[源码学习][知了开发]WebMagic-总体流程源码分析
2016-07-18 18:10
531 查看
写在前面
前一段时间开发【知了】用到了很多技术(可以看我前面的博文http://blog.csdn.net/wsrspirit/article/details/51751568),这段时间抽空把这些整理一下,WebMagic是一个Java的爬虫,中国人写的,代码很模块化,也很利于二次开发,但是我们在使用的过程中也遇到了一些问题,这些问题我会在最后的博客中介绍,最近的博客将详细的走一下WebMagic的主题流程。这是官方的技术文档,写的很好,就是有点简单了:
https://code4craft.gitbooks.io/webmagic-in-action/content/zh/index.html
走起
我们从一个demo走起:public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor())
//从https://github.com/code4craft开始抓
.addUrl("https://github.com/code4craft")
//设置Scheduler,使用Redis来管理URL队列
.setScheduler(new RedisScheduler("localhost"))
//设置Pipeline,将结果以json方式保存到文件
.addPipeline(new JsonFilePipeline("D:\\data\\webmagic"))
//开启5个线程同时执行
.thread(5)
//启动爬虫
.run();
}Builder模式添加了总要的组件,然后设置thread,run。我们可以称之为WebMagic四大组件:Pipeline,Scheduler,Downloader和PageProcesser
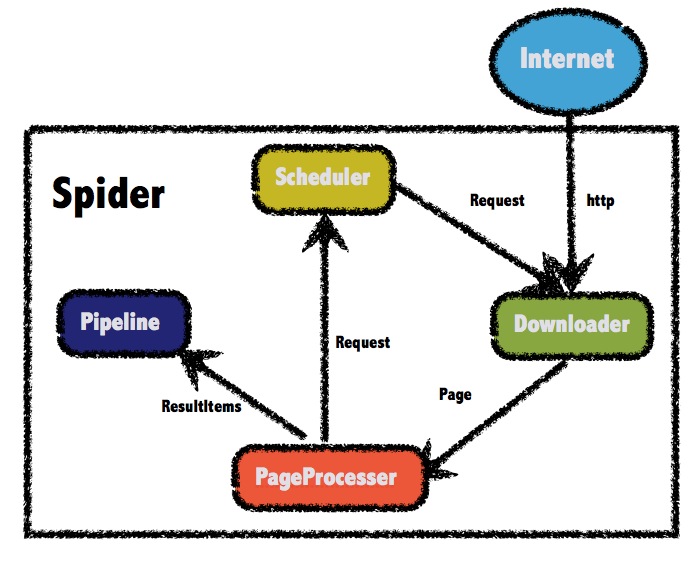
这里的图是官方网站copy的,如果你是初步使用那可能有点误导性,现在我们已经找到了程序的入口Spider类,看一下代码(有点长,没有关系,我会挑重点的说~)
package us.codecraft.webmagic;
import com.google.common.collect.Lists;
import org.apache.commons.collections.CollectionUtils;
import org.apache.http.HttpHost;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import us.codecraft.webmagic.downloader.Downloader;
import us.codecraft.webmagic.downloader.HttpClientDownloader;
import us.codecraft.webmagic.pipeline.CollectorPipeline;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.pipeline.Pipeline;
import us.codecraft.webmagic.pipeline.ResultItemsCollectorPipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.scheduler.QueueScheduler;
import us.codecraft.webmagic.scheduler.Scheduler;
import us.codecraft.webmagic.thread.CountableThreadPool;
import us.codecraft.webmagic.utils.UrlUtils;
import java.io.Closeable;
import java.io.IOException;
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
/**
* Entrance of a crawler.<br>
* A spider contains four modules: Downloader, Scheduler, PageProcessor and
* Pipeline.<br>
* Every module is a field of Spider. <br>
* The modules are defined in interface. <br>
* You can customize a spider with various implementations of them. <br>
* Examples: <br>
* <br>
* A simple crawler: <br>
* Spider.create(new SimplePageProcessor("http://my.oschina.net/",
* "http://my.oschina.net/*blog/*")).run();<br>
* <br>
* Store results to files by FilePipeline: <br>
* Spider.create(new SimplePageProcessor("http://my.oschina.net/",
* "http://my.oschina.net/*blog/*")) <br>
* .pipeline(new FilePipeline("/data/temp/webmagic/")).run(); <br>
* <br>
* Use FileCacheQueueScheduler to store urls and cursor in files, so that a
* Spider can resume the status when shutdown. <br>
* Spider.create(new SimplePageProcessor("http://my.oschina.net/",
* "http://my.oschina.net/*blog/*")) <br>
* .scheduler(new FileCacheQueueScheduler("/data/temp/webmagic/cache/")).run(); <br>
*
* @author code4crafter@gmail.com <br>
* @see Downloader
* @see Scheduler
* @see PageProcessor
* @see Pipeline
* @since 0.1.0
*/
public class Spider implements Runnable, Task {
protected Downloader downloader;
protected List<Pipeline> pipelines = new ArrayList<Pipeline>();
protected PageProcessor pageProcessor;
protected List<Request> startRequests;
protected Site site;
protected String uuid;
protected Scheduler scheduler = new QueueScheduler();
protected Logger logger = LoggerFactory.getLogger(getClass());
protected CountableThreadPool threadPool;
protected ExecutorService executorService;
protected int threadNum = 1;
protected AtomicInteger stat = new AtomicInteger(STAT_INIT);
protected boolean exitWhenComplete = true;
protected final static int STAT_INIT = 0;
protected final static int STAT_RUNNING = 1;
protected final static int STAT_STOPPED = 2;
protected boolean spawnUrl = true;
protected boolean destroyWhenExit = true;
private ReentrantLock newUrlLock = new ReentrantLock();
