Hadoop的优化(Shuffle过程)
2016-07-21 20:20
302 查看
1. Shuffle过程(以wordcount为例)
Shuffle过程:即洗牌或弄乱Collections.shuffle(List):随机打乱参数list里面的元素顺序。
MaoReduce里的Shuffle:描述着数据从map task输出到Reduce task输入阶段过程。
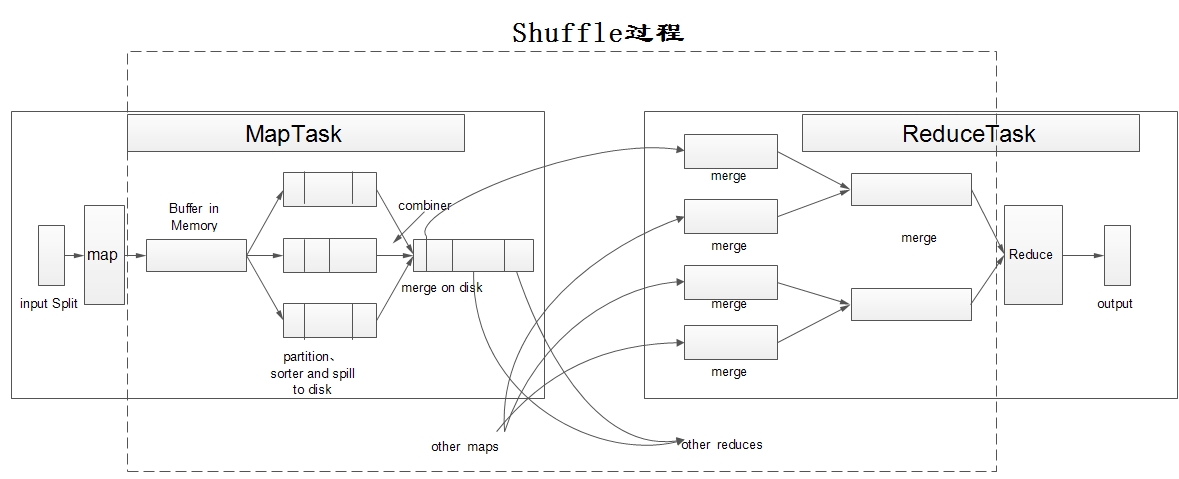
Shuffle过程
*step1:
input
InputFormat
*读取数据
*转换成< key, value >对
FileInputFormat
*TextInputFormat
*step2:
map
ModuleMapper
map(KEYIN,VALUEIN,KEYOUT,VALUEOUT)
继承TableMapper
TableMapper:将Scan出的HBase记录进行Split,解决了如何将HBase的record切分为inputSplit
Map数量如何确定(由Split大小即block决定):
每个Split大小 = min(max.split.size,min(block.size,min.split.size))
目的:保证一个inputSplit只来自于block
*默认情况下(输入格式)
KEYIN:LongWritable
VALUE:TEXT
*step3:
shuffle
*process
*map,output< key,value>
*memory(内存,内存比较大时,spill)
*spill(溢写到本地磁盘,文件很多时)
*分区(partition):将Map的输出分配到各个Reduce上 (分区逻辑不合理,会导致数据倾斜,需要重写分区逻辑)
分区逻辑:
hashcode%3
*排序(sort):只对同一分区内的key值进行排序,如果要全局排序,就要重写分区逻辑。
*很多小文件:spill
*合并(merge)
*排序(sort)
大文件 ->map task运行的本地磁盘目录下
—————————————-mapShuffle结束,ReduceShuffle开始—————————————————–
*copy
Reduce Task会到Map Task运行的机器上拷贝所需要的数据
*合并,merge,排序 sorter
*分组group
将相同key的value放在一起
总的来说:
*分区(partition)
*排序(sort)
*拷贝copy—-用户无法干涉
*分组group
*可设置
*压缩
compress
*combiner
Map Task短的Reduce
*step4:
reduce
reduce(KEYIN,VALUEIN,KEYOUT,VALUEOUT)
map输出< key,value>数据类型与reduce的输入类型一致
*step5:
output
OutputFormat
FileOutputFormat
TextOutputFormat
每个< key,value>对,输出一行,key与value中间的分隔符为\t,默认调用key和value的toString方法
Map-01
< hadoop,1>
< hadoop,1>
< yarn,1>
Map-02
Map-03
Reduce-01
a-zA-Z
Reduce-02
other

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- MySQL 优化
- 单机版搭建Hadoop环境图文教程详解
- Google排名优化的几个影响因素
- DB2优化(简易版)
- Mysql limit 优化,百万至千万级快速分页 复合索引的引用并应用于轻量级框架
- C#中尾递归的使用、优化及编译器优化
- 对优化Ruby on Rails性能的一些办法的探究
- 优化Ruby脚本效率实例分享
- Asp编码优化技巧
- 如何监测和优化OLAP数据库
- mysql -参数thread_cache_size优化方法 小结
- MySQL数据库优化技术之配置技巧总结
- Oracle数据库中SQL语句的优化技巧
- 深入学习SQL Server聚合函数算法优化技巧
- MySQL常见的底层优化操作教程及相关建议
- 详解mysql的limit经典用法及优化实例
- 数据库学习建议之提高数据库速度的十条建议