kafka技术内幕
2016-07-18 17:42
253 查看
第二章 生产者
概述
消息系统通常都会由生产者,消费者,Broker三大部分组成,生产者会将消息写入到Broker,消费者会从Broker中读取出消息,不同的MQ实现的Broker实现会有所不同,不过Broker的本质都是要负责将消息落地到服务端的存储系统中。不管是生产者还是消费者对于Broker而言都是客户端,只不过一个是生产消息一个是消费消息。图2-1中生产者和消费者都是通过客户端请求的方式发送给服务端去执行存储消息或者获取消息的流程,在客户端和服务端这一层都有一个连接对象专门负责发送请求和接收请求,具体步骤如下:生产者客户端应用程序产生消息
客户端连接对象将消息包装到请求中发送到服务端
服务端的入口也有一个连接对象负责接收请求,并将消息以文件的形式存储起来
服务端返回响应结果给生产者客户端
消费者客户端应用程序消费消息
客户端连接对象将消费信息也包装到请求中发送给服务端
服务端从文件存储系统中取出消息
服务端返回响应结果给消费者客户端
客户端将响应结果还原成消息并开始处理消息
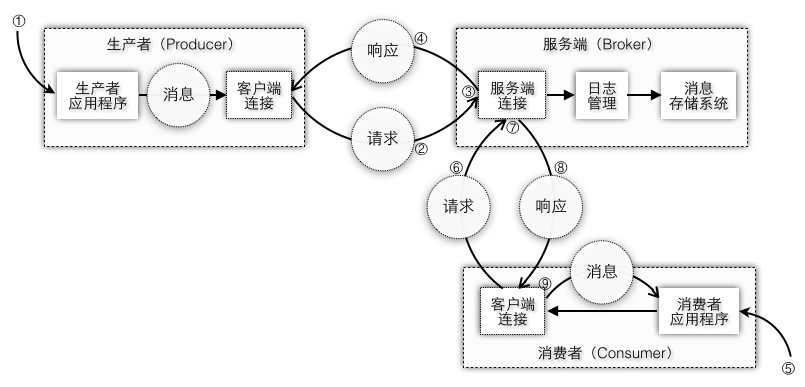
图2-1 客户端和服务端交互
Kafka作为一个分布式的消息存储系统,生产者客户端需要将消息传给Kafka集群完成消息存储,本章从Kafka的消费者实现为入口,在源码分析的过程中,思考以下几个问题是如何实现的:
生产者是如何确保将消息以分布式的方式存储到Kafka集群?
生产者客户端是如何组织消息,发送消息,并接收服务端的响应?
客户端和服务端的通信机制,如何有效运用线程模型更高效地通信
本章的着重点主要在于客户端和服务端的网络通信流程,暂时还没有涉及到Kafka的服务端具体实现。因为对于任何的分布式系统而言,必须有一套负责不同节点之间数据传输的网络层通信机制,这套底层的框架要能够处理协议的编解码,客户端和服务端的请求发送和接收等等。在Java中的网络编程中最早是Socket模式,后来进化出了Selector选择器模式,再结合上队列模型,缓冲区机制,就可以设计出一套适合自己系统的网络层通信协议框架。虽然通信模型和服务端的架构实现上没有太大的关联,不过可以在这最底层的框架上添加一些额外的功能比如超时重试,序列化等功能,那么服务端就可以更专注地处理主体业务逻辑,而不需要花太多的精力去关注网络层的各种异常情况。
在分布式的系统中,协议是由服务端定制的,客户端只要遵循这种协议发送请求,服务端就可以确保可以正常地接收并处理客户端的请求。所以实际上客户端的实现可以由不同的语言自己去实现,官方的wiki中列出了目前已经支持的绝大多数语言。因为对于不同语言都有自己的网络层编程API,比如Golang使用channel通信,Akka使用Actor方式传递消息,它们就可以充分利用自己的语言特性去实现不同的客户端。
Kafka初期使用Scala编写,因此早期scala版本的producer、consumer和服务端的实现都放在core包下,最新的客户端使用了Java重新实现,被放在了clients包下。本章我们主要分析如下几个部分的内容:
新版本的Producer客户端实现(Java)
旧版本的Producer客户端实现(Scala)
服务端的网络连接实现(SocketServer)
双端队列InFlightRequests
队列图2-32是记录收集器的batches队列和NetworkClient的inFlightRequests队列的对比,记录收集器双端队列中的元素只保存数据,没有状态信息,所以针对这个队列的操作只是简单地追加到队列最后一个,取出时取的是队列第一个元素。而inFlightRequests队列中的元素是客户端请求对象,它是有状态的,比如这个请求是否已经发送完成就是一种状态。请求发送完成并不代表就可以从队列中移除,不过如果客户端不需要响应结果发送完成则是可以删除的。
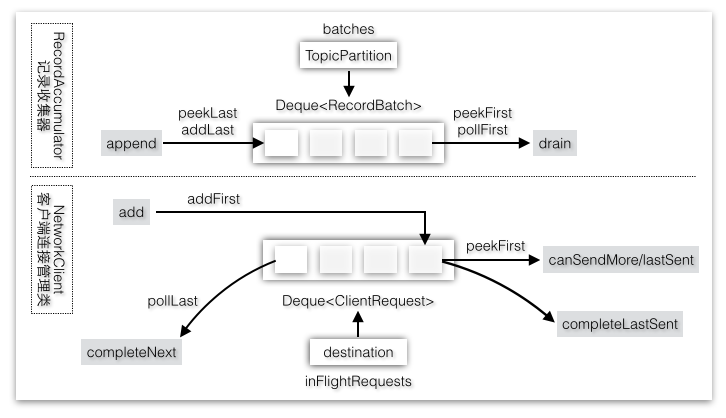
图2-32 InFlightRequests双端队列
实际上如果客户端请求添加到队列尾部也是可以的,如图2-33只不过对应的peek和poll的顺序都要做出改变:
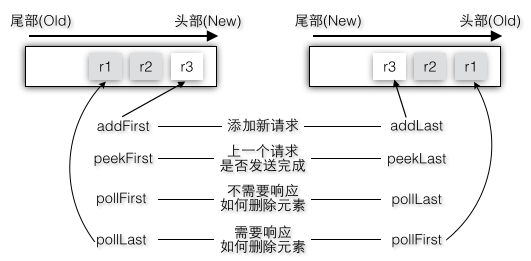
图2-33 添加最新元素到双端队列的两种方式
图2-34中以新请求添加到队列头部为例,模拟了多个请求是如何加入队列以及完成时如何从队列中移除,其中[r1,r2,r3]需要响应结果,而r4不需要响应结果,假设[r1-r4]四个请求都属于某个节点,所以客户端会按照顺序依次加入到队列中。不过后一个请求必须要保证前一个请求发送到服务端节点后才可以进入队列等待发送,当收到响应请求完成时,r4是从队列头部被删除,而其他请求则是从队列尾部删除。
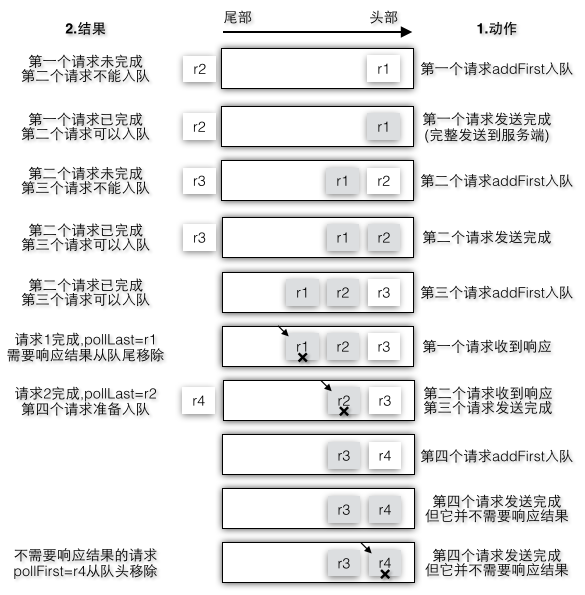
图2-34 双端队列操作
客户端请求的生命周期
客户端在和服务端某个节点建立连接时,会根据客户端中目前的请求队列判断第一个请求是否已经完成来判断这个节点是否可以发送更多的请求
canSendMore。那么客户端请求什么时候才算是completed?注意虽然队列中保存的是ClientRequest,不过在add和peek时都是取出ClientRequest里的RequestSend对象。RequestSend到Send的继承体系是
RequestSend->NetworkSend->ByteBufferSend->Send。对于ByteBufferSend而言完成的条件是没有要发送的数据了,即缓冲区中的数据都写完了。所以这里请求完成指的是
当前发送请求已经
成功发送到服务端了,但并
不需要等待这个请求收到响应结果。
即使在同一个目标节点的同一个队列中,多个不同ClientRequest请求也是有顺序的,在前面的分析中已经有两个地方限制了客户端请求并不是可以随便添加到队列中的:
在准备连接时,queue.peekFirst().request().completed()=true
可以连接发送请求后,KafkaChannelsetSend也要确保send!=null,一个KafkaChannel只允许同时运行一个Send
其中第二个条件也将直接影响第一个条件,如果第一个请求没有发送完毕,它还会存在于KafkaChannel中,此时来了第二个请求,如果不加以限制即使send!=null,也要将第二个请求设置到KafkaChannel中,这样第一个请求返回的时候却返回了第二个请求,因为Send已经被第二个请求更新了,所以这是有问题的。
不过ClientRequest.RequestSend完成,并不表示这个ClientRequest在NetworkClient中就完成了,客户端的请求被发送到服务端,还需要等待收到服务端的响应结果。所以
inFlightRequests表示正在进行中还没有完成的请求,下面几种场景都表示还没有完成的ClientRequest:ClientRequest请求等待发送,ClientRequest请求正在发送,ClientRequest请求已经发送(这时RequestSend完成),ClientRequest对应的请求还未收到响应结果,图2-35是ClientRequest在InFlightRequests中的生命周期。
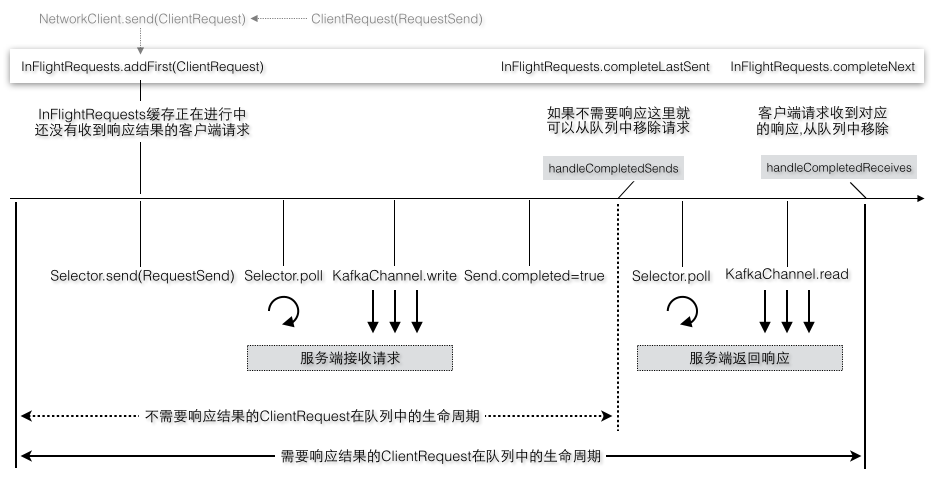
图2-35 客户端请求在队列中的生命周期
客户端请求发送和接收示例
我们从发送线程开始,举例多个请求的发送和接收,以及在队列中的操作。发送线程第一次运行在准备工作时选择readyNodes,然后为已经准备好的节点创建连接和客户端请求ClientRequest,调用NetworkClient.send会将请求先加入请求对应的目标节点的队列中,然后设置到KafkaChannel中,每个KafkaChannel只有一个正在进行中的Send,如果已经存在Send(比如正在进行中的客户端请求没有被发送完成就不会被重置为空)则不允许再次调用。当选择器轮询时会将选择到的KafkaChannel中的Send通过底层的SocketChannel发送给服务端。图2-36模拟了第一个请求加入队列后的工作过程。
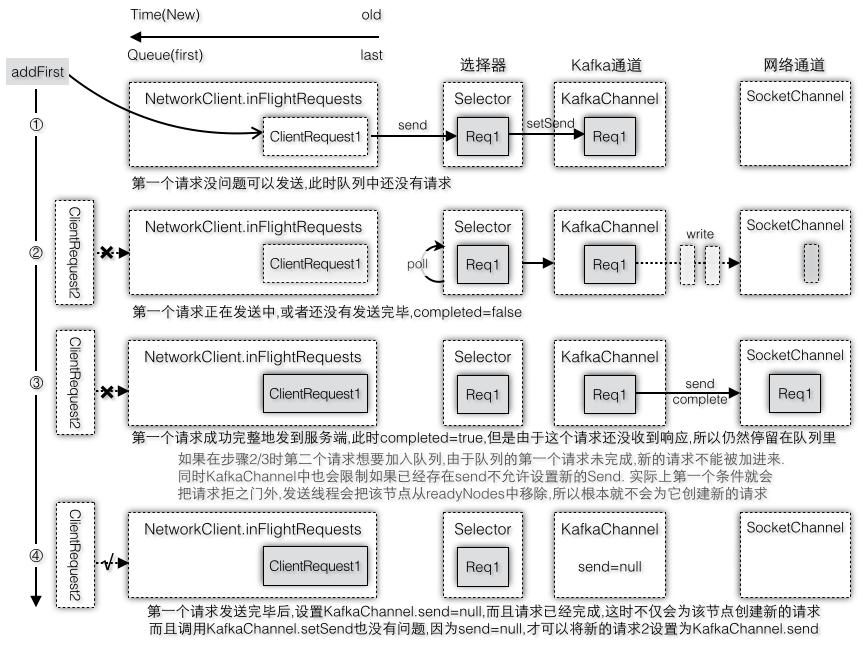
图2-36 NetworkClient.send包括入队列和调用Selector.send
假设第一个请求还没有发送完成比如还在步骤2/3时,发送线程第二次运行准备发送第二批数据(假设这两个请求都是要发送到同一个目标节点),由于队列中的第一个请求还没有完成,canSendMore返回false,在准备工作时就会将其从readyNodes中移除,这样就不会为这个节点创建新的ClientRequest,即第二个请求根本就不会被生成。即使没有canSendMore这一层判断,假设创建了第二个请求,当准备调用NetworkClient.send时,可是又遇到了第二个拦路虎,因为KafkaChannel.setSend要求send不能为空时才可以设置,而现在send已经被第一个客户端请求占着不放,还没有重置,所以客户端请求还是无法被成功地设置。这样就存在一个问题,请求已经被添加到队列中,但是却没办法设置到KafkaChannel中,只能等下次再调用一次NetworkClient.send,不过这样请求队列针对同一个请求就被加入多次了,所以能够尽早在第一道门框拦下第二个请求就不要在放进来了。所以新的请求被创建的时机必须等到队列头部第一个请求已经完成才会创建,而且此时第一个请求在完成的时候就设置了send=null,新创建的请求也可以被成功地设置到KafkaChannel中,所以说如果第一个条件满足(canSendMore=true)后通常第二个条件也是满足(send=null),图2-37是请求[R2,R3]分别在每次允许加入队列时加入到队列头部,图2-38是不需要响应结果的请求R3从队列头部删除请求,图2-39是需要响应结果的请求[R1,R2,R4]分别收到响应结果后从队列尾部删除请求。
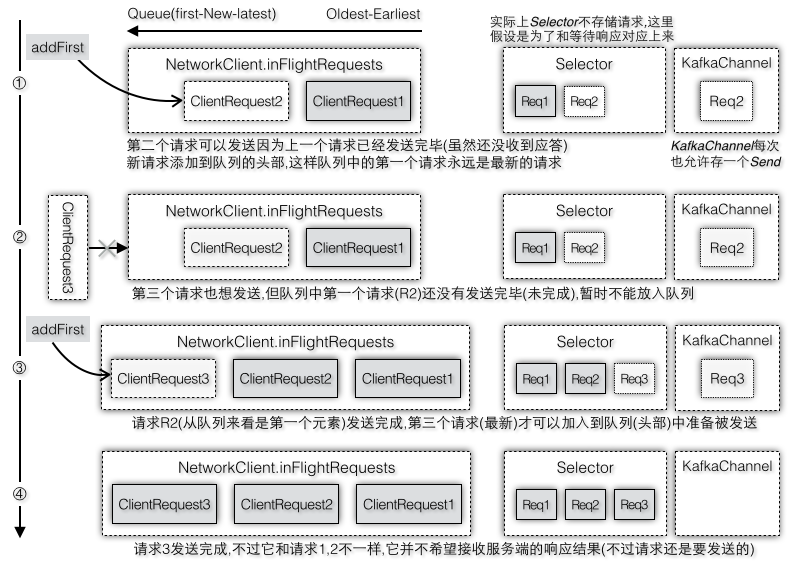
图2-37 往队列中添加一个新的请求必须确保上一个请求已经完成
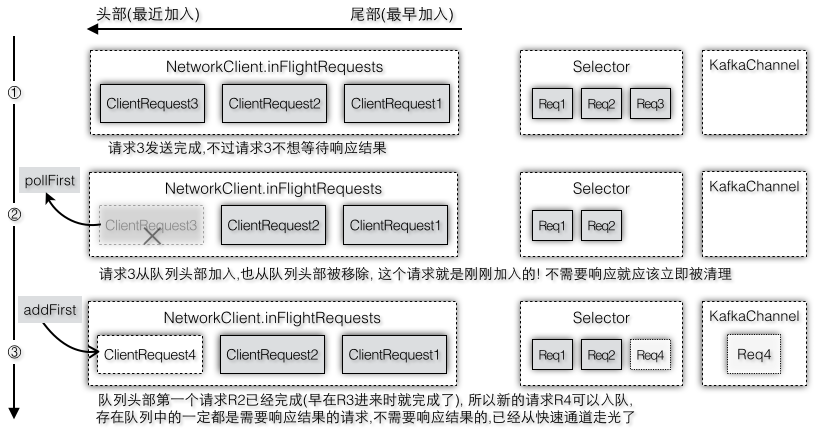
图2-38 不需要响应结果的请求发送完成从队列头部删除
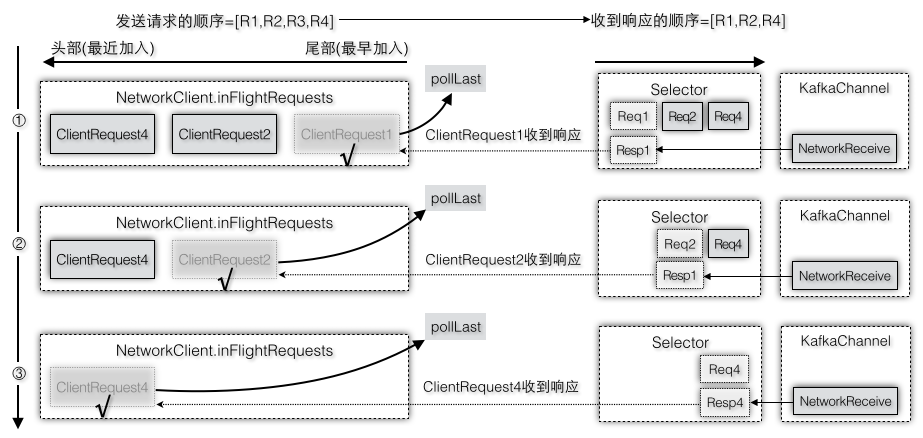
图2-39 需要响应结果的请求收到响应后从队列尾部删除
排队的示例