private Condition newUrlCondition = newUrlLock.newCondition();
private List<SpiderListener> spiderListeners;
private final AtomicLong pageCount = new AtomicLong(0);
private Date startTime;
private int emptySleepTime = 30000;
/**
* create a spider with pageProcessor.
*
* @param pageProcessor pageProcessor
* @return new spider
* @see PageProcessor
*/
public static Spider create(PageProcessor pageProcessor) {
return new Spider(pageProcessor);
}
/**
* create a spider with pageProcessor.
*
* @param pageProcessor pageProcessor
*/
public Spider(PageProcessor pageProcessor) {
this.pageProcessor = pageProcessor;
this.site = pageProcessor.getSite();
this.startRequests = pageProcessor.getSite().getStartRequests();
}
/**
* Set startUrls of Spider.<br>
* Prior to startUrls of Site.
*
* @param startUrls startUrls
* @return this
*/
public Spider startUrls(List<String> startUrls) {
checkIfRunning();
this.startRequests = UrlUtils.convertToRequests(startUrls);
return this;
}
/**
* Set startUrls of Spider.<br>
* Prior to startUrls of Site.
*
* @param startRequests startRequests
* @return this
*/
public Spider startRequest(List<Request> startRequests) {
checkIfRunning();
this.startRequests = startRequests;
return this;
}
/**
* Set an uuid for spider.<br>
* Default uuid is domain of site.<br>
*
* @param uuid uuid
* @return this
*/
public Spider setUUID(String uuid) {
this.uuid = uuid;
return this;
}
/**
* set scheduler for Spider
*
* @param scheduler scheduler
* @return this
* @Deprecated
* @see #setScheduler(us.codecraft.webmagic.scheduler.Scheduler)
*/
public Spider scheduler(Scheduler scheduler) {
return setScheduler(scheduler);
}
/**
* set scheduler for Spider
*
* @param scheduler scheduler
* @return this
* @see Scheduler
* @since 0.2.1
*/
public Spider setScheduler(Scheduler scheduler) {
checkIfRunning();
Scheduler oldScheduler = this.scheduler;
this.scheduler = scheduler;
if (oldScheduler != null) {
Request request;
while ((request = oldScheduler.poll(this)) != null) {
this.scheduler.push(request, this);
}
}
return this;
}
/**
* add a pipeline for Spider
*
* @param pipeline pipeline
* @return this
* @see #addPipeline(us.codecraft.webmagic.pipeline.Pipeline)
* @deprecated
*/
public Spider pipeline(Pipeline pipeline) {
return addPipeline(pipeline);
}
/**
* add a pipeline for Spider
*
* @param pipeline pipeline
* @return this
* @see Pipeline
* @since 0.2.1
*/
public Spider addPipeline(Pipeline pipeline) {
checkIfRunning();
this.pipelines.add(pipeline);
return this;
}
/**
* set pipelines for Spider
*
* @param pipelines pipelines
* @return this
* @see Pipeline
* @since 0.4.1
*/
public Spider setPipelines(List<Pipeline> pipelines) {
checkIfRunning();
this.pipelines = pipelines;
return this;
}
/**
* clear the pipelines set
*
* @return this
*/
public Spider clearPipeline() {
pipelines = new ArrayList<Pipeline>();
return this;
}
/**
* set the downloader of spider
*
* @param downloader downloader
* @return this
* @see #setDownloader(us.codecraft.webmagic.downloader.Downloader)
* @deprecated
*/
public Spider downloader(Downloader downloader) {
return setDownloader(downloader);
}
/**
* set the downloader of spider
*
* @param downloader downloader
* @return this
* @see Downloader
*/
public Spider setDownloader(Downloader downloader) {
checkIfRunning();
this.downloader = downloader;
return this;
}
protected void initComponent() {
if (downloader == null) {
this.downloader = new HttpClientDownloader();
}
if (pipelines.isEmpty()) {
pipelines.add(new ConsolePipeline());
}
downloader.setThread(threadNum);
if (threadPool == null || threadPool.isShutdown()) {
if (executorService != null && !executorService.isShutdown()) {
threadPool = new CountableThreadPool(threadNum, executorService);
} else {
threadPool = new CountableThreadPool(threadNum);
