后来产生anchor。generate_anchors()函数产生9个不同的anchor, 对于一个大小为H*W的特征层,它上面每一个像素点对应9个anchor,这里有一个重要的参数feat_stride = 16, 它表示特征层上移动一个点,对应原图移动16个像素点(看一看网络中的stride就明白16的来历了)。把这9个anchor的坐标进行平移操作,获得在原图上的坐标。之后根据ground truth
label和这些anchor之间的关系生成rpn_lables,具体的方法论文中有提到,根据overlap来计算,这里就不详细说明了,生成的rpn_labels中,positive的位置被置为1,negative的位置被置为0,其他的为-1。box_target通过_compute_targets()函数生成,这个函数实际上是寻找每一个anchor最匹配的ground truth box, 然后进行论文中提到的box坐标的转化。
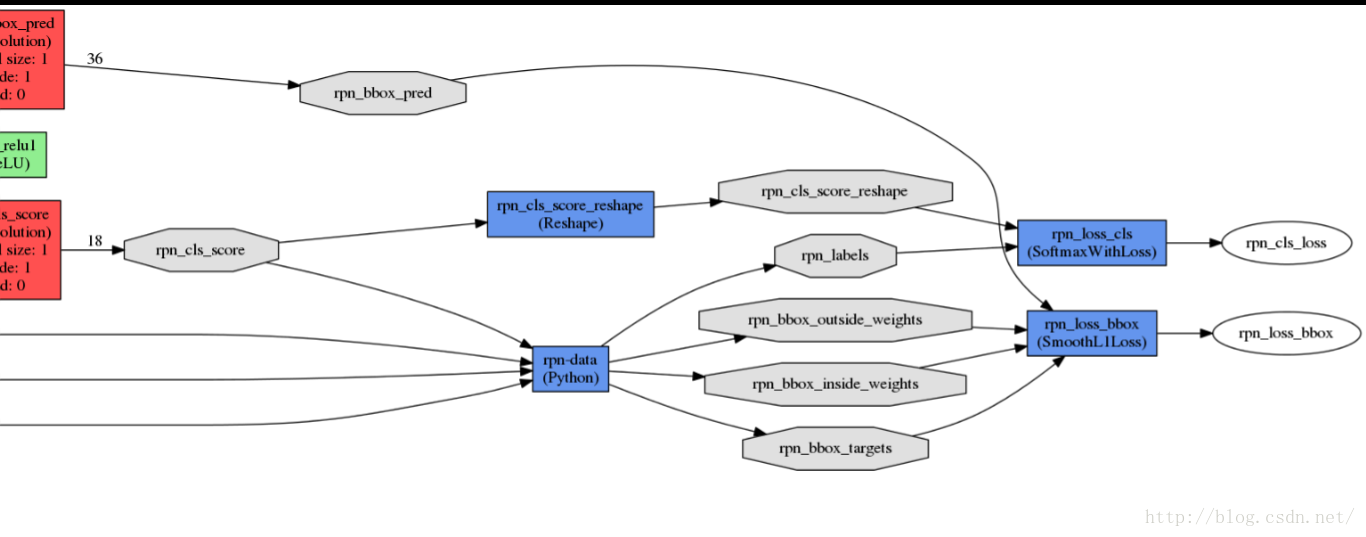
个人理解,这种设置anchor和计算box_targets的方式使网络能够学习到不同anchor预测和它相近框的能力。
rcnn中就有提到。
首先我们来看数据读取和组织的部分。faster rcnn的训练有几种方法,这里就说论文提到的第一种方法,它的训练分成多个阶段,在第一个阶段中,首先对RPN网络进行训练,然后是用第一部分产生的propasal对fast rcnn网络进行训练。
在训练RPN网络时,通过get_roidb()函数获得roidb和imdb。imdb实际指的就是图片数据,而roidb指的是图片对应的ground_truth label。imdb通过get_imdb获得,会返回一个pascal_voc对象。而roidb是通过roidb获得。roidb拥有@property装饰器,可以当做属性使用。roidb函数会调用roidb_handler,而在之前,这个handler被为gt_roidb(),它会读取所有图片的annotation.
下面看一下读取到的image和anotation是如何送到网络中去的
<span style="font-size:12px;">name: "ZF"</span>
layer {
name: 'input-data'
type: 'Python'
top: 'data'
top: 'im_info'
top: 'gt_boxes'
python_param {
module: 'roi_data_layer.layer'
layer: 'RoIDataLayer'
param_str: "'num_classes': 21"
}
}<span style="font-size:14px;">
</span>这是caffe的网络定义的文件有关input layer的描述,可以看到会输出data,im_info和gt_boxes三个数据。这是一个定制的python实现的layer,下面看看这个layer做了些什么。在这个layer的实现中,主要看forward()函数,它通过_get_next_minibatch()获得一个batch中的数据。这其中组织数据的逻辑是,通过之前设置的roidb中图片的index来获得对应的imdb中对应的图片数据,根据对图片数据的缩放,会对相应的label也进行调整,最后生成一个blobs。blobs中装着data,
gt_boxes和im_info这三个数据。在训练RPN net时,batchsize是1,也就是说每次只输入一个ground truth label进行训练。下图展示input layer数据的流向。
接下来我们再来看anchor的生成以及如何用anchor来计算loss。从下图可以看出,anchor是在rpn-data这一层中生成的,在AnchorTargetLayer的setup函数中,
<span style="font-size:12px;">anchor_scales = layer_params.get('scales', (8, 16, 32))</span>
首先设置anchor的缩放比例,之后来产生anchor。generate_anchors()函数产生9个不同的anchor, 对于一个大小为H*W的特征层,它上面每一个像素点对应9个anchor,这里有一个重要的参数feat_stride = 16, 它表示特征层上移动一个点,对应原图移动16个像素点(看一看网络中的stride就明白16的来历了)。把这9个anchor的坐标进行平移操作,获得在原图上的坐标。之后根据ground truth
label和这些anchor之间的关系生成rpn_lables,具体的方法论文中有提到,根据overlap来计算,这里就不详细说明了,生成的rpn_labels中,positive的位置被置为1,negative的位置被置为0,其他的为-1。box_target通过_compute_targets()函数生成,这个函数实际上是寻找每一个anchor最匹配的ground truth box, 然后进行论文中提到的box坐标的转化。
个人理解,这种设置anchor和计算box_targets的方式使网络能够学习到不同anchor预测和它相近框的能力。

相关文章推荐
- Some Notes of Caffe Installation
- Some Notes of Python Interfaces Pycaffe (Caffe)
- TensorFlow人工智能引擎入门教程之十二 Caffe转换tensorflow并 跨平台调用
- TensorFlow人工智能引擎入门教程所有目录
- Detection field exists in mongodb
- 安装caffe过程记录
- py-faster-rcnn训练笔记(ubuntu14.04+cuda7.5+cuDNNv3+Python2.7)
- 准确率, 召回率,mAP
- ubuntu 14.04上配置无GPU的Caffe(A卡机适用)
- caffe term: epoch, itr
- Ubuntu14.04 安装Caffe(仅CPU)
- deep learning for face detection (caffe C++)
- caffe+ubuntu14.04
- caffe中的iteration,batch_size, epochs理解
- Mac下Caffe安装-无GPU
- caffe solver.prototxt文件
- caffe模型的使用
- error :No module named google.protobuf.internal
- Extract CNN features using Caffe
- 配置Caffe+VS2013+CUDA 6.5+Windows 8.1 64位系统