这里的双端队列和现实世界的排队方式是类似的,如图2-40以去银行办理业务为例,排队机给每个人一个号码表示ClientRequest请求的顺序,只有上一个号码的人办理完了业务,下一个人才能办理。为了和这里的NetworkClient语义相同,我们稍微修改下排队规则,假设办理业务分成三个步骤:告诉业务员要办理什么业务,业务员处理业务,业务员完成业务,这些步骤都是可以并行执行的,而且执行完一个小步骤都要回到自己的座位上继续等待,假设只有一个业务办理窗口时(不过其实你不用担心,假设这个业务员只是一个入口而已,他的后台即服务端是开着很多线程在处理的)。第一个人开始办理业务时首先加入到inFlightRequests,并告诉业务员要取钱,业务员收到指令后,记录了这个信息(可以把业务员看做专门负责接收业务指令,但是不办理具体的业务),第一个人回到自己座位,他还不能离开大厅,因为他只是传达了这个指定,但是钱还没取到;因为此时队列中的第一人已经完成了发送指令请求,第二个人可以办理了,同样先加入到inFlightRequests队列中,然后第二个人说要改密码,业务员收到指令后同样不真正执行改密码的命令,但是如果这个时候第三个人等不住了,还没等第二个人传达完指令就想强行插队,对不起,请稍等下!所以inFlightRequest表示已经发送完请求,或者正在发送请求的,但是他们都还不能离开大厅,因为还没有收到响应结果。因为每个请求发送给业务员都是有顺序的,所以加入到inFlightRequest中的ClientRequest也都是有顺序的,这个队列是个双端队列,队列头部是最近加入的请求,队列尾部是最早加入的请求,如果队列第一个元素的请求还没有发送完成,不允许下一个请求加入队列中,所以新加入队列的元素,在这之前的请求一定都是已经发送完成了,否则他就不可能被加入队列中了。
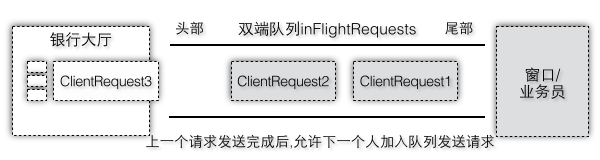
图2-40 银行办理业务与队列
图2-40中虽然符合新请求添加到队列头部(我们把尾部设置为面对业务员),按照排队的方式理解起来也比较直观,第一个请求先于第二个请求被处理,不过似乎业务员总是面对着第一个请求。为了更好地理解这个双端队列图2-41中分成两个队列,排队队列负责接收请求,处理队列负责处理收到的请求,请求按照发送顺序加入排队队列,一旦请求发送完毕,业务员就会把收到的请求放入另一个队列中,这样两种队列其实都满足了排队论。不过双端队列本来就可以在头尾同时操作,所以实际上只需要一个队列即可。

图2-41 排队队列和处理队列
现在如果从一个业务窗口推到多个窗口,如图2-42就类似于客户端可以向多个服务端节点同时发送请求,每个服务端目标节点都有一个双端队列,每个队列的处理方式和上面一个窗口都是类似的,只不过现在每个请求都携带了自己将会被排队到指定窗口。
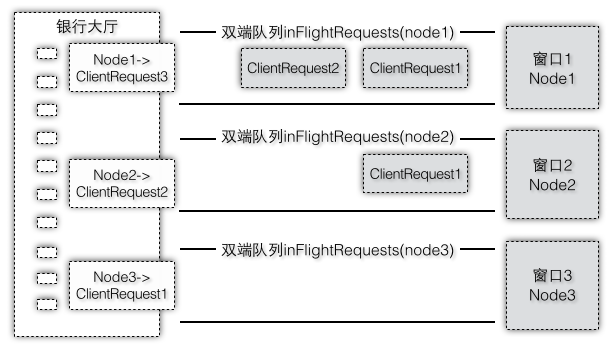
图2-42 多个窗口的队列
假设第一个人的业务被成功受理,并且也成功取到钱了,他就可以拿着钱开开心心地离开银行大厅了,现在他的业务已经全部办理好了,就会从inFlightRequests中移除了,因为inFlightRequests中保存的是发送完或正在发送请求,但是没有收到响应结果,一旦收到响应结果就不应该继续在大厅里呆下去了,毕竟inFlightRequests的容量也是有限制的,如果银行大厅座位都做满了,说明请求量太大了,所以取完钱就赶紧回家。
对于需要响应的请求,请求在服务端慢吞吞地处理,返回也是有顺序的,也是说服务端是按照客户端请求的顺序处理的,只有第一个请求返回后才会接着返回第二个请求结果,并不会出现第二个请求先于第一个请求返回结果给客户端。所以对于不需要响应结果的客户端请求如果在handleCompletedSends中没有删除而是等到handleCompletedReceives才删除显然是不公平的,因为他本来可以立即返回,但是却要等到他前面的人都收到结果后才能轮到他。比如超市通常会设置无购物快速通道,如果顾客没有购买任何东西不需要在购物通道上排队就可以快速出去。
如果客户端请求不需要响应就会像上面那样,在发送完就被清理掉了,这是因为客户端既然不想要响应结果,那么就让请求越快完成越好。通过这种快速清理的方式确保了下一个请求进来之前,保存在队列中的一定都是需要响应的:因为上一个请求是不需要响应的,那么在下一个请求加入队列头部之前,上一个请求已经从队列头部移除掉了。以超市为例,进入购物通道排队的人一定知道排队的人都是有购物的,没有人那么傻没有买任何东西却还傻傻地在排队。同样以银行办理业务为例,假设有些人是来咨询业务的,业务员是立即可以回答的,不需要和后台的服务端交互(或者尽管有交互,但是客户端并不关心这个结果,在你出来结果之后,他可能已经都走了)。这样的客户端请求也要排队,在准备发送请求时加入队列头部第一个元素,完成时就可以立即从队列头部移除,不需要进入处理队列了。
现在Java版本的生产者客户端已经分析完毕,表2-4总结了客户端发送过程涉及到的主要组件和其用途:
| 组件 | 主要用途 | 与上下文组件的关系 |
|---|---|---|
RecordAccumulator记录收集器 | 将消息按照Partition存储 | 收集消息,提供消息给发送线程 |
Sender发送线程 | 针对每个节点都创建一个客户端请求 | 将消息按照节点分组转交给客户端连接管理类 |
NetworkClient客户端连接管理 | 管理多个节点的客户端请求 | 驱动选择器工作 |
Selector选择器 | 以轮询模式驱动不同事件 | 通知网络通道读写操作 |
KafkChannel网络通道 | 负责请求的发送和响应接收 | 从原始网络通道中读写字节缓冲区数据 |
本章总结
本章主要分析了两种版本的生产者客户端以及服务端的网络层实现,重点介绍了客户端的NetworkClient和服务端的SocketServer,Java版本的客户端和服务端的Processor都使用了Selector选择器模式和KafkaChannel,而Scala版本的客户端则使用比较原始的BlockingChannel。在客户端服务端的通信模型中,通常一个客户端会连接到多个服务端,一个服务端也会接受多个客户端的连接,所以使用Selector模式可以使得网络通信更加高效,在服务端还运用了Reactor模式将IO部分和业务处理部分的线程进行分离。除此之外,客户端和服务端在很多地方都运用了队列这种数据结构来对请求或者响应进行排队,队列是一种保证数据被有序地处理并且能够缓存的结构。表2-8总结了Scala版本的生产者客户端和服务端中使用队列的地方,这里并不包括Java版本的生产者使用更高级的双端队列。| 往队列中追加 | 从队列中弹出 | 队列 | 数据结构 |
|---|---|---|---|
| Producer.asyncSend | ProducerSendThread.run | queue:BlockingQueue | KeyedMessage |
| Processor.accept | Processor.configureNewConnections | newConnections:ConcurrentLinkedQueue | SocketChannel |
| Processor.processCompletedReceives | KafkaRequestHandler.run | requestQueue:ArrayBlockingQueue | Request |
| KafkaApis.handle | Processor.processNewResponses | responseQueues:BlockingQueue | Response |
在客户端要向服务端发送消息时我们会获取Cluster集群状态(Java版本)/集群元数据TopicMetadata(Scala版本),为消息选择Partition,选择Partition的Leader作为目标节点,在服务端SocketServer会接收客户端发送的请求交给Handler和KafkaApis处理,具体和消息相关的处理逻辑由KafkaApis以及KafkaServer中的其他组件一起完成。
图2-57是Kafka服务端的内部组件图,网络层包括一个Acceptor线程和多个Processor线程;API层的多个API线程指的是多个KafkaRequestHandler线程,网络层和API层中间有一个RequestChannel,它是请求和响应的数据交换中转站;API层和日志子系统有关联因为API层的请求要读取或写入日志文件,Replication子系统主要的管理类是ReplicaManager,而KafkaApis和它有直接的关联;一个KafkaBroker和其他Broker以及依赖的ZK也有关联,这些关联系统在后续的章节中都会分析到。

图2-57 KafkaBroker的内部组件
图片引自:https://cwiki.apache.org/confluence/display/KAFKA/Index
本章分析的Producer包括后面要分析的Consumer都不是作为Kafka的内置服务,而是一种客户端(所以它们都在clients包),客户端可以独立于Kafka集群,因此开发客户端应用程序时只需要提供一个Kafka集群的地址即可,说明客户端可以和Kafka集群独立开来,图2-58展示了一种典型的生产者、消费者和Kafka集群交互方式,其中Kafka集群还会和ZooKeeper互相通信。
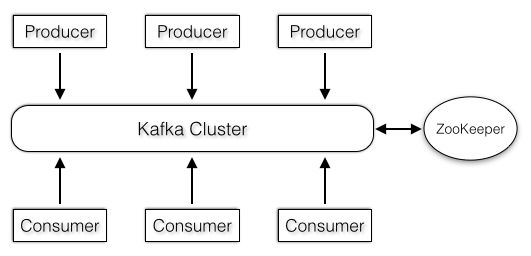
图2-58 生产者、消费者、Kafka集群交互
客户端有发送和接收请求,服务端同样也有接收和发送的逻辑,因为对于I/O来说是双向的:客户端发送请求,就意味着服务端要接收请求,同样服务端对请求作出响应并发送响应结果给客户端,客户端就要接收响应。接下来我们会分析客户端发送的请求在服务端是怎么被KafkaApis处理的。
第三章 日志存储
3.3 日志管理类的后台线程
分布式存储系统除了要保证客户端写请求流程的正确性,节点可能会非正常宕机或者需要重启,在启动的时候必须要能够正常地加载/恢复已有的数据,日志管理类在创建的时候要加载已有的所有日志文件,这和创建Log时要加载所有的Segment是类似的。LogManager的
logDirs参数对应了
log.dirs配置项,每个TopicPartition文件夹都对应一个Log实例,所有的Partition文件夹都在日志目录下,当成功加载完所有的Log实例后logs才可以被日志管理类真正地用在战场上。
假设logDirs=
/tmp/kafka_logs1,/tmp/kafka_logs2,logs1下有[t0-0,t0-1,t1-2],logs2下有[t0-2,t1-0,t1-1],图3-26的logDir指的是Log对象的dir,和log.dirs是不同的概念,可以认为所有Log的dir都是在每个log.dirs下,如果把Log.dir叫做Partition级别的文件夹,则checkpoint文件和Partition文件夹是同一层级。
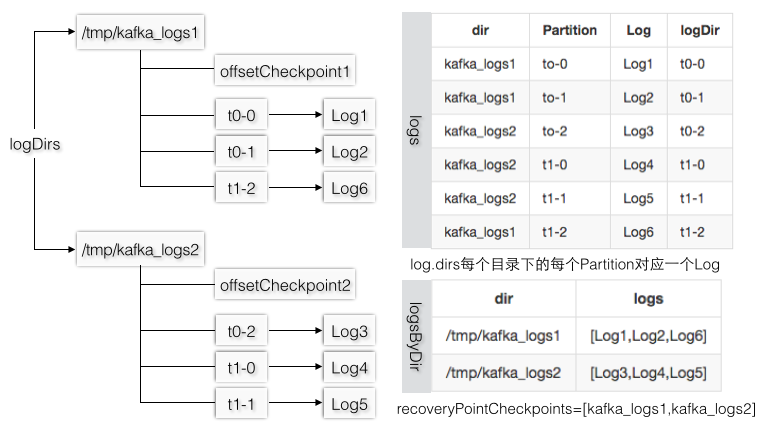