}
}
if (startRequests != null) {
for (Request request : startRequests) {
scheduler.push(request, this);
}
startRequests.clear();
}
startTime = new Date();
}
@Override
public void run() {
checkRunningStat();
initComponent();
logger.info("Spider " + getUUID() + " started!");
while (!Thread.currentThread().isInterrupted() && stat.get() == STAT_RUNNING) {
Request request = scheduler.poll(this);
if (request == null) {
if (threadPool.getThreadAlive() == 0 && exitWhenComplete) {
break;
}
// wait until new url added
waitNewUrl();
} else {
final Request requestFinal = request;
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
processRequest(requestFinal);
onSuccess(requestFinal);
} catch (Exception e) {
onError(requestFinal);
logger.error("process request " + requestFinal + " error", e);
} finally {
pageCount.incrementAndGet();
signalNewUrl();
}
}
});
}
}
stat.set(STAT_STOPPED);
// release some resources
if (destroyWhenExit) {
close();
}
}
protected void onError(Request request) {
if (CollectionUtils.isNotEmpty(spiderListeners)) {
for (SpiderListener spiderListener : spiderListeners) {
spiderListener.onError(request);
}
}
}
protected void onSuccess(Request request) {
if (CollectionUtils.isNotEmpty(spiderListeners)) {
for (SpiderListener spiderListener : spiderListeners) {
spiderListener.onSuccess(request);
}
}
}
private void checkRunningStat() {
while (true) {
int statNow = stat.get();
if (statNow == STAT_RUNNING) {
throw new IllegalStateException("Spider is already running!");
}
if (stat.compareAndSet(statNow, STAT_RUNNING)) {
break;
}
}
}
public void close() {
destroyEach(downloader);
destroyEach(pageProcessor);
destroyEach(scheduler);
for (Pipeline pipeline : pipelines) {
destroyEach(pipeline);
}
threadPool.shutdown();
}
private void destroyEach(Object object) {
if (object instanceof Closeable) {
try {
((Closeable) object).close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* Process specific urls without url discovering.
*
* @param urls urls to process
*/
public void test(String... urls) {
initComponent();
if (urls.length > 0) {
for (String url : urls) {
processRequest(new Request(url));
}
}
}
protected void processRequest(Request request) {
Page page = downloader.download(request, this);
if (page == null) {
throw new RuntimeException("unaccpetable response status");
}
// for cycle retry
if (page.isNeedCycleRetry()) {
extractAndAddRequests(page, true);
sleep(site.getRetrySleepTime());
return;
}
pageProcessor.process(page);
extractAndAddRequests(page, spawnUrl);
if (!page.getResultItems().isSkip()) {
for (Pipeline pipeline : pipelines) {
pipeline.process(page.getResultItems(), this);
}
}
//for proxy status management
request.putExtra(Request.STATUS_CODE, page.getStatusCode());
sleep(site.getSleepTime());
}
protected void sleep(int time) {
try {
Thread.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
protected void extractAndAddRequests(Page page, boolean spawnUrl) {
if (spawnUrl && CollectionUtils.isNotEmpty(page.getTargetRequests())) {
for (Request request : page.getTargetRequests()) {
addRequest(request);
}
}
}
private void addRequest(Request request) {
if (site.getDomain() == null && request != null && request.getUrl() != null) {
site.setDomain(UrlUtils.getDomain(request.getUrl()));
}
scheduler.push(request, this);
}
protected void checkIfRunning() {
if (stat.get() == STAT_RUNNING) {
throw new IllegalStateException("Spider is already running!");
}
}
public void runAsync() {
Thread thread = new Thread(this);
thread.setDaemon(false);
thread.start();
}
/**
* Add urls to crawl. <br>
*
* @param urls urls
* @return this
*/
public Spider addUrl(String... urls) {
for (String url : urls) {
addRequest(new Request(url));
}
signalNewUrl();
return this;
}
/**
* Download urls synchronizing.