图3-26 日志的组织方式和对应的数据结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | class LogManager(val logDirs: Array[File]){
val logs = new Pool[TopicAndPartition, Log]()
val recoveryPointCheckpoints=logDirs.map((_,new OffsetCheckpoint(new File(_,"checkpoint"))))
loadLogs() //启动LogManager实例时,如果已经存在日志文件,要把它们加载到内存中
private def loadLogs(): Unit = {
val threadPools = mutable.ArrayBuffer.empty[ExecutorService]
for (dir <- this.logDirs) { //按照log.dirs创建线程池,如果只配置一个目录就只有一个线程池
val pool = Executors.newFixedThreadPool(ioThreads)
threadPools.append(pool)
//checkpoint文件一个日志目录只有一个,并不是每个Partition级别!
//既然所有Partition公共一个checkpoint文件,那么文件内容当然要有Partition信息
var recoveryPoints:Map[TopicAndPartition,Long]=recoveryPointCheckpoints(dir).read
val jobsForDir = for {
dirContent <- Option(dir.listFiles).toList //日志目录下的所有文件/文件夹
logDir <- dirContent if logDir.isDirectory //Partition文件夹,忽略日志目录下的文件
} yield {
CoreUtils.runnable { //每个Partition文件夹创建一个线程,由线程池执行
val topicPartition = Log.parseTopicPartitionName(logDir)
val config = topicConfigs.getOrElse(topicPartition.topic, defaultConfig)
val logRecoveryPoint = recoveryPoints.getOrElse(topicPartition, 0L) //分区的恢复点
val current = new Log(logDir, config, logRecoveryPoint, scheduler, time) //恢复Log
this.logs.put(topicPartition, current) //这里放入logs集合中,所有分区的Log满血复活
}
}
jobsForDir.map(pool.submit).toSeq //提交任务
}
}
//只有调用loadLogs后,logs才有值,后面的操作都依赖于logs
def allLogs(): Iterable[Log] = logs.values
def logsByDir = logs.groupBy{case (_,log)=>log.dir.getParent}
val cleaner: LogCleaner = new LogCleaner(cleanerConfig,logDirs,logs)
def startup() {
scheduler.schedule("log-retention", cleanupLogs)
scheduler.schedule("log-flusher", flushDirtyLogs)
scheduler.schedule("recovery-point-checkpoint",checkpointRecoveryPointOffsets)
if(cleanerConfig.enableCleaner) cleaner.startup()
}
} |
| 线程/任务 | 方法 | 作用 |
|---|---|---|
| 日志保留任务(log retention) | cleanupLogs | 删除失效的Segment或者为了控制日志文件大小要删除一些文件 |
| 日志刷写任务(log flusher) | flushDirtyLogs | 根据时间策略,将还在操作系统缓存层的文件刷写到磁盘上 |
| 检查点刷写任务(checkpoint) | checkpointRecoveryPointOffsets | 定时地将checkpoint恢复点状态写到文件中 |
| 日志清理线程(cleaner) | cleaner.startup() | 日志压缩,针对带有key的消息的清理策略 |
日志文件和checkpoint的刷写
flush都只是将当前最新的数据写到磁盘上。checkpoint检查点也叫做恢复点(顾名思义是从指定的点开始恢复数据),log.dirs的每个目录下只有一个所有Partition共享的全局checkpoint文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | //日志文件刷写任务
private def flushDirtyLogs() = {
for ((topicAndPartition, log) <- logs) {
val timeSinceLastFlush = time.milliseconds - log.lastFlushTime
if(timeSinceLastFlush >= log.config.flushMs) log.flush
}
}
//checkpoint文件刷写任务
def checkpointRecoveryPointOffsets() {
this.logDirs.foreach(checkpointLogsInDir)
}
private def checkpointLogsInDir(dir: File): Unit = {
val recoveryPoints = this.logsByDir.get(dir.toString) //checkpoint是log.dirs目录级别
//logsByDir对于每个dir都有多个Partition对应的Log,所以mapValues对每个Log获取recoveryPoint
recoveryPointCheckpoints(dir).write(recoveryPoints.get.mapValues(_.recoveryPoint))
}
//只有flush的时候才会更新恢复点,不过flush并不是每次写都会发生的
def flush(offset: Long) : Unit = {
if (offset <= this.recoveryPoint) return
for(segment<-logSegments(this.recoveryPoint,offset)) //选择恢复点和当前之间的Segment
segment.flush() //会分别刷写log数据文件和index索引文件(调用底层的fsync)
if(offset > this.recoveryPoint) {
this.recoveryPoint = offset //recoveryPoint实际上是offset
lastflushedTime.set(time.milliseconds)
}
} |
3.3.1 日志清理
清理日志实际上是清理过期的Segment,或者日志文件太大了需要删除最旧的数据,使得整体的日志文件大小不超过指定的值。举例用队列来缓存所有的请求任务,每个任务都有一定的存活时间,超过时间后任务就应该自动被删除掉,同时队列也有一个上限,不能无限制地添加任务,如果超过指定大小时,就要把最旧的任务删除掉,以维持队列的固定大小,这样可以保证队列不至于无限大导致系统资源被耗尽。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | //日志清理任务
def cleanupLogs() {
for(log <- allLogs; if !log.config.compact)
cleanupExpiredSegments(log) + cleanupSegmentsToMaintainSize(log)
}
private def cleanupExpiredSegments(log: Log): Int = {
log.deleteOldSegments(time.milliseconds-_.lastModified>log.config.retentionMs)
}
private def cleanupSegmentsToMaintainSize(log: Log): Int = {
var diff = log.size - log.config.retentionSize
def shouldDelete(segment: LogSegment) = {
if(diff - segment.size >= 0) {
diff -= segment.size
true
} else false
}
log.deleteOldSegments(shouldDelete)
} |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | def deleteOldSegments(predicate: LogSegment => Boolean): Int = {
//logSegments是Log的所有Segment,s是每个Segment
val deletable = logSegments.takeWhile(s => predicate(s))
if(segments.size == numToDelete) roll()
deletable.foreach(deleteSegment(_))
}
private def deleteSegment(segment: LogSegment) {
segments.remove(segment.baseOffset) //删除数据结构
asyncDeleteSegment(segment) //异步删除Segment
}
private def asyncDeleteSegment(segment: LogSegment) {
segment.changeFileSuffixes("", Log.DeletedFileSuffix)
def deleteSeg() = segment.delete() //和flush一样最后调用log和index.delete
scheduler.schedule("delete-file", deleteSeg)
} |
3.3.2 日志压缩
不管是传统的RDBMS还是分布式的NoSQL存储在数据库中的数据总是会更新的,相同key的新记录更新数据的方式简单来说有两种:直接更新(找到数据库中的已有位置以最新的值替换旧的值),或者以追加的方式(保留旧的值,查询时再合并,或者也有一个后台线程会定期合并)。采用追加记录的做法在节点崩溃时可以用于恢复数据,还有一个好处是写性能很高,因为这样在写的时候就不需要查询操作,这也是表3-8中很多和存储相关的分布式系统都采用这种方式的原因,它的代价就是需要有Compaction操作来保证相同key的多条记录需要合并。| 分布式系统 | 更新数据追加到哪里 | 数据文件 | 是否需要Compaction |
|---|---|---|---|
| ZooKeeper | log | snapshot | 不需要,因为数据量不大 |
| Redis | aof | rdb | 不需要,因为是内存数据库 |
| Cassandra | commit log | data.db | 需要,数据存在本地文件 |
| HBase | commit log | HFile | 需要,数据存在HDFS |
| Kafka | commit log | commit log | 需要,数据存在Partition的多个Segment里 |
Kafka中如果消息有key,相同key的消息在不同时刻有不同的值,则只允许存在最新的一条消息,这就好比传统数据库的update操作,查询结果一定是最近update的那一条,而不应该查询出多条或者查询出旧的记录,当然对于HBase/Cassandra这种支持多版本的数据库而言,update操作可能导致添加新的列,查询时是合并的结果而不一定就是最新的记录。图3-27中示例了多条消息,一旦key已经存在,相同key的旧的消息会被删除,新的被保留。
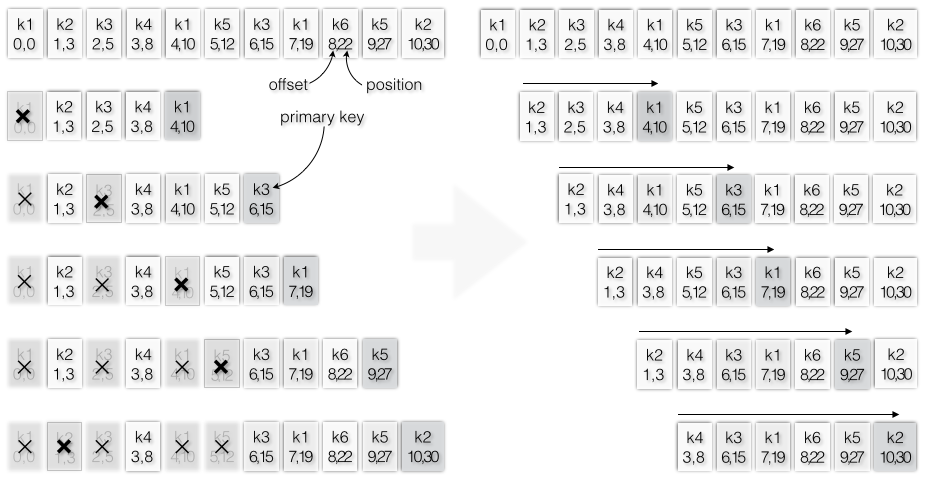
图3-27 更新操作要删除旧的消息
Kafka的更新操作也采用追加(commit log就是追加)也需要有Compaction操作,当然它并不是像上面那样一条消息一条消息地比较,通常Compaction是对多个文件做一次整体的压缩,图3-28是Log的压缩操作前后示例,压缩确保了相同key只存在一个最新的value,旧的value在压缩过程会被删除掉。
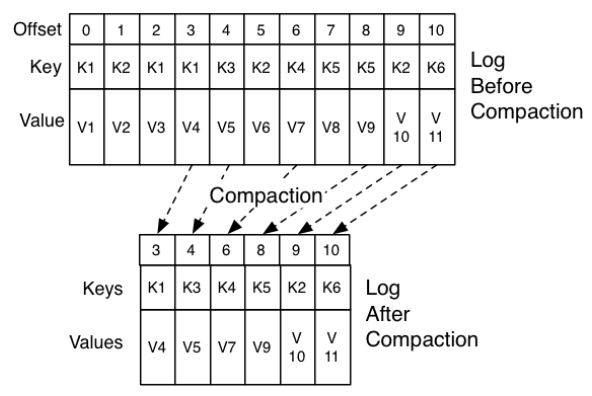
图3-28 LogCompaction的过程
每个Partition的(Leader Replica的)Log有多个Segment文件,为了不影响正在写的最近的那个activeSegment,日志压缩不应该清理activeSegment,而是清理剩下的所有Segment。清理Segment时也不是一个个Segment慢吞吞地清理,也不是一次性所有Segment想要全部清理,而是几个Segment分成一组,分批清理。清理线程会占用一定的CPU,因为要读取已有的Segment并压缩成新的Segment,为了不影响其他组件(主要是读,因为读操作会读取旧的Segment,而写不会被影响因为写操作只往activeSegment写,而activeSegment不会被清理),可以设置清理线程的线程个数,同时Kakfa还支持Throttler限速(读取旧的Segment时和写入新的Segment都可以限速)。当然也并不是每个Partition在同一时间都进行清理,而是选择其中最需要被清理的Partition。
清理/压缩指的是删除旧的更新操作,只保留最近的一个更新操作,清理方式有多种,比如JVM中的垃圾回收算法将存活的对象拷贝/整理到指定的区域,HBase/Cassandra的Compaction会将多个数据文件合并/整理成新的数据文件。Kafka的LogCleaner清理Log时会将所有的Segment在CleanerPoint清理点位置分成Tail和Head两部分,图3-29中每条消息所在的Segment并没有画出来(这些消息可能在不同的Segment里),因为清理是以Partition为级别,就淡化了Segment的边界问题,不过具体的清理动作还是要面向Segment,因为复制消息时不得不面对Segment文件。
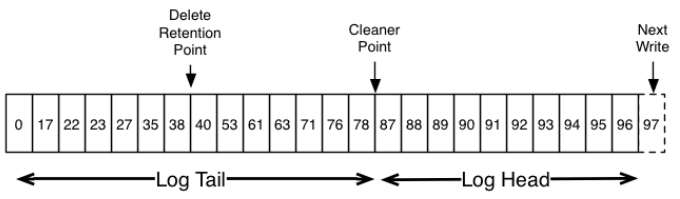
图3-29 Log包括Tail和Head两部分
清理后Log Head部分每条消息的offset都是逐渐递增的,而Tail部分消息的offset是断断续续的。
LogToClean表示需要被清理的日志,其中firstDirtyOffset会作为Tail和Head的分界点,图3-20中举例了在一个Log的分界点发生Compaction的步骤。
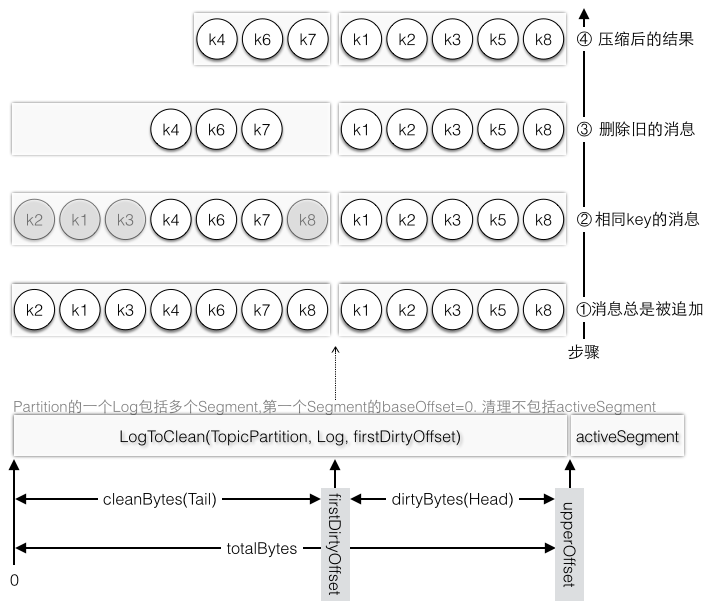
图3-30 日志分成Tail和Head的消息压缩步骤
每个Partition的Log都对应一个LogToClean对象,在选择哪个Partition需要优先做Compaction操作时是依据cleanableRatio的比率即Head部分大小(dirtyBytes)除于总大小中最大的,假设日志文件一样大,firstDirtyOffset越小,dirtyBytes就越大。而firstDirtyOffset每次Compaction后都会增加,所以实际上选择算法是优先选择还没有发生或者发生次数比较少的Partition,因为这样的Partition的firstDirtyOffset没有机会增加太多。
1 2 3 4 5 6 7 8 9 | case class LogToClean(topicPartition: TopicAndPartition, log: Log,
firstDirtyOffset: Long) extends Ordered[LogToClean] {
val cleanBytes = log.logSegments(-1, firstDirtyOffset).map(_.size).sum
val dirtyBytes = log.logSegments(firstDirtyOffset,
math.max(firstDirtyOffset, log.activeSegment.baseOffset)).map(_.size).sum
val cleanableRatio = dirtyBytes / totalBytes.toDouble
def totalBytes = cleanBytes + dirtyBytes
override def compare(th:LogToClean)=math.signum(this.cleanableRatio-th.cleanableRatio)
} |
任何消费者如果能够赶上Log的Head部分,它就会看到写入的每条消息,这些消息都是顺序递增(中间不会间断)的offset
总是维持消息的有序性,压缩并不会对消息进行重新排序,而是移除一些消息
每条消息的offset永远不会被改变,它是日志文件标识位置的永久编号
读取/消费时如果从最开始的offset=0开始,那么至少可以看到所有记录按照它们写入的顺序得到的最终状态(状态指的是value,相同key不同value,最终的状态以最新的value为准):因为这种场景下写入顺序和读取顺序是一致的,写入时和读取时offset都是不断递增。举例写入key1的value在offset=1和offst=5的值分别是v1和v2,那么读取到offset=1时,最终的状态(value值)是v1,读取到offset=5时,最终状态是v2(不能指望说读取到offset=1时就要求状态是v2)
3.4 层级时间轮
3.4.4 定时器Timer
那么Kafka的Timer定时器是如何存储DelayedOperation,又是如何在有任务超时的时候能准确地轮询出来。在Java中有多种方案可以做到任务的延迟执行,比如java.util.Timer和TimerTask的调度,或者DelayedQueue和实现Delayed接口的线程。但这些对于Kafka这种动辄成千上万个请求的分布式系统而言都过于重量级,所以Kafka的Timer专门设计了TimingWheel这个数据结构来存储大量的处理请求,不过它的底层还是基于DelayedQueue实现的。被放到延迟队列的每个元素必须实现Delayed接口,本来可以直接将DelayedOperation放入队列中(任务失效的时候是一个一个弹出),不过因为DelayedOperation数量级太大了,可以将多个DelayedOperation组成一个TimerTaskList链表(在同一个列表中的所有任务的失效时间都很相近,但不一定都相等),以TimerTaskList作为队列的元素,所以失效时间会被设置到TimerTaskList上,当失效的时候,整个列表中的所有任务都会一起失效。
1. 定时任务链表和条目
2. TimingWheel时间轮
Purgatory将任务添加到Timer定时器,并且会在Reaper线程中调用advanceClock不断地移动内部的时钟,使得超时的任务可以被取出来执行。任务加入到TimingWheel中需要首先被包装成TimerTaskEntry,然后TimingWheel会根据TimerTaskEntry的失效时间加入到某个TimerTaskList中(TimingWheel的某个bucket)。当TimerTaskList因为超时被轮询出来并不一定代表里面所有的TimerTaskEntry一定就超时,所以对于没有超时的TimerTaskEntry需要重新加入到TimingWheel新的TimerTaskList中,对于超时的TimerTaskEntry则立即执行任务。不过
timingWheel.add添加任务时并不需要先判断有没有超时然后再做决定,而是不管三七二十一,先尝试加入TimerTaskEntry,如果添加成功,那很好;如果没有添加成功,说明这个任务要么已经被取消了,要么超时了。
添加不成功有两种情况,1)被其他线程完成后任务会被取消,这样保证了只有最先完成的那个线程只会调用一次完成的方法,其他线程就不再需要执行这个任务了。2)任务超时了,但还没有被其他线程完成即还没有被取消,当前线程就应该立即执行任务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 2728 | class Timer(taskExecutor:ExecutorService, tickMs:Long=1,wheelSize:Int=20,
startMs: Long = System.currentTimeMillis) {
val delayQueue = new DelayQueue[TimerTaskList]() //延迟队列,按照失效时间排序
val taskCounter = new AtomicInteger(0) //内存级别的原子共享变量,所有时间轮同一个计数器