*
* @param urls urls
* @return list downloaded
*/
public <T> List<T> getAll(Collection<String> urls) {
destroyWhenExit = false;
spawnUrl = false;
startRequests.clear();
for (Request request : UrlUtils.convertToRequests(urls)) {
addRequest(request);
}
CollectorPipeline collectorPipeline = getCollectorPipeline();
pipelines.add(collectorPipeline);
run();
spawnUrl = true;
destroyWhenExit = true;
return collectorPipeline.getCollected();
}
protected CollectorPipeline getCollectorPipeline() {
return new ResultItemsCollectorPipeline();
}
public <T> T get(String url) {
List<String> urls = Lists.newArrayList(url);
List<T> resultItemses = getAll(urls);
if (resultItemses != null && resultItemses.size() > 0) {
return resultItemses.get(0);
} else {
return null;
}
}
/**
* Add urls with information to crawl.<br>
*
* @param requests requests
* @return this
*/
public Spider addRequest(Request... requests) {
for (Request request : requests) {
addRequest(request);
}
signalNewUrl();
return this;
}
private void waitNewUrl() {
newUrlLock.lock();
try {
//double check
if (threadPool.getThreadAlive() == 0 && exitWhenComplete) {
return;
}
newUrlCondition.await(emptySleepTime, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
logger.warn("waitNewUrl - interrupted, error {}", e);
} finally {
newUrlLock.unlock();
}
}
private void signalNewUrl() {
try {
newUrlLock.lock();
newUrlCondition.signalAll();
} finally {
newUrlLock.unlock();
}
}
public void start() {
runAsync();
}
public void stop() {
if (stat.compareAndSet(STAT_RUNNING, STAT_STOPPED)) {
logger.info("Spider " + getUUID() + " stop success!");
} else {
logger.info("Spider " + getUUID() + " stop fail!");
}
}
/**
* start with more than one threads
*
* @param threadNum threadNum
* @return this
*/
public Spider thread(int threadNum) {
checkIfRunning();
this.threadNum = threadNum;
if (threadNum <= 0) {
throw new IllegalArgumentException("threadNum should be more than one!");
}
return this;
}
/**
* start with more than one threads
*
* @param executorService executorService to run the spider
* @param threadNum threadNum
* @return this
*/
public Spider thread(ExecutorService executorService, int threadNum) {
checkIfRunning();
this.threadNum = threadNum;
if (threadNum <= 0) {
throw new IllegalArgumentException("threadNum should be more than one!");
}
return this;
}
public boolean isExitWhenComplete() {
return exitWhenComplete;
}
/**
* Exit when complete. <br>
* True: exit when all url of the site is downloaded. <br>
* False: not exit until call stop() manually.<br>
*
* @param exitWhenComplete exitWhenComplete
* @return this
*/
public Spider setExitWhenComplete(boolean exitWhenComplete) {
this.exitWhenComplete = exitWhenComplete;
return this;
}
public boolean isSpawnUrl() {
return spawnUrl;
}
/**
* Get page count downloaded by spider.
*
* @return total downloaded page count
* @since 0.4.1
*/
public long getPageCount() {
return pageCount.get();
}
/**
* Get running status by spider.
*
* @return running status
* @see Status
* @since 0.4.1
*/
public Status getStatus() {
return Status.fromValue(stat.get());
}
public enum Status {
Init(0), Running(1), Stopped(2);
private Status(int value) {
this.value = value;
}
private int value;
int getValue() {
return value;
}
public static Status fromValue(int value) {
for (Status status : Status.values()) {
if (status.getValue() == value) {
return status;
}
}
//default value
return Init;
}
}
/**
* Get thread count which is running
*
* @return thread count which is running
* @since 0.4.1
*/
public int getThreadAlive() {
if (threadPool == null) {
return 0;
}
return threadPool.getThreadAlive();
}
/**
* Whether add urls extracted to download.<br>
* Add urls to download when it is true, and just download seed urls when it is false. <br>
* DO NOT set it unless you know what it means!