val timingWheel=new TimingWheel(tickMs,wheelSize,startMs,taskCounter,delayQueue)
def add(timerTask: TimerTask) = { //1.DelayedOperation是一个TimerTask
addTimerTaskEntry(new TimerTaskEntry(timerTask)) //2.被包装成定时任务条目
}
val reinsert=(entry:TimerTaskEntry) => addTimerTaskEntry(entry)//高阶函数
//add和reinsert都会将TimerTaskEntry加入到时间轮,后者使用已有的TimerTaskEntry
def addTimerTaskEntry(timerTaskEntry: TimerTaskEntry) {
val addSuccess = timingWheel.add(timerTaskEntry) //3.添加到时间轮中
if (!addSuccess) { //添加不成功,要么被取消,要么超时了
if (!timerTaskEntry.cancelled) //还没有被取消,那就是超时了
taskExecutor.submit(timerTaskEntry.timerTask) //执行条目里的定时任务
}
}
def advanceClock(timeoutMs: Long): Boolean = { //timeout是轮询的最长等待时间
var bucket=delayQueue.poll(timeoutMs, TimeUnit.MILLISECONDS)//没有到超时不会被轮询出
if (bucket != null) { //从延迟队列轮询出存储的TimerTaskList
while (bucket != null) { //一次可能会轮询出多个元素,当并不一定是延迟队列所有元素
timingWheel.advanceClock(bucket.getExpiration())
bucket.flush(reinsert) //重新插入,函数的entry参数只有真正调用flush方法才能知道
bucket=delayQueue.poll() //立即再轮询一次(不等待),直到poll出来没有东西了才停止
}
}
}
} |
图3-73 现实世界的时钟/计时器示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 4243 | private[timer] class TimingWheel(tickMs:Long,wheelSize:Int,startMs:Long,
taskCounter: AtomicInteger, queue: DelayQueue[TimerTaskList]) {
val interval = tickMs * wheelSize
val buckets = Array.tabulate[TimerTaskList](wheelSize) {
_ => new TimerTaskList(taskCounter) } //每个List共享taskCount计数器
var currentTime = startMs - (startMs % tickMs)
@volatile var overflowWheel: TimingWheel = null
def addOverflowWheel(): Unit = {
if (overflowWheel == null) { //创建父级别的时间轮
overflowWheel = new TimingWheel(
tickMs = interval, //低级别的整个范围作为父级别一个tick
wheelSize = wheelSize, //bucket的数量不变
startMs = currentTime, //当前时间通过advanceClock会更新
taskCounter = taskCounter, queue //全局唯一的计数器和延迟队列
)
}
}
def add(timerTaskEntry: TimerTaskEntry): Boolean = {
val expiration = timerTaskEntry.expirationMs
if (timerTaskEntry.cancelled) { //被其他线程取消了(执行任务时会取消)
false
} else if (expiration < currentTime + tickMs) { //已经超时了
false
} else if (expiration < currentTime + interval) {
val virtualId = expiration / tickMs
val bucket = buckets((virtualId % wheelSize.toLong).toInt)
bucket.add(timerTaskEntry) //把任务根据失效时间点放到对应的bucket中
//设置bucket的失效时间点,然后把bucket加入队列中
if (bucket.setExpiration(virtualId * tickMs)) queue.offer(bucket)
true
} else {
if (overflowWheel == null) addOverflowWheel()
overflowWheel.add(timerTaskEntry)
}
}
def advanceClock(timeMs: Long): Unit = {
if (timeMs >= currentTime + tickMs) {
currentTime = timeMs - (timeMs % tickMs)
if (overflowWheel != null)
overflowWheel.advanceClock(currentTime)
}
}
} |
1s*8=8s,Reaper线程循环时轮询一次队列最长timeoutMs=200ms,添加的四个任务的超时时间分别是[A=0s,B=1s,C=1s,D=3s]。添加任务时,任务
A=0s<currentTime+tickMs=0s+1s=1s,所以任务A添加失败,执行
executor.submit,表示任务A已经超时了;任务B/C/D满足
1s=currentTime+tickMs<=expiration<currentTime+interval=8s,所以可以成功加入队列,不会执行
executor.submit,表示它们都还没有到执行的时间点。B/C会加入bucket=1%8=1,D加入的bucket=3%8=3。然后Reaper线程开始调用advanceClock,当前时间=0s,在timeout=200ms内并不会从队列中轮询出来任何元素,因为即使200ms过去了,当前时间是200ms,而队列中最先可以被弹出来的都是1s,所以Reaper线程继续调用了多次轮询方法:200ms,400ms,600ms,800ms。
在800ms时间点调用轮询时,timeoutMs=200ms,这时候可以终于把bucket1轮询出来(因为800ms时间点+200ms时间间隔=1000ms=1s,而刚好队列中存在延迟时间=1s的bucket),这个bucket1中有两个任务B/C,它们的失效时间都是1s,而且bucket级别的expiration=1s(加入任务时同时确定bucket的失效时间),首先通过advanceClock更新currentTime=1s。
bucket.flush会尝试将任务B/C重新加入队列中,由于此时currentTime已经被更新为1s,B/C的超时时间=
1s<currentTime+tickMs=1s+1s=2s,所以此时添加到队列会失败,于是和最开始的A类似执行
executor.submit,也表示任务B/C在当前时间点=800ms时刻的轮询过程中超时了。由于Reaper线程还有其他工作所以即使每次轮询的timeout=200ms,也不一定说每次发生轮询的时间点就是[200m,400ms,600ms]这么刚好,假设轮询的时间点是900ms,那么不用等timeout=200ms只过了100ms就可以把失效时间=1s的bucket轮询出来。图3-74示例了Timer调用TimingWheel添加任务和时钟移动的调用过程,这里为了简单起见,还没有考虑
overflowWheel的场景。

图3-74 Timer和TimingWheel的调用示例(没有二级时间轮)
失效时间和bucket选择
任务的失效时间是一个确定的时间点,所以不管当前时间是什么,即使失效时间相同的两个任务在不同时间点加入队列,它们也会被放入同一个bucket中。当然根据任务的失效时间选择不同的bucket还跟tickMs以及时间轮的大小有关,时间轮的expiration范围
expiration=[currentTime+tickMs,currentTime+interval)。图3-75中示例了在相同时间轮大小下三种不同的tickMs,当tickMs=1时,每个bucket中任务的失效时间只有一个值,当tickMs=2时有两种可能,当tickMs=8时就有8种可能,比如失效时间在120-127范围内的任务都会被分配到bucket7中。即使是相同失效时间如果tickMs不同也会被放入不同的bucket,比如任务失效时间=103在tickMs=1时分配到bucket7,在tickMs=2时分配到bucket3。
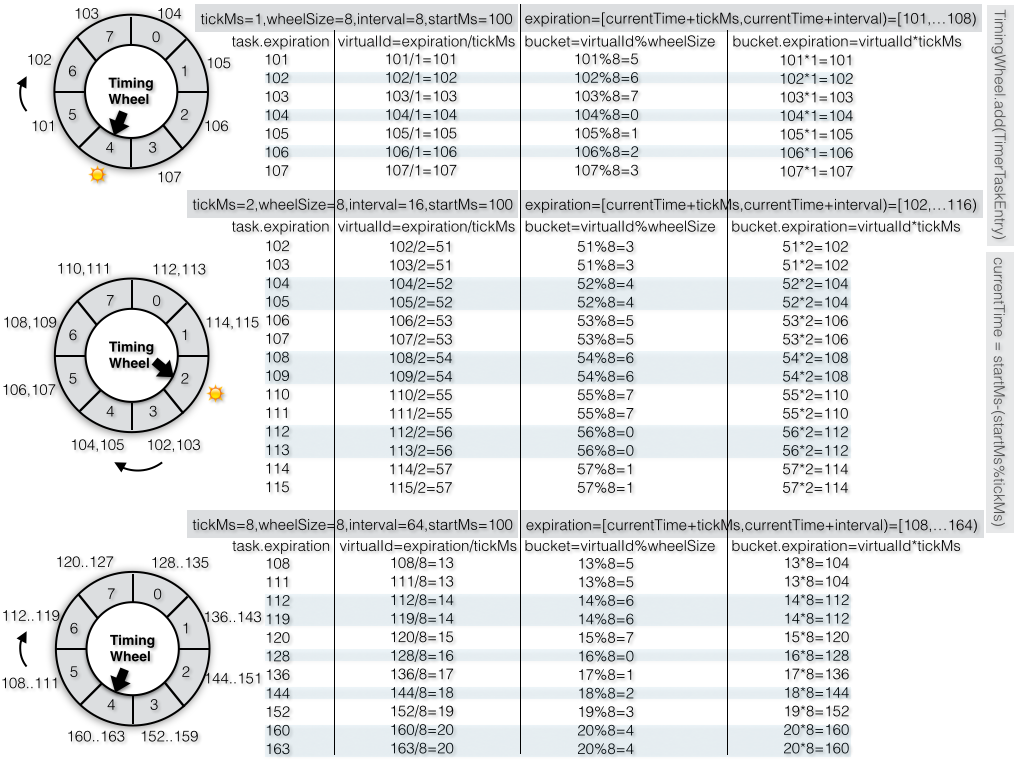
图3-75 相同时间轮,不同tickMs
由tickMs和时间轮的大小决定了这个时间轮所有任务失效时间的一个范围,如果超过这个范围,则不允许加入,图3-76中当前时间等于100时,时间轮的范围=[101..107],当前时间等于101时,范围=[102..108]以此类推。当前时间所在的bucket实际上是没有任务的,因为任务的失效时间如果和当前时间相等说明任务已经失效了,不应该放入队列中。
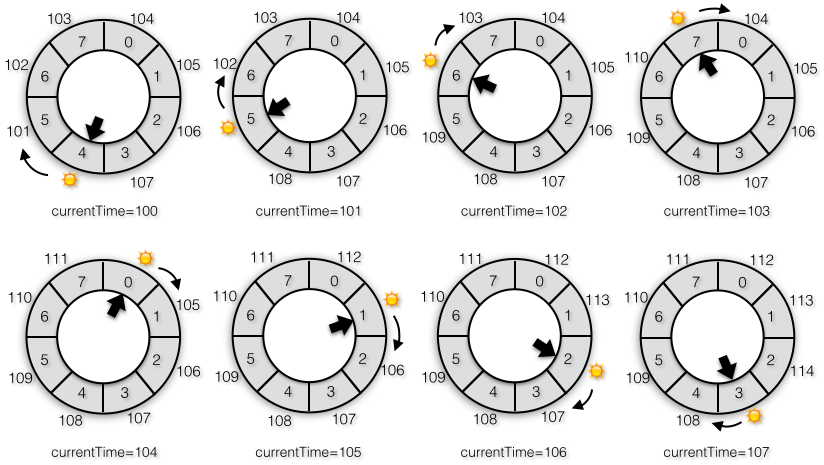
图3-76 时钟tick影响了时间轮的取值范围
任务的失效时间和当前时间相等指的是完全相等,比如tickMs=1s,时间轮大小=60,当前时间等于12:00:00,某个任务的超时时间是12:01:00。时钟tick时每隔一秒走动一次:[12:00:01,..12:00:59,12:01:00],在12:01:00这一刻任务就超时了,不是12:01:00到下一次tick=12:01:01的一半12:01:00.500,也不是过了12:01:00后的下一次tick=12:01:01才超时,当刚刚好进入12:01:00.000时任务就超时了!比如你定了一个12:01:00的任务运行,你当然希望在那个时间点分毫不差地精准地执行任务,多一秒少一秒都不行!
层级时间轮
只有一个时间轮虽然在时间移动时可以重用旧的bucket来保存失效时间更往后的任务,但是由于时间轮所允许的范围就那么大,超过这个范围的失效时间就无法很好地存储了。还是以tickMs=1s,时间轮大小=60为例,如果当前时间是12:00:00,你无法设置12:01:01的任务,更谈不上12:02:00以及失效时间更加往后的任务了。在《嵌入式系统的实时概念》第十一章提到使用一个外部的
event flow buffer来暂时存储超过interval的事件,不过更好的方式是使用层级的时间轮。层级时间轮中假设时间轮大小都不变,但是tickMs则是不断递增,假设Level0的tickMs=1s,则Level1的tickMs=
1s*60=60s,Level2的tickMs=
60s*60=3600s以此类推。每一层的tickMs表示的是在当前时间轮中移动一格的粒度/单位,Level0=1s,Level1=60s,Level2=3600s。可以用钟表的秒钟,分针,时针的移动来理解这三个时间轮:秒针走动一格需要花费一秒,分针走动一格花费60秒,时针走动一格花费3600秒。而且更高层级的tickMs等于低一层的整个时间轮范围,比如Level0的interval=
1s*60=60s,刚好作为Level1的tickMs,Level1的interval=
60s*60=3600s,也作为Level2的tickMs。也就是说Level1的一格等于Level0走完一圈,Level2的一格等于Level1走完一圈。
那么为什么tickMs的单位不同,假设有几个任务的失效时间分别是[20s,60s,70s,120s,3600s],如果所有时间轮的tickMs都是1s,总共需要3600/60=60个时间轮!既然每个时间轮的tickMs都相等,跟直接用一个大小等于3600的时间轮是没有任何区别的。而如果使用层级时间轮,总共只需要3个时间轮,20s在Level0的第20个单元格,60s和70s在Level1的第一个单元格内,120s在Level1的第二个单元格上,3600在Level2的第一个单元格上(思考下为什么要把60s这种刚好等于当前时间轮范围的任务放在下一个时间轮,而不是当前时间轮上)。
confluent有篇博客详细介绍了时间轮的改进和性能对比,图3-77中当前指针指向任务①所在的bucket,则任务①已经超时了,当发生一次tick之后,任务①已经彻底从队列中移除了,tick一次之后当前指针指向了任务②所在的bucket,因为任务②也已经超时了,也就是说tick指针指向哪里,那里就已经超时了,在当前指针所指向的bucket里的任务都应该被取出来执行。
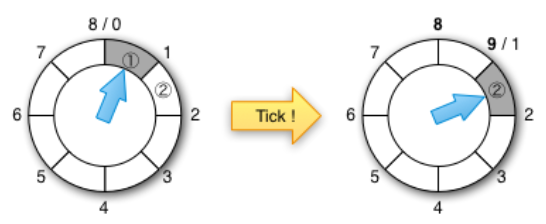
图3-77 时间轮tick到当前bucket,这个bucket的任务都超时
摘自:http://www.confluent.io/blog/apache-kafka-purgatory-hierarchical-timing-wheels
图3-78有两个时间轮分别是Level0和Level1,在Time0时加入了⑦⑧⑨三个任务,任务⑦在Level0的7-8之间,任务⑧⑨在Level1的8-16之间。这里你可能会认为⑧和⑨应该紧接着Level0的7-8的下一个应该放在Level1的0-8,这样才叫做无缝衔接嘛。不过如果把⑧⑨放在Level1的0-8之间,
1)本身就不符合取值范围,因为⑧⑨在0-8之外,而放在8-16之间正好满足⑧⑨的取值范围。
2)Level1当前指向了0-8表示这个区间的所有任务都已经超时,如果⑧⑨放在这里,那么它们就都会超时,而此时连任务⑦都还没超时,⑧⑨怎么可能超时呢。
3)Level1的0-8这一格子对应了Level0的所有格子,所以Level1指向0-8表示任务在0-8之间的正在超时,不过具体0-8之间的任务则还是以Level0为准,这就好比在Time8时,Level1指向了8-16,表示8-16之间的任务正在超时,但是具体8-16之间的任务也是以Level0为准。
在Time0之后发生一次Tick后,Level0的指针指向1-2,而Level2的指针没有变化,而Level0的0消失,1添加了9。图3-78中当前时间=Time7时,Level0的指针指向了7-8之间,Level2的指针还是没有变化,任务⑦超时。再次发生tick之后,指针移动到8-9(这里已经不是0-1了),这时候Level1的指针终于移动了一格从原先的0-8移动到8-16(想象下秒针走了一圈60s,分针才终于挪动了一格)。而Level1原先在8-16之间存在任务⑧⑨,那么是不是说这两个任务同时失效了呢?实际上外界真实时钟走动的粒度只和第一个时间轮Level0的tickMs相等,Level1走动一格只表示当前这一格的所有任务在Level0走完一圈后都会失效,就好比Level1指向0-8时表示Level0中任务时间在0-8之间只有Level0走完一圈才会全部失效。因此需要把Level1的任务⑧⑨从Level1中解除出来,放到更细粒度的Level0中才能真正决定任务什么时候真正失效。所以在Timer8时,Level1的任务⑧⑨被一一放回Level0的各个bucket中,原先在Level1中挤在同一个单元格里的多个任务被分散在Level0的各个单元格中,这样原先在Level1的各个任务现在就会参照Level0中的tickMs(也就是真实的tickMs)。

图3-78 层级时间轮的收敛和发散
可以这么理解,在Time0到Time7之间,任务⑧⑨在Level1中蓄势待发,但是因为Level0还没有走完一圈,Level1的指针不会移动,只有Level0走完一圈后,Level1才会移动一次,并把Level1一格的任务按照Level0的tickMs粒度重新划分。Level0代表的永远是真实的时钟移动,超时的任务一定是在Level0中被选中的,在其他Level中的任务在接近超时的时候只会源源不断地进入到Level0中。可以认为除了Level0,其他Level都是虚拟出来的时间轮,这些更高级的时间轮因为tickMs粒度比较大,可以存储数据量更大的任务,但是不具备执行超时任务的能力,当高级别的时间轮发生一次tick后,需要把tick指向的所有任务移动到低级别的时间轮中,从而有机会被放到Level0中真正地执行。
第四章:消费者(高级和低级API)
概述
生产者发送消息时在客户端就按照节点和Partition进行分组,属于同一个目标节点的多个Partition会作为同一个请求传送到服务端,作为目标节点的服务端也可以处理来自不同生产者客户端的请求。如果从网络层通信来看,客户端和服务端都会使用队列的方式确保顺序地客户端发送请求,服务端接收请求,服务端发送响应,客户端接收响应。从存储层来看,生产者会将消息分发到不同节点的不同Partition上,服务端的一个Partition的数据会来源于多个生产者。多个服务端节点组成的Kafka集群在物理层将消息分布在不同节点的不同Partition上,并且是以提交日志的形式追加到每个Partition中。对消息进行分区的好处是可以将大量的消息分成多批数据同时写到不同节点上,将写请求分担负载到各个节点。消息系统的组成是生产者,存储系统和消费者,消费者会从存储系统读取生产者写入的消息。Kafka作为分布式的消息系统支持多个生产者和多个消费者,生产者可以将消息分布到集群中不同节点的不同Partition上,消费者也可以消费集群中多个Partition的多个Partition。写消息时允许多个生产者写到同一个Partition中,不过如果读消息时有多个消费者要同时读取同一个Partition,就需要在Partition级别的日志文件上控制确保将日志文件的不同数据分配给不同的消费者(不应该将同一份数据分配给两个相同的消费者,否则同一条消息就被重复处理了,虽然Kafka本身在消费者出现故障时可能会重复处理消息,但是如果在正常消费时就开始重复处理,这条路显然走不通),这种控制手段通常采用加锁同步严重影响性能的方式,所以如果我们约定同一个Partition只允许被一个消费者处理就不需要加锁同步了,不存在并发访问了,可以大大提升消费者的处理能力,而且也并不违反消息的处理语义:原先需要多个消费者处理,现在交给一个消费者处理也不是不可以,只要有消费者处理消息就可以了。
图4-1举例了一种最简单的消息系统部署模式,生产者的数据源多种多样,它们都统一写入到Kafka集群中,处理消息时有多个消费者进行任务分担,这些消费者的处理逻辑都是相同的,每个消费者处理的Partition都是不会重复的。
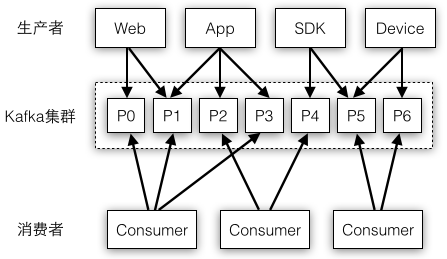
图4-1 消息系统包括生产者、消费者和存储系统
不过实际应用中消息通常存在多种处理方式,将图4-1中的多个消费者放到同一个消费组中,不同的消费组都可以有数量不同的消费者,比如可以根据实际情况对业务逻辑比较重要的消费组分配更多的消费者资源。图4-2示例了将消息系统作为数据处理系统的核心,消费组1将消息存储到Hadoop供离线分析,消费组3将消息存储到搜索引擎中,消费组2读取出消息时使用Storm/Spark等流处理系统进行实时分析。
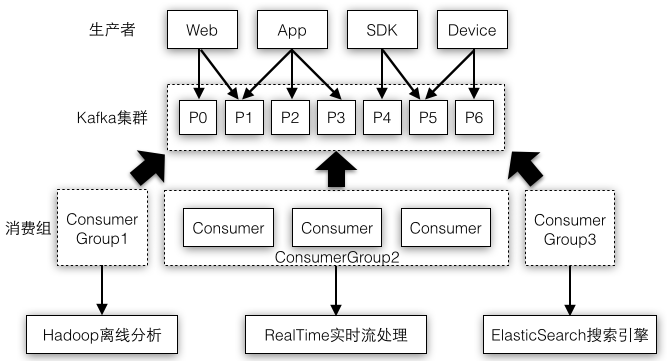
图4-2 不同消费组消费同一份消息
Kafka采用消费组保证了:一个Partition只允许被一个消费组中的一个消费者所消费,得出的结论是:在一个消费组中,一个消费者可以消费多个Partition,不同的消费者消费的Partition一定不会重复,所有消费者一起消费所有的Partition;在不同消费组中,每个消费组都会消费所有的Partition。也就是同一个消费组下消费者对Partition是互斥的,而不同消费组之间是共享的。比如有两个消费者订阅了一个topic,如果这两个消费者在不同的消费组中,则每个消费者都会获取到这个topic所有的记录;如果这两个消费者是在同一个消费组中,则它们会各自获取到一半的记录(两者的记录是对半分的,而且都是不重复的)。图4-3示例了多个消费者都在同一个消费组中(右图)或者各自组成一个消费组(左图)的不同消费场景,这样Kafka也可以实现传统消息队列的发布订阅模型和队列模型:
同一条消息会被多个消费组消费,如果有多个消费组,每个消费组只有一个消费者,实现广播(发布订阅模式)
只有一个消费组,这个消费组有多个消费者,一条消息只会被这个消费组的一个消费者所消费,实现单播(队列模式)
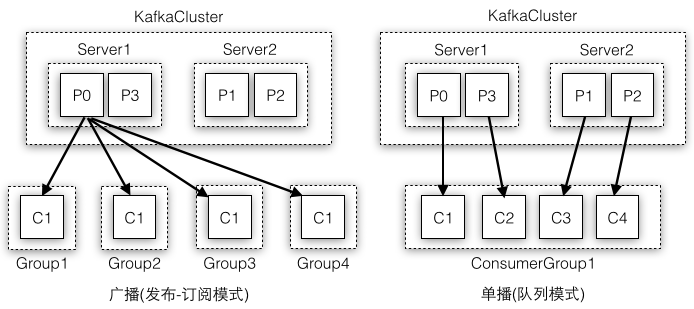
图4-3 传统消息队列的发布订阅模型和队列模型
实际应用中如图4-4消费者和消费组的组成通常是有多个消费组,并且每个消费组中也有多个消费组,这样既可以允许多种不同业务逻辑的消费组存在,也保证了同一个消费组内的多个消费者的协调工作,避免一个消费组只有一个消费者引起的数据丢失。
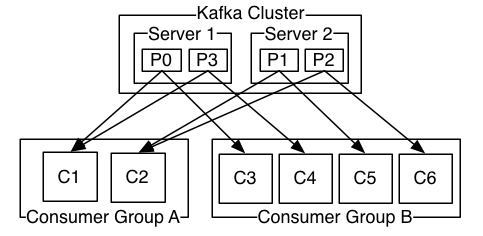
图4-4 Kafka集群的典型部署方式
图片引自:http://kafka.apache.org/documentation.html
Kafka使用消费组的概念,允许一组消费者进程对消费和读取记录的工作进行划分,每个消费者都可以配置一个所属的消费组并且订阅某些主题,Kafka会发送每条消息给每个消费组中的一个消费者线程(同一条消息广播给多个消费组,单播给同一组中的消费者),这是通过对每个消费组的所有消费者线程将订阅topic的所有partitions进行平衡负载rebalance,简单点说就是将topic的所有Partition平均负载给消费组中的所有消费者。比如一个topic有4个Partition,一个消费组有2个消费者,则每个消费者都会分配到两个Partition。
一个消费组有多个消费者,因此消费组需要维护所有的消费者,如果一个消费者当掉了,分配给这个消费者的Partition需要被重新分配给相同组的其他消费者;如果一个消费者加入了同一个组,之前分配给其他消费组的Partition需要分配给新加入的消费者。实际上一旦有消费者加入或退出消费组,导致消费组成员列表发生变化,即使Kafka集群的Partition没有变化,消费组中所有的消费者也都要触发重新rebalance的工作。当然如果集群的Partition发生变化,即使消费组成员没有变化,所有的消费者也都要重新rebalance。图4-5中模拟了加入一个新的消费者,导致Partition的分配发生变化从而触发所有消费者都发生了rebalance。
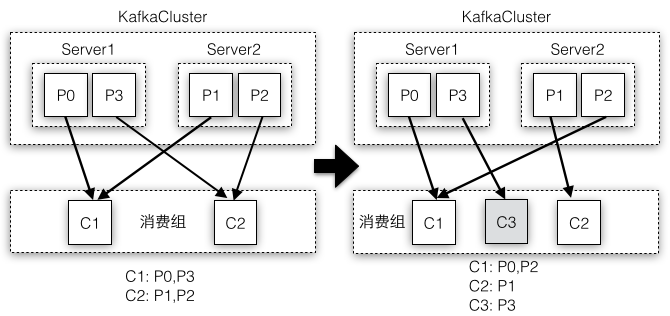
图4-5 消费组成员变化引起所有消费者发生rebalance
消费组中的所有消费者发生rebalance时,消费者在rebalance前后分配到的Partition会完全不同,那么消费者们之间是如何确保各自消费的消息平滑迁移和过渡,假设Partition1原先分配给消费者1,经过rebalance后被分配给了消费者2,在rebalalance前消费者1对Partition1的消费进度需要被保存下来,这样在rebalance后,消费者1可以从保存的进度位置继续读取Partition1,确保了Partition1不管分配给哪个消费者,消息并不会被重复处理。