*
* @param spawnUrl spawnUrl
* @return this
* @since 0.4.0
*/
public Spider setSpawnUrl(boolean spawnUrl) {
this.spawnUrl = spawnUrl;
return this;
}
@Override
public String getUUID() {
if (uuid != null) {
return uuid;
}
if (site != null) {
return site.getDomain();
}
uuid = UUID.randomUUID().toString();
return uuid;
}
public Spider setExecutorService(ExecutorService executorService) {
checkIfRunning();
this.executorService = executorService;
return this;
}
@Override
public Site getSite() {
return site;
}
public List<SpiderListener> getSpiderListeners() {
return spiderListeners;
}
public Spider setSpiderListeners(List<SpiderListener> spiderListeners) {
this.spiderListeners = spiderListeners;
return this;
}
public Date getStartTime() {
return startTime;
}
public Scheduler getScheduler() {
return scheduler;
}
/**
* Set wait time when no url is polled.<br><br>
*
* @param emptySleepTime In MILLISECONDS.
*/
public void setEmptySleepTime(int emptySleepTime) {
this.emptySleepTime = emptySleepTime;
}
}首先就是Spider可以装载四大组件,然后addurl,然后thread,然后run
public Spider addUrl(String... urls) {
for (String url : urls) {
addRequest(new Request(url));
}
signalNewUrl();
return this;
}
/**
* Add urls with information to crawl.<br>
*
* @param requests requests
* @return this
*/
public Spider addRequest(Request... requests) {
for (Request request : requests) {
addRequest(request);
}
signalNewUrl();
return this;
}
private void addRequest(Request request) {
if (site.getDomain() == null && request != null && request.getUrl() != null) {
site.setDomain(UrlUtils.getDomain(request.getUrl()));
}
scheduler.push(request, this);
}Request是对url的一个包装,我们后面再说,我们发现url经过包装后被scheduler#push,然后执行了signalNewUrl
private void waitNewUrl() {
newUrlLock.lock();
try {
//double check
if (threadPool.getThreadAlive() == 0 && exitWhenComplete) {
return;
}
newUrlCondition.await(emptySleepTime, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
logger.warn("waitNewUrl - interrupted, error {}", e);
} finally {
newUrlLock.unlock();
}
}
private void signalNewUrl() {
try {
newUrlLock.lock();
newUrlCondition.signalAll();
} finally {
newUrlLock.unlock();
}
}发现这是一个条件变量,然后如果加入Request后就会唤醒阻塞的task进行处理,这里实现了一个线程池,线程池的线程数量就是thread(5)定义的,threadPool.getThreadAlive()这个的意思是目前正在运行的thread。
ok目前我们走完了addurl和thread,那就是最后的run方法了,我们首先看这里Spider的定义,run方法就是实现的Runnable
public class Spider implements Runnable, Task
@Override
public void run() {
checkRunningStat();
initComponent();
logger.info("Spider " + getUUID() + " started!");
while (!Thread.currentThread().isInterrupted() && stat.get() == STAT_RUNNING) {
Request request = scheduler.poll(this);
if (request == null) {
if (threadPool.getThreadAlive() == 0 && exitWhenComplete) {
break;
}
// wait until new url added
waitNewUrl();
} else {
final Request requestFinal = request;
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
processRequest(requestFinal);
onSuccess(requestFinal);
} catch (Exception e) {
onError(requestFinal);
logger.error("process request " + requestFinal + " error", e);
} finally {
pageCount.incrementAndGet();
signalNewUrl();
}
}
});
}
}
stat.set(STAT_STOPPED);
// release some resources
if (destroyWhenExit) {
close();
}
}
private void checkRunningStat() {
while (true) {
int statNow = stat.get();
if (statNow == STAT_RUNNING) {
throw new IllegalStateException("Spider is already running!");
}
if (stat.compareAndSet(statNow, STAT_RUNNING)) {
break;
}
}
}
protected void initComponent() {
if (downloader == null) {
this.downloader = new HttpClientDownloader();
}
if (pipelines.isEmpty()) {