由于消费者消费消息的最小单元是Partition,所以每个Partition都应该记录消费进度,而且这种数据应该面向消费组级别。假设面向的是消费者级别,relabalce前Partition1只记录到消费者1中,rebalance后Partition1属于消费者2,但是Partition1和消费者2之前没有记录任何信息就无法做到无缝迁移。而如果针对消费组,因为消费者1和消费者2都属于同一个消费组,rebalance前记录Partition1到消费组1,rebalance后消费者2可以正常地读取消费组1的Partition1进度,还是可以准确地还原出这个Partition在消费组1中的最新进度。保存Partition的消费进度通常借助外部的存储系统比如ZooKeeper或者Kafka内部的topic。这样发生reabalance前后Partition的不同拥有者因为读取的是同一份共享存储,消费者成员的变化并不会影响消息的消费和处理。
所以虽然Partition是以消费者级别被消费的,不过Partition的消费进度要保存成消费组级别。消费组虽然是一个包含所有消费者的逻辑概念,它并不执行具体的消息消费逻辑,但是它却把大家都统一起来,如果没有这一层总管,各个消费者之间持有各自的Partition消费进度,但是又不互相认识,在Partition发生变动时,进度消息就没有办法同步给其他消费者。举例现实社会在协作分工时通常都有一个管理员角色(消费组)负责管理所有的工人(消费者),任务(Partition)具体分配给哪些工人都是由管理员决定的。如果工人数量发生变化比如有人加入或离职,或者任务增加或减少,每个工人都会被重新分配到不同的任务。图4-6中消费者消费消息时需要定时地将最新的消费进度保存到ZooKeeper中,当发生rebalance时,新的消费者拥有的新的Partition都可以从ZooKeeper中读取出来恢复到最近的状态。
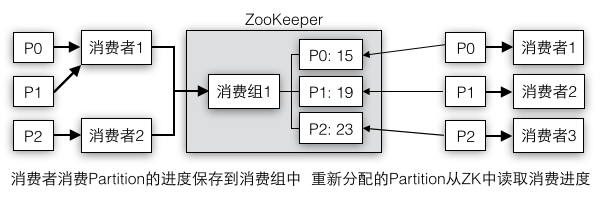
图4-6 消费进度的保存和恢复
负责消费Partition的每个消费者都是一个消费进程,而且消费者本身也可以是多线程的应用程序,因为一个Partition只能属于一个消费者线程,所以存在如下几种不同的场景:
线程数量多于Partition的数量,有部分线程无法消费该topic下任何一条消息
线程数量少于Partition的数量,有一些线程会消费多个Partition的数据
线程数量等于Partition的数量,则正好一个线程消费一个Partition的数据
图4-7分别对应了上面的三种场景,正常情况下采用第二种是最好的,这种方案既不会有第一种的资源浪费想象存在,而且也不会像第三种那样每个线程只负责一点点工作,通过让一个线程消费多个Partition,最大化地榨取每个线程的劳动能力。举例幼儿园的老师将一个蛋糕分成了四块,如果刚好有四个小朋友则每个小朋友都只能分到一块(但是每个人一块可能都吃不饱);如果有五个小朋友,那么有一个小朋友就要眼睁睁地看大家吃蛋糕了(那些分到蛋糕的小朋友很庆幸至少有蛋糕吃);如果有两个小朋友,那他们就可开心了,因为这两个小朋友都能吃到两份蛋糕(任务的资源比消费者多,每个消费者分到不止一个资源,这是最好的情况)。
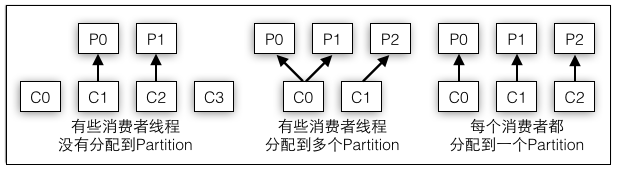
图4-7 消费者线程和Partition的对应关系
虽然允许一个消费者线程消费多个Partition,但并不保证消费者接收到的消息是完全有序的,不过消费同一个Partition的消息则一定是有序的。图4-8的左图示例了消费者分配了Partition0和Partition1,有可能生产端写入不同Partition的消息速度不同,也有可能不同消费者线程之间的消费速度不同,到达消费者客户端的消息可能是Partition0和Partition1的消息混杂在一起的,不过如果单单从Partition0或Partition1而言,日志文件中是什么顺序,接收到的也一定是同样的顺序,比如P0的①②③虽然和P1的①②③鱼龙混杂,但并不会出现到达客户端后P0的①②③变成了其他顺序。
不过即使消费者每次读取的是一个完整的Partition(实际上是不可能的,因为生产者不断地往不同的Partition写数据,消费者要消费多个Partition,怎么判定完整地读取了一个Partition呢),由于生产者写消息时也将消息分散到多个Partition,输入源这边虽然保证了Partition级别的消息有序性,但是所有Partition之间并不是有序的,这就导致了图4-8右图中消费者读取多个Partition时从所有Partition级别上看消息也不是严格有序的。
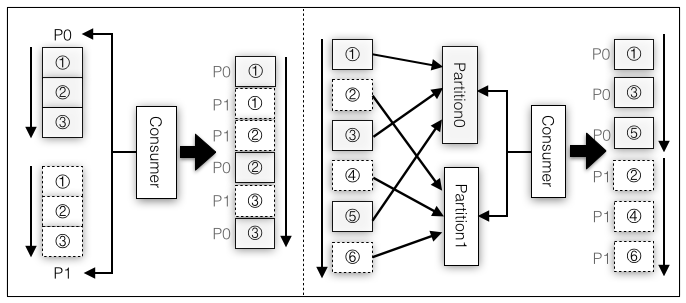
图4-8 消费者读取不同Partition消息的顺序性
生产者的提交日志采用递增的offset连同消息内容一起写入到本地日志文件,生产者客户端本身不需要保存offset相关的状态,而消费者进程则要保存消费消息的offset,因此它是有状态的,这样消费者才能将消息的消费进度保存到ZK或者其他存储系统中。在消费者客户端进程保存offset状态的另一种决定是消费消息采用消费者主动向服务端pull拉取数据,而不是服务端主动向消费者push数据。如果由服务端push推送数据给消费者,消费者只要负责接收数据就可以了,不需要保存任何状态,但是这种方式加重了服务端的负载,因为要在服务端记录每条消息要分配给哪个消费者,还要记录消费者消费到哪里了。消费进度是决定消息是否会被重复处理的关键因素,如果没有记录进度,消费者读取到哪里就一无所知了。
图4-9中左图服务端主动push消息给消费者就要在服务端记录push给消费者的进度,右图中消费者主动pull就在消费者端记录拉取进度,谁掌握了主动权,谁就要负责存储offset。消费者的pull还需要额外依赖外部的ZK,因为每个消费者都是独立的个体,如果要获取所有消费者的消费进度,就要向各个消费者轮询,而使用一个统一的外部存储,每个消费者都往存储系统写数据,读取时只需要和存储系统打交道即可,不过这种方式需要保证消费者将最新的消费进度即使地写到存储系统中,如果没有及时写入就有可能读取出旧的消费进度了。
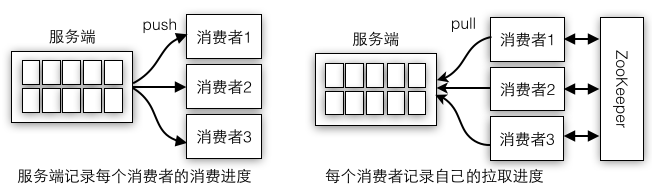
图4-9 消息的push和pull模型
服务端主动push并不需要外部存储是因为服务端本身可以充当管理所有的消费者的角色,但是这种方式的缺点是push只保证把消息推送出去,并没有考虑消费者是否能够及时地处理消息,如果消费者处理不够及时,服务端是否能够感知到并且做出正确的响应比如采用ack机制或者backpressure背压,这种方式实现起来总的来说比较复杂而且在服务端保存所有消费者的消费进度也占用一定的内存。而如果是消费者客户端主动pull,消费者可以按照自己的消费能力消费消息,正所谓能者多劳,性能强的自然消费的快点多点,性能差的消费的慢点少点也是可以接受的。
消费者客户端主动pull并且记录offset状态实际上还有诸多好处,因为消费者可以自己控制offset,如果业务需要,它可以回退到某个offset重新处理消息,或者消息一下子太多处理不过来而又不想处理,可以前进到最近的offset那里继续开始消费。而如果在服务端记录消费者的offset,这一切都无从谈起,因为服务端无法做这种特殊的定制,即使加入了这样的自定义逻辑,服务端的实现也会非常复杂。综合上面这些因素,Kafka的消费者实现采用更高效更具扩展性的push模式消费消息。
不过有时候应用程序从Kafka读取数据,并不太关心消息offset的处理,所以Kafka提供了两种层次的客户端API:1)
Hight Level Consumer高级API提供了一个从Kafka消费数据的高层抽象,消费者客户端代码不需要管理offset的提交,并且采用了消费组的自动负载均衡功能,确保消费者的增减不会影响消息的消费;2)
Low Level Consumer低级API通常针对特殊的消费逻辑(比如客消费者只想要消费某些特定的Partition),低级API的客户端代码需要自己实现一些和Kafka服务端相关的底层逻辑,比如选择Partition的Leader,处理Leader的故障转移等。
表4-1中高级API主要使用了ConsumerGroup语义实现消费者的自动负责均衡,低级API主要针对SimpleConsumer,不过选举Leader,拉取消息这些都要自己去实现,实际应用中高级API虽然功能简单但是用的还是比较多,毕竟越简单的东西越不容易出问题。实际上高级API也会使用SimpleConsumer类完成消息的拉取,不过其他的复杂工作都被封装起来,对客户端代码而言是透明的。
| 客户端API | 主要实现类 | 功能 |
|---|---|---|
| High Level consumer | ConsumerGroup | 通过监听器触发消费者的rebalance,管理offset |
| Low Level consumer | SimpleConsumer | 手动选举leader,拉取消息,处理broker故障 |
上面我们从消费者谈到消费组、消费者线程和Partition的关系、offset的外部存储和push模式,有了这些基础知识的铺垫后,读者最好带着下面这些问题思考Kafka的消费者是如何实现的:
消费组管理所有消费者,消费者领取消费组分配的任务是通过读取ZK完成的,消费者注册ZK监听器并触发rebalance操作
消费者线程拉取Partition数据,一个消费者进程允许有多个线程,客户端如何管理多个线程的消息拉取
消费者拉取到消息后,offset定时提交到ZK,那么什么时候会读取offset:发生rebalance后
[1],拉取消息之前
[2]
第六章 协调者
消费组状态机
我们先假设初始时世界是混沌的还没有盘古的开天辟地,协调者也是一片荒芜人烟之地,没有保存任何状态,因为消费组的初始状态是Stable,在第一次的Rebalance时,正常的还没有向消费组注册过的消费者会执行状态为Stable而且
memberId=UNKNOWN_MEMBER_ID条件分支。在第一次Rebalance之后,每个消费者都分配到了一个成员编号,系统又会进入Stable稳定状态(Stable稳定状态包括两种:一种是没有任何消费者的稳定状态,一种是有消费者的稳定状态)。因为所有消费者在执行一次JoinGroup后并不是说系统就一直保持这种不变的状态,有可能因为这样或那样的事件导致消费者要重新进行JoinGroup,这个时候因为之前JoinGroup过了每个消费者都是有成员编号的,处理方式肯定是不一样的。
所以定义一种事件驱动的状态机就很有必要了,这世界看起来是杂乱无章的,不过只要遵循着状态机的规则(万物生长的理论),任何事件都是有迹可循有路可走有条不紊地进行着。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 2728 | private def doJoinGroup(group: GroupMetadata,memberId: String,clientId: String,
clientHost: String,sessionTimeoutMs: Int,protocolType: String,
protocols: List[(String, Array[Byte])],responseCallback: JoinCallback) {
if (group.protocolType!=protocolType||!group.supportsProtocols(protocols.map(_._1).toSet)) {
//protocolType对于消费者是consumer,注意这里的协议类型和PartitionAssignor协议不同哦
//协议类型目前总共就两种消费者和Worker,而协议是PartitionAssignor分配算法
responseCallback(joinError(memberId, Errors.INCONSISTENT_GROUP_PROTOCOL.code))
} else if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID && !group.has(memberId)) {
//如果当前组没有记录该消费者,而该消费者却被分配了成员编号,则重置为未知成员,并让消费者重试
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code))
} else { group.currentState match {
case Dead =>
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code))
case PreparingRebalance =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) { //2.第二个消费者在这里了!
addMemberAndRebalance(sessionTimeoutMs, clientId, clientHost,
protocols, group, responseCallback)
} else {
val member = group.get(memberId)
updateMemberAndRebalance(group, member, protocols, responseCallback)
}
case Stable =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) { //1.初始时第一个消费者在这里!
//如果消费者成员编号是未知的,则向GroupMetadata注册并被记录下来
addMemberAndRebalance(sessionTimeoutMs, clientId, clientHost,
protocols, group, responseCallback)
} else { //3.第二次Rebalance时第一个消费者在这里,此时要分Leader还是普通的消费者了
val member = group.get(memberId)
if (memberId == group.leaderId || !member.matches(protocols)) {
updateMemberAndRebalance(group, member, protocols, responseCallback)
} else {
responseCallback(JoinGroupResult(members = Map.empty,memberId = memberId,
generationId = group.generationId,subProtocol = group.protocol,
leaderId = group.leaderId,errorCode = Errors.NONE.code))
}
}
}
if (group.is(PreparingRebalance))
joinPurgatory.checkAndComplete(GroupKey(group.groupId))
}
} |
prepareRebalance,消费组中只有一个消费者有机会调用prepareRebalance,并且一旦调用该方法,会将消费组状态更改为
PreparingRebalance,就会使得下一个消费者只能从
case PreparingRebalance入口进去了,假设第一个消费者是从Stable进入的,它更改了状态为PreparingRebalance,下一个消费者就不会从Stable进来的。不过进入Stable状态还要判断消费者是不是已经有了成员编号,通常是之前已经发生了Rebalance,这种影响也是比较巨大的,每个消费者走的路径跟第一次的Rebalance是完全不同的迷宫地图了。
1)第一次Rebalance如图6-18的上半部分:
第一个消费者,状态为Stable,没有编号,addMemberAndRebalance,成为Leader,执行prepareRebalance,更改状态为PreparingRebalance,创建DelayedJoin
第二个消费者,状态为PreparingRebalance,没有编号,addMemberAndRebalance(不执行prepareRebalance,因为在状态改变成PreparingRebalance后就不会被执行了);后面的消费者同第二个
所有消费者都要等协调者收集完所有成员编号在DelayedJoin完成时才会收到JoinGroup响应
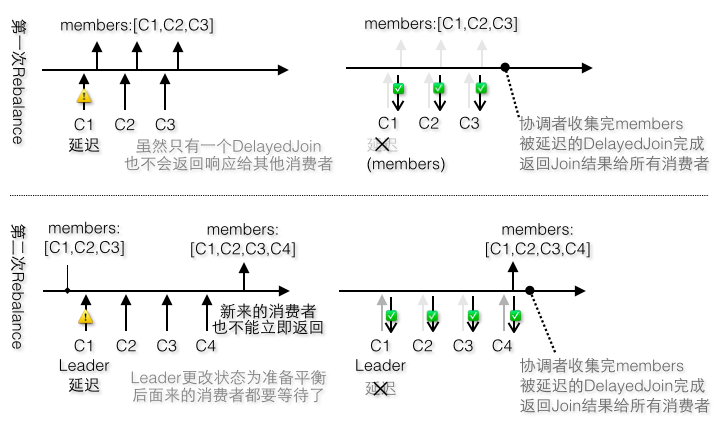
图6-18 第一次和第二次Rebalance
2)第二次Rebalance,对于之前加入过的消费者都要成员编号如图6-18的下半部分:
第一个消费者是Leader,状态为Stable,有编号,updateMemberAndRebalance,更改状态为PreparingRebalance,创建DelayedJoin
第二个消费者,状态为PreparingRebalance,有编号,updateMemberAndRebalance;后面的消费者同第二个
所有消费者也要等待,因为其他消费者发送Join请求在Leader消费者之后。
3)不过如果有消费者在Leader之前发送又有点不一样了如图6-19:
第一个消费者不是Leader,状态为Stable,有编号,responseCallback,立即收到JoinGroup响应,好幸运啊!
第二个消费者如果也不是Leader,恭喜你,协调者也放过他,直接返回JoinGroup响应
第三个消费者是Leader(领导来了),状态为Stable(什么,你们之前的消费者竟然都没更新状态!,因为他们都没有add或update),有编号,updateMemberAndRebalance(还是我第一个调用add或update,看来还是只能我来更新状态),更改状态为PreparingRebalance,创建DelayedJoin
第四个消费者不是Leader,状态为PreparingRebalance,有编号,updateMemberAndRebalance(前面有领导,不好意思了,不能立即返回JoinGroup给你了,你们这些剩下的消费者都只能和领导一起返回了,算你们倒霉)
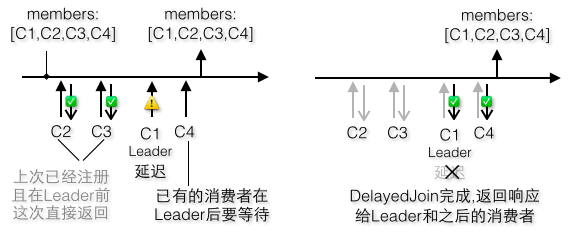
图6-19 Leader非第一个发送JoinGroup请求
4)如果第一个消费者不是Leader,也没有编号,说明这是一个新增的消费者,流程又不同了如图6-20:
第一个消费者不是Leader,状态为Stable,没有编号,addMemberAndRebalance,执行prepareRebalance(我是第一个调用add或update的哦,你们都别想跟我抢这个头彩了),更改状态为PreparingRebalance(我不是Leader但我骄傲啊),创建DelayedJoin(我抢到头彩,当然创建DelayedJoin的工作只能由我来完成了)
第二个消费者也不是Leader,恭喜你,协调者也放过他,直接返回JoinGroup响应
第三个消费者是Leader(领导来了),状态为PreparingRebalance(有个新来的不懂规矩,他已经把状态改了),有编号,updateMemberAndRebalance(有人已经改了,你老就不用费心思了),凡是没有立即返回响应的,都需要等待,领导也不例外
第四个消费者不是Leader(废话,只有一个领导,而且领导已经在前面了),不会立即返回响应(你看领导都排队呢)
虽然DelayedJoin是由没有编号的消费者创建,不过由于DelayedJoin是以消费组为级别的,所以不用担心,上一次选举出来的领导还是领导,协调者最终还是会把members交给领导,不会是给那个没有编号的消费者的,虽然说在他注册的时候已经有编号了,但是大家不认啊。不过领导其实不在意是谁开始触发prepareRebalance的,那个人要负责生成DelayedJoin,而不管是领导自己还是其他人一旦更改状态为PreparingRebalance,后面的消费者都要等待DelayedJoin完成了,而领导者总是要等待的,所以他当然无所谓了,因为他知道最后协调者总是会把members交给他的。

图6-20 新增消费组第一个发送JoinGroup请求
根据上面的几种场景总结下来状态机的规则和一些结论如下:
第一个调用addMemberAndRebalance或者updateMemberAndRebalance的会将状态改为PreparingRebalance,并且负责生成DelayedJoin
一旦状态进入PreparingRebalance,其他消费者就只能从PreparingRebalance状态入口进入,这里只有两种选择addMemberAndRebalance或者updateMemberAndRebalance,不过他们不会更改状态,也不会生成DelayedJoin
发生DelayedJoin之后,其他消费者的JoinGroup响应都会被延迟,因为如规则2中,他们只能调用add或update,无法立即调用responseCallback,所以就要和DelayedJoin的那个消费者一起等待
正常流程时,发生responseCallback的是存在成员编号的消费者在Leader之前发送了JoinGroup,或者新增加的消费者发送了JoinGroup请求之前
第一次Rebalance时,第一个消费者会创建DelayedJoin,之后的Rebalance,只有新增的消费者才有机会创建(如果他在Leader之前发送的话,如果在Leader之后就没有机会了),而普通消费者总是没有机会创建DelayedJoin的,因为状态为Stable时,他会直接开溜,有人(Leader或者新增加的消费者)创建了DelayedJoin之后,他又在那边怨天尤人只能等待

相关文章推荐
- sublime text2 中标签高亮效果BracketHighlighter插件
- jhash的C++实现
- jhash的C++实现
- jhash的C++实现
- jhash的C++实现
- jhash的C++实现
- poj 2828--Buy Tickets(线段树)
- jhash的C++实现
- LeetCode之后序迭代遍历
- RedHat linux配置yum本地资源
- 欢迎使用CSDN-markdown编辑器
- 交换两个变量的值,不使用第三个变量的四种方法
- JQueryUi模糊搜索
- 关于WMWare WorkStation 12 共享目录的设置
- 数据类型
- python对文件的读取
- cocosapods pod install 报错
- 包含min函数的栈
- css背景图片在chrome下正常,IE下不显示
- 51Nod 编辑距离 DP+滚动数组