pipelines.add(new ConsolePipeline());
}
downloader.setThread(threadNum);
if (threadPool == null || threadPool.isShutdown()) {
if (executorService != null && !executorService.isShutdown()) {
threadPool = new CountableThreadPool(threadNum, executorService);
} else {
threadPool = new CountableThreadPool(threadNum);
}
}
if (startRequests != null) {
for (Request request : startRequests) {
scheduler.push(request, this);
}
startRequests.clear();
}
startTime = new Date();
}首先是checkRunningStat检查一下目前Spider的执行情况,然后是initComponent,我们可以看到默认的Downloader和Pipeline是可以为空,然后初始化threadpool,最后是把starturl加入Request中(现在startUrl是spider.addUrl添加的,这也是符合爬虫的起始地址,而不是site的起始地址的观点)
从这个代码中,我们基本上看懂了scheduler是干什么的:Request request = scheduler.poll(this);
Scheduler为我们存储了Request并且可以做一些功能(去重,设置优先级等)我们需要pull或者push
真正在线程池中运行的代码是
public void run() {
try {
processRequest(requestFinal);
onSuccess(requestFinal);
} catch (Exception e) {
onError(requestFinal);
logger.error("process request " + requestFinal + " error", e);
} finally {
pageCount.incrementAndGet();
signalNewUrl();
}
}
protected void processRequest(Request request) {
Page page = downloader.download(request, this);
if (page == null) {
throw new RuntimeException("unaccpetable response status");
}
// for cycle retry
if (page.isNeedCycleRetry()) {
extractAndAddRequests(page, true);
sleep(site.getRetrySleepTime());
return;
}
pageProcessor.process(page);
extractAndAddRequests(page, spawnUrl);
if (!page.getResultItems().isSkip()) {
for (Pipeline pipeline : pipelines) {
pipeline.process(page.getResultItems(), this);
}
}
//for proxy status management
request.putExtra(Request.STATUS_CODE, page.getStatusCode());
sleep(site.getSleepTime());
}Request经过Downloader的download方法返回Page,大致经过是Downloader拿到Request的url然后执行http#get方法得到httpResponse组装成Page,然后PageProcesser执行解析,这部分代码是需要自己实现的,例如下面的:
public void process(Page page) {
List<String> relativeUrl = page.getHtml().xpath("//li[@class='item clearfix']/div/a/@href").all();
page.addTargetRequests(relativeUrl);
relativeUrl = page.getHtml().xpath("//div[@id='zh-question-related-questions']//a[@class='question_link']/@href").all();
page.addTargetRequests(relativeUrl);
List<String> answers = page.getHtml().xpath("//div[@id='zh-question-answer-wrap']/div").all();
boolean exist = false;
for(String answer:answers){
String vote = new Html(answer).xpath("//div[@class='zm-votebar']//span[@class='count']/text()").toString();
if(Integer.valueOf(vote) >= voteNum){
page.putField("vote",vote);
page.putField("content",new Html(answer).xpath("//div[@class='zm-editable-content']"));
page.putField("userid", new Html(answer).xpath("//a[@class='author-link']/@href"));
exist = true;
}
}
if(!exist){
page.setSkip(true);
}
}也就是使用正则表达式等东西解析page中的内容,包括哪些是需要的提取的属性,哪些是应该加入Scheduler中继续爬的(如下一页这种),然后将爬出来的属性写入Page的ResultItem一个hashMap中,最后Pipeline会提取ResultItem进行存储等工作。好了,基本的流程就这样了。
新司机开车吧
看完这些你已经对WebMagic有了大致的认识,我最近更新博文速度可能不会很快,所以如果你很想了解WebMagic的全貌那你已经可以自己开车啦~老司机的报站
后面我将每个组件详细介绍,Scheduler,Downloader,Pipeline和PageProcesser,CountableThreadPool,SpiderMonitor,最后介绍OOSpider也就是使用注解的方式编写爬虫,你会发现这太帅了!
相关文章推荐
- 从源码安装Mysql/Percona 5.5
- Python3写爬虫(四)多线程实现数据爬取
- Scrapy的架构介绍
- 爬虫笔记
- 浅析Ruby的源代码布局及其编程风格
- 基于C#实现网页爬虫
- Nodejs爬虫进阶教程之异步并发控制
- Node.js环境下编写爬虫爬取维基百科内容的实例分享
- PHP strtotime函数用法、实现原理和源码分析
- asp.net 抓取网页源码三种实现方法
- jQuery 源码分析笔记(3) Deferred机制
- PHP+HTML+JavaScript+Css实现简单爬虫开发
- JS小游戏之仙剑翻牌源码详解
- JS小游戏之宇宙战机源码详解
- 深入浅析knockout源码分析之订阅
- jQuery 源码分析笔记(5) jQuery.support
- jQuery-1.9.1源码分析系列(十)事件系统之事件包装
- jQuery源码分析之jQuery中的循环技巧详解
- 本人自用的global.js库源码分享
- java中原码、反码与补码的问题分析